







The problem is:
Selecting best pruned tree from CCP with Cross-validation
--------------------------------------------------------------------------------------------
Professor Ricco RAKOTOMALALA’s lecture[1] has described Cart-CCP process clearly.
And I have implemented it in my Github[2]:
What [1] have described :
is:
67% of all data,for growing a CART tree and get a sequence of pruned tree.
33% of all data,for selecting the best pruned tree.
This is only for when the data is large enough.
-------------------------------------------------
according to[3]
(This author is not in this world any longer,so I can NOT contact him),
Two methods of estimation are discussed:
Use of an independent test
sample and cross-validation.
Of the two, use of an independent test sample
is computationally more efficient and is preferred
when the learning sample contains a large number of cases.
As a useful by-product it gives relatively unbiased estimates of the node misclassification costs. **Cross-validation is
computationally more expensive,
but makes more effective use of all cases and gives useful**
information regarding the stability of the tree structure.
So,there’s the second way to choose the best pruned tree:cross-validation.I mean :
The difficuly lies in selecting best pruned tree with cross-validation,
NOT in Pruning algorithm.
-----------almost all material about CCP in Google-------------
in[4],is said in page 19th:
It is important to note that in the procedure described here we are effectively
using cross-validation to select the best value of the complexity parameter from
the set β1, . . . , βK. Once the best value has been determined, the corresponding
tree from the original cost-complexity sequence is returned.
no details about how to select.
in[5],mlwikipedia only talk about the same method as [2].
in[6],no validation about selecting is in discussion
in[7],IBM files don’t discuss how to use cross-validation to select the best-tree.
in[8],no details about how to select with cross-validation
(I have contacted the author,but no reply).
Here’s a picture about cross-validation after CCP,but no details.
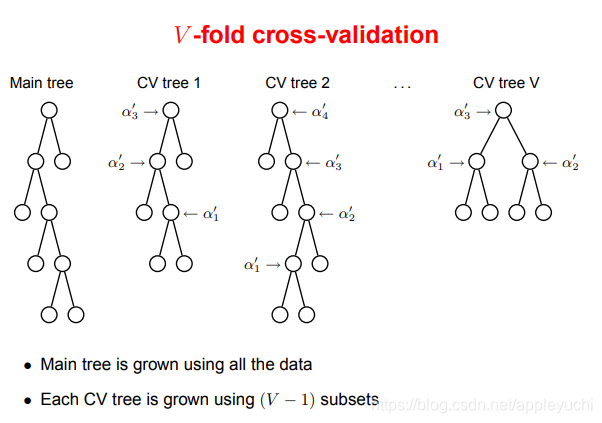
The goal of Cross-validation is:
Estimation of the prediction error(or MSE)of the trees in sequenceMain(use all the data) with the sequenceV:(remove the vth fold data before growing Tv1)
For main tree,we have pruned tree sequenceMain
[
T
1
T_1
T1,
T
2
T_2
T2,
T
3
T_3
T3,
T
4
T_4
T4]
For CV tree V,we have pruned tree sequenceV:
[
T
v
1
T_{v1}
Tv1,
T
v
2
T_{v2}
Tv2,
T
v
3
T_{v3}
Tv3,Tv4 ]
(because only 3 decision nodes,so it can only be pruned twice )
Then how could I estimate error rate of
T
4
T_4
T4 in sequenceMain when no
T
v
4
T_{v4}
Tv4 in SequenceV?
In[3] part3.4.2,the formula to estimate
T
k
T_k
Tkis:
R
c
v
(
T
k
)
=
R
c
v
(
T
(
a
k
′
)
)
R^{cv}(T_k)=R^{cv}(T(a_k^{'}))
Rcv(Tk)=Rcv(T(ak′)),
now in SequenceV,
T
v
4
(
=
T
(
a
4
′
)
)
T_{v4}(=T(a_4^{'}))
Tv4(=T(a4′)) does not exist ,
how to estimate
R
c
v
(
T
4
)
R^{cv}(T_4)
Rcv(T4) in sequenceMain via the above equation ?
The other reference about CCP were:
in[9],only pruning algorithm ,no details about how to select the best pruned tree.
in[10]page 110th:" There is no theoretical justification for
this heuristic tree-matching process as it was mentioned by Esposito et al. (1997)."
Quotation of[10] means that:
sequenceMain and sequenceV can NOT be matched,no matter in shape of pruned-tree or in the length of sequence.
------------------------------------------------------------------------------------------
So,selecting the best pruned tree(from CCP) with cross-validation is NOT rigrous in theory,it has limitations,it is available only in large and balalanced datasets which can ensure:
For different
L
v
L_v
Lv,it can produces similar tress.
Reference:
[1]Decision tree learning algorithms
[2]https://github.com/appleyuchi/Decision_Tree_Prune
[3]《Classification and regresssion trees》“Chapter 3.4 THE BEST PRUNED SUBTREE: AN ESTIMATION PROBLEM”
[4]http://www.cs.uu.nl/docs/vakken/mdm/trees.pdf
[5]Cost-Complexity Pruning
[6]https://onlinecourses.science.psu.edu/stat857/node/60/
[7]Cost-Complexity Pruning Process-IBM
[8]Classification and Regression Trees
[9]Lecture 19: Decision trees
[10]Chapter4 Overfitting Avoidance in Regression Trees
---------------------appendix--------------------------------------
Why
a
k
′
=
a
k
a
k
+
1
a_k^{'}=\sqrt{a_ka_{k+1}}
ak′=akak+1 in CCP and ECP?
Because the final best pruned tree is built based on all the data,the real cost complexity will larger than
a
k
a_k
ak,we need to give it a modification,so we use
a
k
=
a
k
a
k
+
1
a_k=\sqrt{a_ka_{k+1}}
ak=akak+1,but it’s of course not rigorously modified,just by experience.














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









