






用简单几句话概括hbase集群宕机原因
主要原因:
-
hbase集群索引表数据量增多了,负荷变大了,引入功能变多了,但是项目配置参数没有随之调整
-
开源项目Phoenix中,对于少部分的修改索引表状态失败的场景,默认的处理方式比较简单粗暴,在一些特殊情况下,容易出现问题
简单流程概括宕机过程
-
有索引表的region正在分裂,分裂期间region不接受任何请求
-
业务应用请求写索引表失败,重试后仍然失败,于是将索引表禁用
-
同时存在其它线程尝试修改索引表状态,但是索引状态修改失败
-
索引状态修改失败后regionserver自动关闭
-
同时存在其它regionserver正在请求宕机的regionserver写索引表,最后写索引失败,regionser自动关闭,并引起雪崩
-
宕机重现的必要条件
-
hbase整合了Phoenix框架
-
发生region分裂,且分裂导致region不在线的时间要足够长
-
不在线的region属于Phoenix索引表的region
-
Phoenix索引region下线的瞬间,Phoenix对该region并发修改请求qps要够高
-
客户端的重试次数要少,并且重试间隔要足够短
最终解决办法:
将hbase.client.retries.number从项目中配置的3改为7(默认为15),问题就不在出现了
根据时间的先后顺序,推测3月21号hbase集群发生的挂机经过
注:部分图片可能涉及生产隐私,因此我删除了
2021年7月16日
业务应用修改了hbase客户端配置
hbase.client.retries.number(客户端重试次数)
由默认的15次修改为3次

2022-04-23 15:27:03,823
从master日志看出,索引表IDX_COUPON_END_TIME大小到达了分裂阀值
master正在对该表进行分裂操作,分裂行为持续到2022-04-23 15:27:08,929,耗时5秒
region分裂时,所有落在该region上的请求都会报错NotServerRegionExecpion,但是由于有重试机制,所以一般业务无感知
由于容器重启后没有日志
因此后续假设下客户端的情况如下
在索引表IDX_COUPON_END_TIME分裂期间,
业务应用正在对表索引表发送修改请求
此时业务应用则会出现写索引异常,如下图(下图为测试环境重现问题截图,非生产环境,非项目业务应用)
因为业务应用项目配置了3次重试次数,因此业务应用会在
300毫秒后进行第二次重新发送写请求,该写请求会失败
500毫秒后进行第三次发送修改请求,该写请求会失败
源码位置如下

经过共计3次写索引失败后,业务应用项目会将失败的索引表设置为IDX_COUPON_END_TIME禁用DISABLE状态
源码位置如下

注意:由于项目是多节点项目,并且phoenix和hbase都是多线程多节点应用,并且所有应用的元数据都不是实时更新的,因此在索引表被禁用后,可能仍然新请求试图对IDX_COUPON_END_TIME进行写操作,这次写操作也会因为region正在分裂而失败
假设下客户端的情况如上所述,后续为生产hbase服务器日志分析
2022-04-23 15:27:06,651~2022-04-23 15:27:08,408
regionserver1写索引IDX_COUPON_END_TIME失败了,并且失败了3次,原因为无法定位region位置。
此时在客户端这边,可能已经在尝试将索引表IDX_COUPON_END_TIME修改为DISABLE状态
2022-04-23 15:27:08,402
从日志看出,regionserver5正在试图定位一个region所在位置,但是失败了
根据后续日志可做如下推测由于region定位失败了,所以写索引表IDX_COUPON_END_TIME失败了
从源码可以看出,当regionserver写索引失败后,regionserver会尝试将索引表状态更新为PENDING_DISABLE(预禁用)


2022-04-23 15:27:08,729
从日志可以看出,regionserver5修改索引状态失败了,原因是UNALLOWED_TABLE_MUTATION(非法的表操作)
从源码看出,UNALLOWED_TABLE_MUTATION(非法的表操作)可能的原因:此时表已经为DISABLE (已禁用)状态,不能把DISABLE状态的表转化为PENDING_DISABLE(预禁用)

从源码可以看出,当修改索引失败后最终会向外抛出DoNotRetryIOException异常
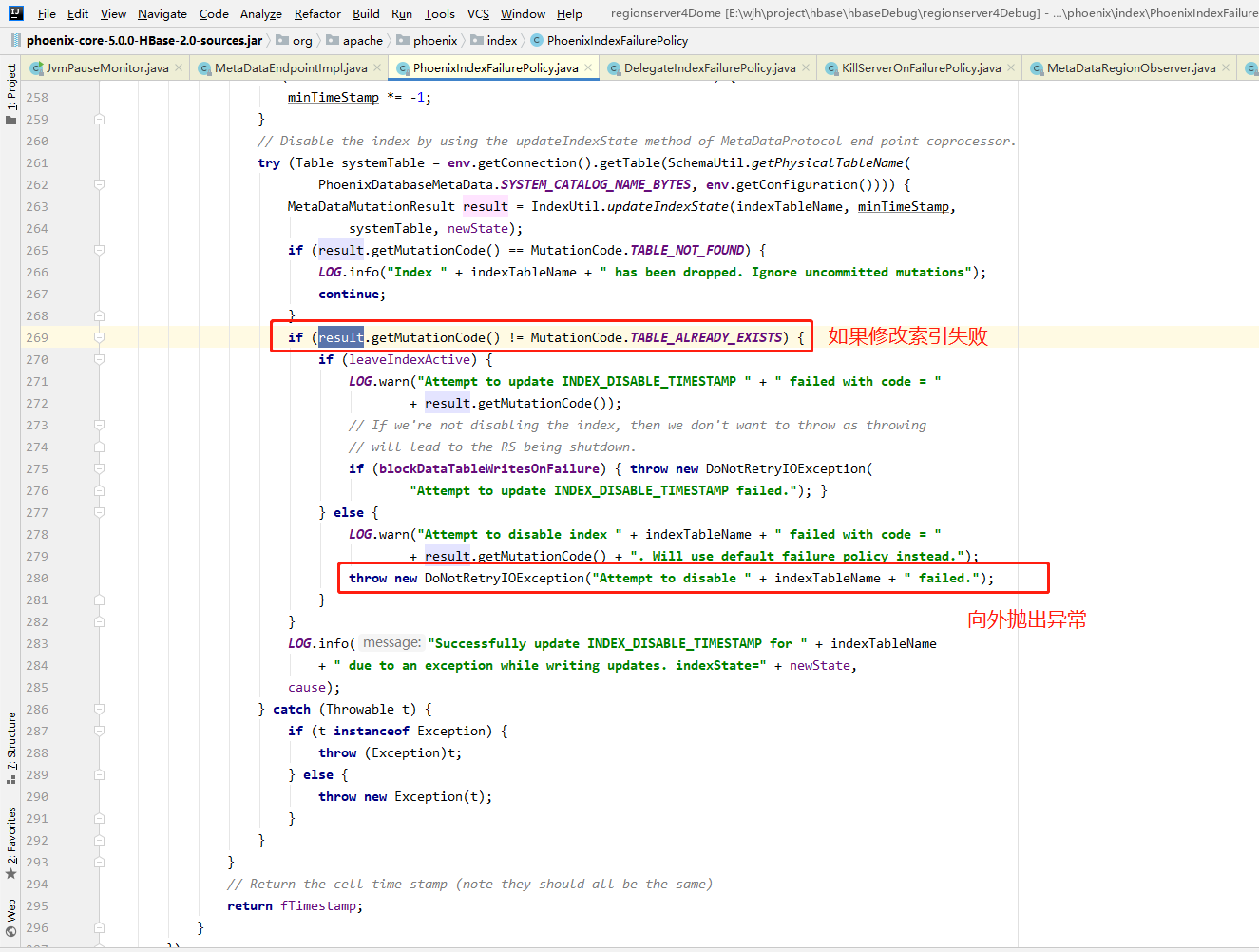
DoNotRetryIOException会被包装为FatalIndexBuildingFailureException(致命索引构建异常)

2022-04-23 15:27:08,755
regionserver5的Phoenix程序向外抛出了FatalIndexBuildingFailureException(致命索引构建异常)

2022-04-23 15:27:08,847
regionserver5停止运行
2022-04-23 15:27:12,928
regionserver3
因为无法联系regionserver5写索引失败最终关闭了自己
2022-04-23 15:27:13,098
regionserver7
因为无法连接regionserver5导致写索引失败,最后关闭
2022-04-23 15:27:27,262
regionserver2因为无法连接regionserver5导致写索引失败最后挂掉
2022-04-23 15:27:27,438
regionserver8:
因为无法连接regionserver3和regionserver7导致写索引失败宕机
2022-04-23 15:27:27,342
regionserver1:
由日志得,regionserver1无法连接regionserver7和regionservre3,最终写索引失败关闭了自己
2022-04-23 15:27:38,384
regionserver6
由日志得,regionserver6无法连接regionservre3,热感ionserver7,regionserver8最终写索引失败关闭了自己
2022-04-23 15:27:38,962
regionserver4
由日志得,regaie3,最终写索引失败关闭了自己
至此。hbase集群的所有regionserver均已关闭
最终解决办法:
由上面可知,宕机有下面几个必要条件
-
hbase整合了Phoenix框架
-
发生region分裂,且分裂导致region不在线的时间要足够长
-
不在线的region属于Phoenix索引表的region
-
Phoenix索引region下线的瞬间,对该region并发修改请求qps要够高
-
客户端的重试次数要少,并且重试间隔要足够短
将hbase.client.retries.number从项目中配置的3改为7(默认为15),问题就不在出现了
将业务项目重试次数从3增加为7,即可增加重试次数和重试间隔,少了一个必要条件,宕机就不会发生
(注:若项目无特殊指定。hbase默认该参数为15)
常见问题:为什么重试次数应该调整为7而不是其它数字?
在hbase已经不正常的情况下,重试次数为3,客户端的Phoenix写索引表请求情况如下所示
第1次写索引失败
Thread.sleep毫秒:300
第2次写索引失败
Thread.sleep毫秒:500
第3次写索引失败
结束
在hbase已经不正常的情况下,若配置重试次数为7,则为
第1次写索引失败
Thread.sleep毫秒:300
第2次写索引失败
Thread.sleep毫秒:500
第3次写索引失败
Thread.sleep毫秒:1000
第4次写索引失败
Thread.sleep毫秒:2000
第5次写索引失败
Thread.sleep毫秒:4000
第6次写索引失败
Thread.sleep毫秒:10000
第7次写索引失败
结束
在hbase已经不正常的情况下,若配置重试次数为15,则为
第1次写索引失败
Thread.sleep毫秒:300
第2次写索引失败
Thread.sleep毫秒:500
第3次写索引失败
Thread.sleep毫秒:1000
第4次写索引失败
Thread.sleep毫秒:2000
第5次写索引失败
Thread.sleep毫秒:4000
第6次写索引失败
Thread.sleep毫秒:10000
第7次写索引失败
Thread.sleep毫秒:10000
第8次写索引失败
Thread.sleep毫秒:10000
第9次写索引失败
Thread.sleep毫秒:10000
第10次写索引失败
Thread.sleep毫秒:20000
第11次写索引失败
Thread.sleep毫秒:20000
第12次写索引失败
Thread.sleep毫秒:20000
第13次写索引失败
Thread.sleep毫秒:20000
第14次写索引失败
Thread.sleep毫秒:20000
第15次写索引失败
结束
通过观察region分裂时间有下面规律
集群正常时2秒左右完成分裂
系统繁忙时可以到10秒
系统异常时可以到30秒
综合考虑,可暂时把重试次数改为7
源码位置
















 5024
5024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









