








http://imbinwang.github.io/blog/inside-caffe-code-layer/
Bin Wang
About Archive
Jun 30, 2015
8 minute read
Layer(层)是Caffe中最庞大最繁杂的模块,它是网络的基本计算单元。由于Caffe强调模块化设计,因此只允许每个layer完成一类特定的计算,例如convolution操作、pooling、非线性变换、内积运算,以及数据加载、归一化和损失计算等。
模块说明
每个layer的输入数据来自一些’bottom’ blobs, 输出一些’top’ blobs。Caffe中每种类型layer的参数说明定义在caffe.proto文件中,具体的layer参数值则定义在具体应用的protocals buffer网络结构说明文件中。例如,卷积层(ConvolutionLayer)的参数说明在caffe.proto中是如下定义的,
// in caffe.proto
// Message that stores parameters used by ConvolutionLayer
message ConvolutionParameter {
optional uint32 num_output = 1; // The number of outputs for the layer
optional bool bias_term = 2 [default = true]; // whether to have bias terms
// Pad, kernel size, and stride are all given as a single value for equal
// dimensions in height and width or as Y, X pairs.
optional uint32 pad = 3 [default = 0]; // The padding size (equal in Y, X)
optional uint32 pad_h = 9 [default = 0]; // The padding height
optional uint32 pad_w = 10 [default = 0]; // The padding width
optional uint32 kernel_size = 4; // The kernel size (square)
optional uint32 kernel_h = 11; // The kernel height
optional uint32 kernel_w = 12; // The kernel width
optional uint32 group = 5 [default = 1]; // The group size for group conv
optional uint32 stride = 6 [default = 1]; // The stride (equal in Y, X)
optional uint32 stride_h = 13; // The stride height
optional uint32 stride_w = 14; // The stride width
optional FillerParameter weight_filler = 7; // The filler for the weight
optional FillerParameter bias_filler = 8; // The filler for the bias
enum Engine {
DEFAULT = 0;
CAFFE = 1;
CUDNN = 2;
}
optional Engine engine = 15 [default = DEFAULT];
}其中的参数说明包括卷积核的个数、大小和步长等。在examples\mnist\lenet_train_test.prototxt网络结构说明文件中,具体一个卷积层(ConvolutionLayer)是这样定义的,
//in examples\mnist\lenet_train_test.prototxt
layer {
name: "conv1" // 层的名字
type: "Convolution" // 层的类型,说明具体执行哪一种计算
bottom: "data" // 层的输入数据Blob的名字
top: "conv1" // 层的输出数据Blob的名字
param { // 层的权值和偏置相关参数
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param { // 卷积层卷积运算相关的参数
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}层的输入输出结构:
bottom blob -> conv layer -> top blob
每种类型的layer需要定义三种关键操作LayerSetUp, Forward, Backward:
LayerSetUp: 网络构建时初始化层和层的连接
Forward: 网络数据前向传递,给定bottom输入数据,计算输出到top
Backward: 网络误差反向传递,给定top的梯度,计算bottom的梯度并存储到bottom blob
实现细节
Caffe中与Layer相关的头文件有7个,
layer.hpp: 父类Layer,定义所有layer的基本接口。
data_layers.hpp: 继承自父类Layer,定义与输入数据操作相关的子Layer,例如DataLayer,HDF5DataLayer和ImageDataLayer等。
vision_layers.hpp: 继承自父类Layer,定义与特征表达相关的子Layer,例如ConvolutionLayer,PoolingLayer和LRNLayer等。
neuron_layers.hpp: 继承自父类Layer,定义与非线性变换相关的子Layer,例如ReLULayer,TanHLayer和SigmoidLayer等。
loss_layers.hpp: 继承自父类Layer,定义与输出误差计算相关的子Layer,例如EuclideanLossLayer,SoftmaxWithLossLayer和HingeLossLayer等。
common_layers.hpp: 继承自父类Layer,定义与中间结果数据变形、逐元素操作相关的子Layer,例如ConcatLayer,InnerProductLayer和SoftmaxLayer等。
layer_factory.hpp: Layer工厂模式类,负责维护现有可用layer和相应layer构造方法的映射表。
每个Layer根据自身需求的不同,会定义CPU或GPU版本的实现,例如ConvolutionLayer的CPU和GPU实现就定义在了两个文件中conv_layer.cpp, conv_layer.cu。
父类Layer
layer.hpp中定义了Layer的基本接口,成员变量,
protected:
/** The protobuf that stores the layer parameters */
// 层说明参数,从protocal buffers格式的网络结构说明文件中读取
LayerParameter layer_param_;
/** The phase: TRAIN or TEST */
// 层状态,参与网络的训练还是测试
Phase phase_;
/** The vector that stores the learnable parameters as a set of blobs. */
// 层权值和偏置参数,使用向量是因为权值参数和偏置是分开保存在两个blob中的
vector<shared_ptr<Blob<Dtype> > > blobs_;
/** Vector indicating whether to compute the diff of each param blob. */
// 标志每个top blob是否需要计算反向传递的梯度值
vector<bool> param_propagate_down_;
/** The vector that indicates whether each top blob has a non-zero weight in
* the objective function. */
// 非LossLayer为零,LossLayer中表示每个top blob计算的loss的权重
vector<Dtype> loss_;构造和析构函数,
/**
* You should not implement your own constructor. Any set up code should go
* to SetUp(), where the dimensions of the bottom blobs are provided to the
* layer.
*/
// 显示的构造函数不需要重写,任何初始工作在SetUp()中完成
// 构造方法只复制层参数说明的值,如果层说明参数中提供了权值和偏置参数,也复制
explicit Layer(const LayerParameter& param)
: layer_param_(param) {
// Set phase and copy blobs (if there are any).
phase_ = param.phase();
if (layer_param_.blobs_size() > 0) {
blobs_.resize(layer_param_.blobs_size());
for (int i = 0; i < layer_param_.blobs_size(); ++i) {
blobs_[i].reset(new Blob<Dtype>());
blobs_[i]->FromProto(layer_param_.blobs(i));
}
}
}
// 虚析构
virtual ~Layer() {}初始化函数SetUp,每个Layer对象都必须遵循固定的调用模式,
/**
* @brief Implements common layer setup functionality.
* @brief 实现每个layer对象的setup函数
* @param bottom the preshaped input blobs
* @param bottom 层的输入数据,blob中的存储空间已申请
* @param top
* the allocated but unshaped output blobs, to be shaped by Reshape
* @param top 层的输出数据,blob对象以构造但是其中的存储空间未申请,
* 具体空间大小需根据bottom blob大小和layer_param_共同决定,具体在Reshape函数现实
*
* Checks that the number of bottom and top blobs is correct.
* Calls LayerSetUp to do special layer setup for individual layer types,
* followed by Reshape to set up sizes of top blobs and internal buffers.
* Sets up the loss weight multiplier blobs for any non-zero loss weights.
* This method may not be overridden.
* 1. 检查输入输出blob个数是否满足要求,每个层能处理的输入输出数据不一样
* 2. 调用LayerSetUp函数初始化特殊的层,每个Layer子类需重写这个函数完成定制的初始化
* 3. 调用Reshape函数为top blob分配合适大小的存储空间
* 4. 为每个top blob设置损失权重乘子,非LossLayer为的top blob其值为零
*
* 此方法非虚函数,不用重写,模式固定
*/
void SetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
CheckBlobCounts(bottom, top);
LayerSetUp(bottom, top);
Reshape(bottom, top);
SetLossWeights(top);
}每个子类Layer必须重写的初始化函数LayerSetUp,
/**
* @brief Does layer-specific setup: your layer should implement this function
* as well as Reshape.
* @brief 定制初始化,每个子类layer必须实现此虚函数
*
* @param bottom
* the preshaped input blobs, whose data fields store the input data for
* this layer
* @param bottom
* 输入blob, 数据成员data_和diff_存储了相关数据
* @param top
* the allocated but unshaped output blobs
* @param top
* 输出blob, blob对象已构造但数据成员的空间尚未申请
*
* This method should do one-time layer specific setup. This includes reading
* and processing relevent parameters from the <code>layer_param_</code>.
* Setting up the shapes of top blobs and internal buffers should be done in
* <code>Reshape</code>, which will be called before the forward pass to
* adjust the top blob sizes.
* 此方法执行一次定制化的层初始化,包括从layer_param_读入并处理相关的层权值和偏置参数,
* 调用Reshape函数申请top blob的存储空间
*/
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {}每个子类Layer必须重写的Reshape函数,完成top blob形状的设置并为其分配存储空间,
/**
* @brief Adjust the shapes of top blobs and internal buffers to accomodate
* the shapes of the bottom blobs.
* @brief 根据bottom blob的形状和layer_param_计算top blob的形状并为其分配存储空间
*
* @param bottom the input blobs, with the requested input shapes
* @param top the top blobs, which should be reshaped as needed
*
* This method should reshape top blobs as needed according to the shapes
* of the bottom (input) blobs, as well as reshaping any internal buffers
* and making any other necessary adjustments so that the layer can
* accomodate the bottom blobs.
*/
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) = 0;前向传播函数Forward和反向传播函数Backward,
inline Dtype Forward(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
inline void Backward(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom);这两个函数非虚函数,它们内部会调用如下虚函数完成数据前向传递和误差反向传播,根据执行环境的不同每个子类Layer必须重写CPU和GPU版本,
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) = 0;
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// LOG(WARNING) << "Using CPU code as backup.";
return Forward_cpu(bottom, top);
}
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) = 0;
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
// LOG(WARNING) << "Using CPU code as backup.";
Backward_cpu(top, propagate_down, bottom);
}Layer的序列化函数,将layer的层说明参数layer_param_,层权值和偏置参数blobs_复制到LayerParameter对象,便于写到磁盘,
// Serialize LayerParameter to protocol buffer
template <typename Dtype>
void Layer<Dtype>::ToProto(LayerParameter* param, bool write_diff) {
param->Clear();
param->CopyFrom(layer_param_); // 复制层说明参数layer_param_
param->clear_blobs();
// 复制层权值和偏置参数blobs_
for (int i = 0; i < blobs_.size(); ++i) {
blobs_[i]->ToProto(param->add_blobs(), write_diff);
}
}子类Data Layers
数据经过date layers进入Caffe的数据处理流程,他们位于网络Net最底层。数据可以来自高效的数据库(LevelDB或LMDB),直接来自内存,或者对效率不太关注时,可以来自HDF5格式的或常见图片格式的磁盘文件。Data Layers继承自Layer,
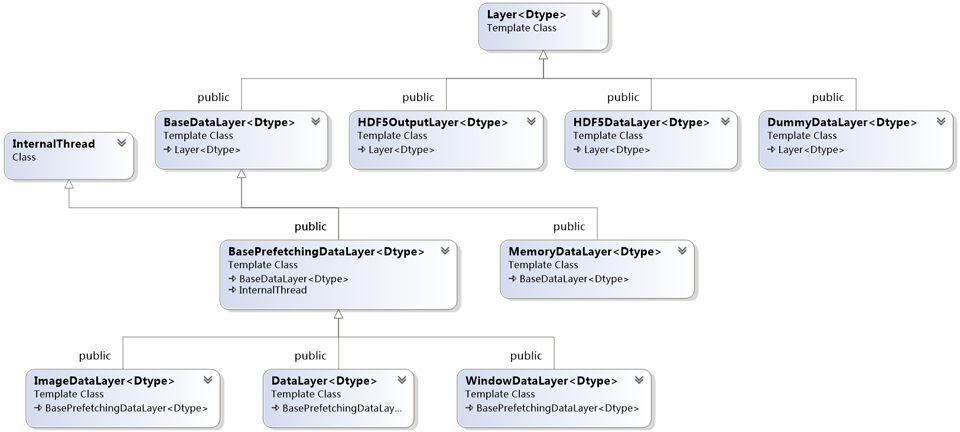
最终的子类层包括DataLayer,ImageDataLayer,WindowDataLayer,MemoryDataLayer,HDF5DataLayer,HDF5OutputLayer,DummyDataLayer。这里只分析DataLayer,其它数据层类似。
首先,来看DataLayer的LayerSetUp实现过程,DataLayer直接从父类BasePrefetchingDataLayer继承此方法,
// in base_data_layer.cpp
template <typename Dtype>
void BasePrefetchingDataLayer<Dtype>::LayerSetUp(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
// 1. 调用父父类BaseDataLayer构造方法,
BaseDataLayer<Dtype>::LayerSetUp(bottom, top);
// Now, start the prefetch thread. Before calling prefetch, we make two
// cpu_data calls so that the prefetch thread does not accidentally make
// simultaneous cudaMalloc calls when the main thread is running. In some
// GPUs this seems to cause failures if we do not so.
// 2. 访问预取数据空间,这里是为了提前分配预取数据的存储空间
this->prefetch_data_.mutable_cpu_data();
if (this->output_labels_) {
this->prefetch_label_.mutable_cpu_data();
}
// 3. 创建用于预取数据的线程
DLOG(INFO) << "Initializing prefetch";
this->CreatePrefetchThread();
DLOG(INFO) << "Prefetch initialized.";
}执行流程大致为:
1.调用父父类BaseDataLayer构造方法,
// in base_data_layer.cpp
template <typename Dtype>
void BaseDataLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
if (top.size() == 1) {
output_labels_ = false;
} else {
output_labels_ = true;
}
// The subclasses should setup the size of bottom and top
DataLayerSetUp(bottom, top);
data_transformer_.reset(
new DataTransformer<Dtype>(transform_param_, this->phase_));
data_transformer_->InitRand();
}根据top blob的个数判断是否输出数据的label,对output_labels_赋值,接下来调用自己的DataLayerSetUp方法,
// in data_layer.cpp
template <typename Dtype>
void DataLayer<Dtype>::DataLayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// Initialize DB
// 打开源数据库
db_.reset(db::GetDB(this->layer_param_.data_param().backend()));
db_->Open(this->layer_param_.data_param().source(), db::READ);
cursor_.reset(db_->NewCursor());
// Check if we should randomly skip a few data points
if (this->layer_param_.data_param().rand_skip()) {
unsigned int skip = caffe_rng_rand() %
this->layer_param_.data_param().rand_skip();
LOG(INFO) << "Skipping first " << skip << " data points.";
while (skip-- > 0) {
cursor_->Next();
}
}
// Read a data point, and use it to initialize the top blob.
// 读取一个数据对象, 用于分析数据对象的存储空间大小,并未输出到top blob
Datum datum;
datum.ParseFromString(cursor_->value());
bool force_color = this->layer_param_.data_param().force_encoded_color();
if ((force_color && DecodeDatum(&datum, true)) ||
DecodeDatumNative(&datum)) {
LOG(INFO) << "Decoding Datum";
}
// image
// 对数据对象进行预处理
int crop_size = this->layer_param_.transform_param().crop_size();
if (crop_size > 0) {
// 为top blob分配存储空间,同时为预取数据分配存储空间
top[0]->Reshape(this->layer_param_.data_param().batch_size(),
datum.channels(), crop_size, crop_size);
this->prefetch_data_.Reshape(this->layer_param_.data_param().batch_size(),
datum.channels(), crop_size, crop_size);
this->transformed_data_.Reshape(1, datum.channels(), crop_size, crop_size);
} else {
top[0]->Reshape(
this->layer_param_.data_param().batch_size(), datum.channels(),
datum.height(), datum.width());
this->prefetch_data_.Reshape(this->layer_param_.data_param().batch_size(),
datum.channels(), datum.height(), datum.width());
this->transformed_data_.Reshape(1, datum.channels(),
datum.height(), datum.width());
}
LOG(INFO) << "output data size: " << top[0]->num() << ","
<< top[0]->channels() << "," << top[0]->height() << ","
<< top[0]->width();
// label
if (this->output_labels_) {
vector<int> label_shape(1, this->layer_param_.data_param().batch_size());
top[1]->Reshape(label_shape);
this->prefetch_label_.Reshape(label_shape);
}
}打开数据源数据库,读取一个数据对象,对数据对象进行预处理,为top blob分配存储空间,同时为预取数据分配存储空间。
2.访问预取数据空间,为了提前分配预取数据的存储空间。
3.调用CreatePrefetchThread方法,创建用于预取数据的线程。
层初始化的工作完成。接下来看DataLayer的Forward实现过程,因为DataLayer位于网络最底层,因此无需实现Backward。DataLayer直接从父类BasePrefetchingDataLayer继承Forward方法,且只实现了CPU版本Forward_cpu,
// in base_data_layer.cpp
template <typename Dtype>
void BasePrefetchingDataLayer<Dtype>::Forward_cpu(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
// First, join the thread
// 等待线程的数据预取结束
JoinPrefetchThread();
DLOG(INFO) << "Thread joined";
// Reshape to loaded data.
top[0]->Reshape(this->prefetch_data_.num(), this->prefetch_data_.channels(),
this->prefetch_data_.height(), this->prefetch_data_.width());
// Copy the data
// 将预取的数据复制到top blobs
caffe_copy(prefetch_data_.count(), prefetch_data_.cpu_data(),
top[0]->mutable_cpu_data());
DLOG(INFO) << "Prefetch copied";
if (this->output_labels_) {
caffe_copy(prefetch_label_.count(), prefetch_label_.cpu_data(),
top[1]->mutable_cpu_data());
}
// Start a new prefetch thread
// 创建新线程完成数据预取
DLOG(INFO) << "CreatePrefetchThread";
CreatePrefetchThread();
}可以看到,DataLayer的Forward_cpu就是通过另一个线程预先取得数据源中的数据,需要时将预取的数据复制到top blobs,完成数据的前向传播。
P.S. 注意到在data_layer.cpp文件的最后,有下面两句宏函数,
INSTANTIATE_CLASS(DataLayer);
REGISTER_LAYER_CLASS(Data);它们被用来做什么了?看看它们的定义,
// ------ in common.hpp ------
// Instantiate a class with float and double specifications.
#define INSTANTIATE_CLASS(classname) \
char gInstantiationGuard##classname; \
template class classname<float>; \
template class classname<double>
// ------ in common.hpp ------
// ------ in layer_factory.hpp ------
#define REGISTER_LAYER_CREATOR(type, creator) \
static LayerRegisterer<float> g_creator_f_##type(#type, creator<float>); \
static LayerRegisterer<double> g_creator_d_##type(#type, creator<double>) \
#define REGISTER_LAYER_CLASS(type) \
template <typename Dtype> \
shared_ptr<Layer<Dtype> > Creator_##type##Layer(const LayerParameter& param) \
{ \
return shared_ptr<Layer<Dtype> >(new type##Layer<Dtype>(param)); \
} \
REGISTER_LAYER_CREATOR(type, Creator_##type##Layer)
// ------ in layer_factory.hpp ------其中,INSTANTIATE_CLASS(DataLayer)被用来实例化DataLayer的类模板,REGISTER_LAYER_CLASS(Data)被用来向layer_factory注册DataLayer的构造方法,方便直接通过层的名称(Data)直接获取层的对象。Caffe中内置的层在实现的码的最后都会加上这两个宏。
子类Vision Layers
Vision Layers, 暂时将其翻译成特征表达层,它通常接收“图像”作为输入,输出结果也是“图像”。这里的“图像”可以是真实世界的单通道灰度图像,或RGB彩色图像, 或多通道2D矩阵。在Caffe的上下文环境下,“图像”的显著性特征是它的空间结构:宽w>1,高h>1,这个2D的性质导致Vision Layers具有局部区域操作的性质,例如卷积,池化等。Vision Layers继承自也Layer,继承关系如图所示,
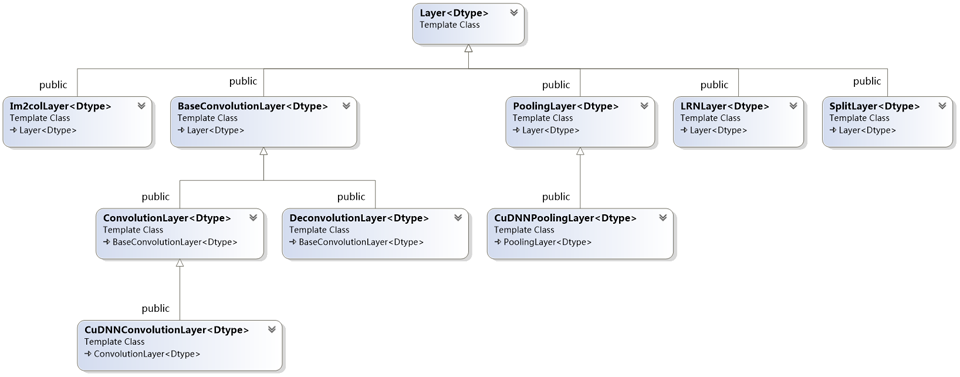
最终的子类层包括ConvolutionLayer,CuDNNConvolutionLayer,PoolingLayer,CuDNNPoolingLayer,LRNLayer,DeconvolutionLayer,还有若干辅助的功能子类层Im2colLayer,SplitLayer。这里会详细分析ConvolutionLayer。(待续)















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









