






1、关于office元数据,百度了一圈,资料比较散,最后找到了《MSOffice系列办公文档取证分析研究》这篇文章,和我找的资料相符,这里就引用一下这篇文章里涉及的内容。

2、xlsx文件的元数据比较简单,右键选择用压缩软件打开xlsx文件,在docProcs目录下可以找到core.xml文件
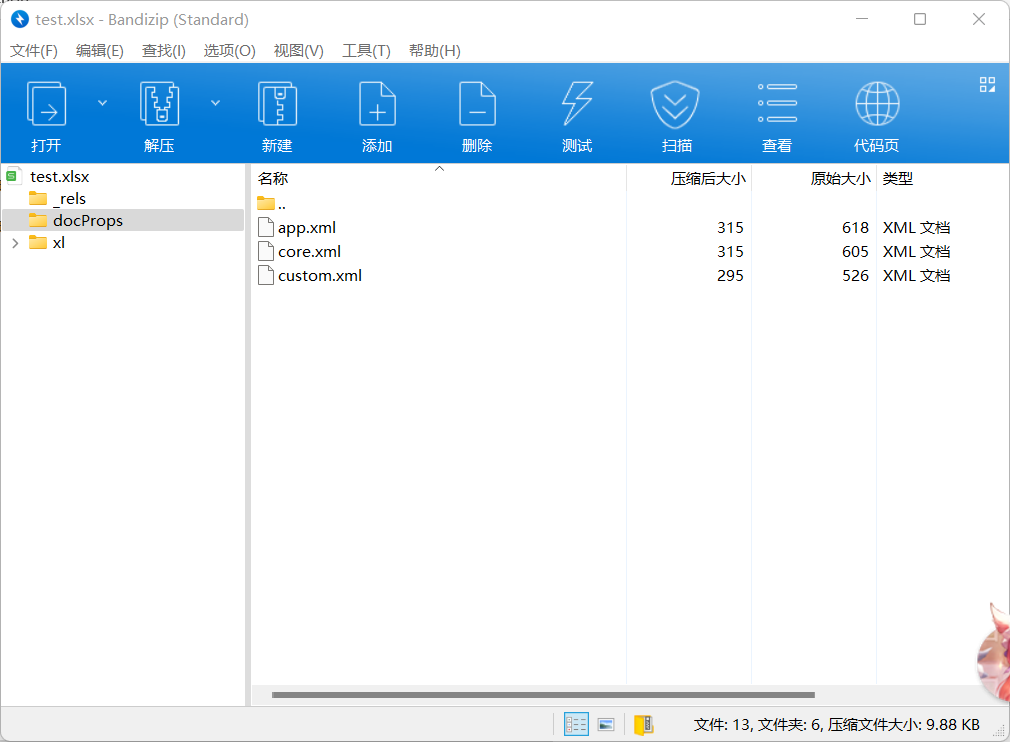
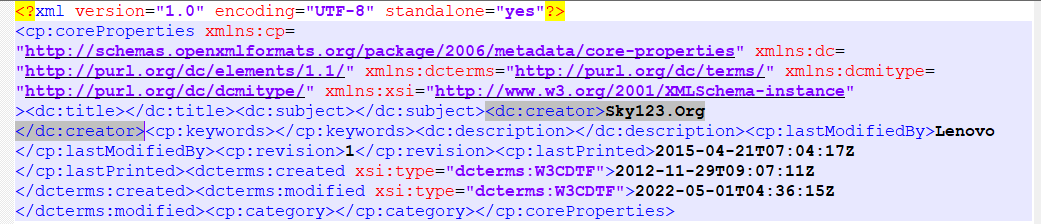 使用python的xml库解析core.xml文件,就能获取到最后一次保存的日期
使用python的xml库解析core.xml文件,就能获取到最后一次保存的日期
import zipfile
import xml.dom.minidom as xdom
import datetime
p = r'D:\python\test.xlsx'
azip = zipfile.ZipFile(p)
a = azip.read('docProps/core.xml').decode('utf-8')
xp = xdom.parseString(a)
root=xp.documentElement
ele=root.getElementsByTagName('dcterms:modified')
md_time_str = ele[0].firstChild.data
md_time = datetime.datetime.strptime(md_time_str, '%Y-%m-%dT%H:%M:%SZ')
md_time_local = md_time + datetime.timedelta(hours=8)
print(f'最后一次保存的日期:{md_time_local}')
ele=root.getElementsByTagName('dcterms:created')
cr_time_str = ele[0].firstChild.data
cr_time = datetime.datetime.strptime(cr_time_str, '%Y-%m-%dT%H:%M:%SZ')
cr_time_local = cr_time + datetime.timedelta(hours=8)
print(f'创建内容的时间:{cr_time_local}')
azip.close()3、xls文件的实现就相对麻烦一些
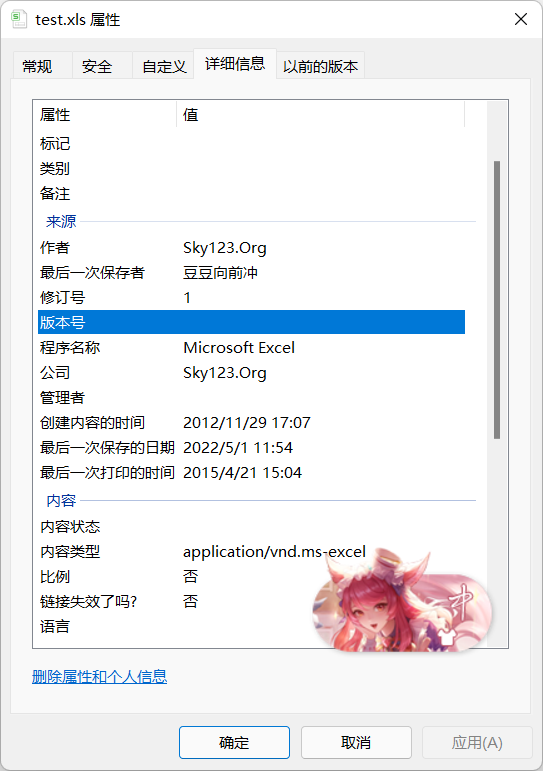
同样用压缩软件打开xls文件,可以看到_SummartInformation文件
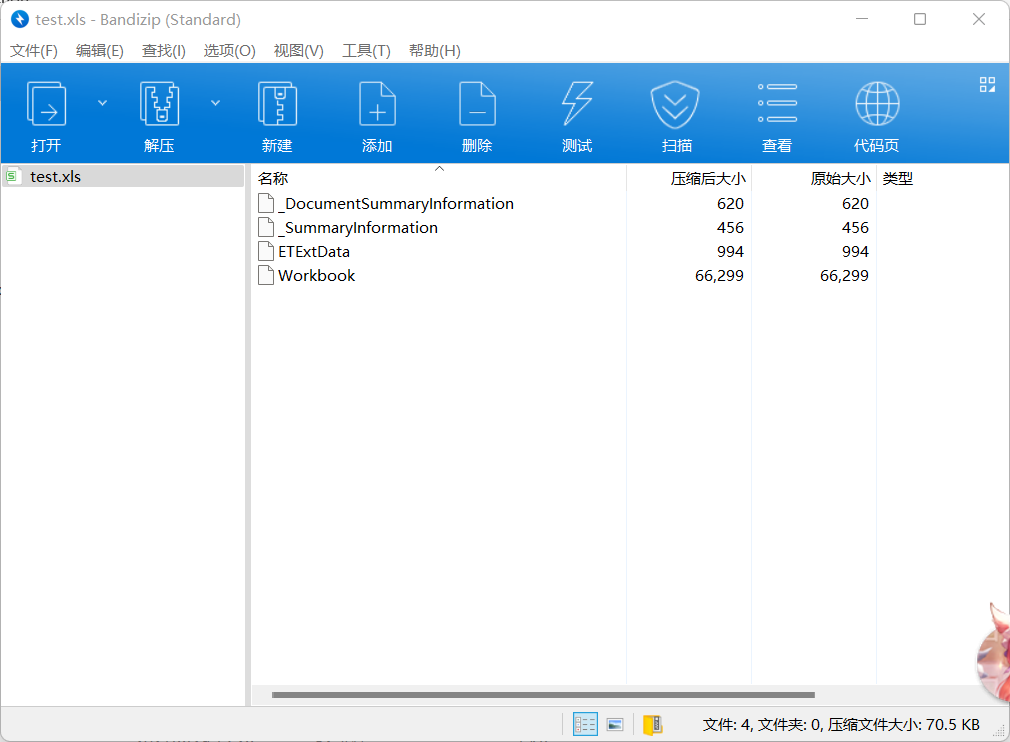
导出后使用WinHex打开该文件,如图
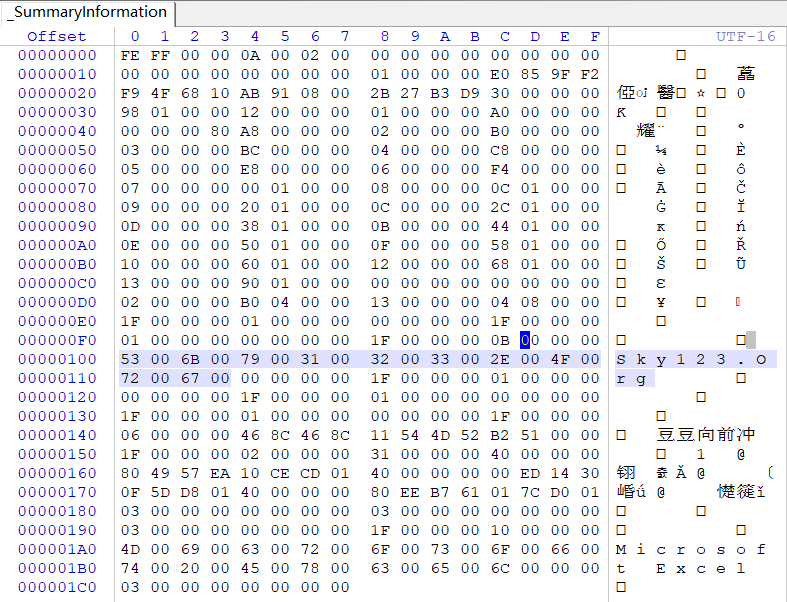
01CH开始的20个字节记录了属性组信息,其中的后4个字节记录了属性组相对于该数据流起始位置的偏移,此处采用了16进制小端方式,所以偏移量为30,所以从30H开始为属性组数据,我们需要的元数据就记录在这里。
每个属性占据8个字节,前4个字节记录属性的种类,此处0x02记录的是文档标题,0x04记录的是作者,0x08记录的是最后一次保存者,0x0B记录的是最后打印时间,0x0C记录的是创建时间,0x0D记录的是最后保存时间,后4个字节记录的是该属性相对属性组的偏移,这里以最后保存者和最后保存时间为例说明。
最后保存者的相对属性组的偏移为010C,即013CH开始到014FH结束,前4个字节记录的估计是属性内容的类型(未找到资料),分析0x1F为字符串型,使用python进行解码,即可获得最后保存者内容。
hex_byte = b'\x06\x00\x00\x00\x46\x8c\x46\x8c\x11\x54\x4d\x52\xb2\x51\x00\x00'
result_byte = hex_byte.decode('utf-16')
print(f'16进制解码之后的数据为:{result_byte}')同理最后保存时间属性从0168H开始到0173H结束,前4字节04分析代表时间类型,因为是小端,所以实际时间为01d85d0f3014ed00,用python进行解码,即可获得最后保存时间。
from datetime import datetime,timedelta
dt = '01d85d0f3014ed00'
us = int(dt,16) / 10.
local = datetime(1601,1,1) + timedelta(microseconds=us) + timedelta(hours=8)
print(local)














 8223
8223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









