






目录
4.半同步复制什么情况下会降为异步复制?什么时候又会恢复半同步复制?
一.MySQL读写分离概述
1.什么是读写分离?
- 读写分离,基本的原理是让主数据库处理事务性增、改、删操作( INSERT、UPDATE、DELETE) ,而从数据库处理SELECT查询操作
- 数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库
2.为什么要读写分离呢?
- 因为数据库的“写”(写10000条数据可能要3分钟)操作是比较耗时的
- 但是数据库的“读”(读10000条数据可能只要5秒钟)
- 所以读写分离,解决的是,数据库的写入,影响了查询的效率
3.运用时间
数据库不一定要读写分离,如果程序使用数据库较多时,而更新少,查询多的情况下会考虑使用。
利用数据库主从同步,再通过读写分离可以分担数据库压力,提高性能
4.主从复制与读写分离
在实际的生产环境中,对数据库的读和写都在同一个数据库服务器中,是不能满足实际需求的。无
论是在安全性、高可用性还是高并发等各个方面都是完全不能满足实际需求的。因此,通过主从复
制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力。有点类似于rsync,但是不
同的是rsync是对磁盘文件做备份,而mysql主从复制是对数据库中的数据、语句做备份。
二、MySQL主从复制原理
1.主从复制的作用
- 实现读写分离
- 跨主机热备份数据
- 作为数据库高可用性的基础
2.mysql支持的复制类型
STATEMENT:基于语句的复制。在服务器上执行sql语句,在从服务器上执行同样的语句,mysql默认采用基于语句的复制(5.7版本之前),执行效率高。高并发的情况可能会出现执行顺序的误差,事务的死锁
ROW:基于行的复制。把改变的内容复制过去,而不是把命令在从服务器上执行一 遍。精确,但效率低,保存的文件会更大。(5.7版本之后默认采用ROW模式)
MIXED:混合类型的复制。默认采用基于语句的复制,一旦发现基于语句无法精确复制时,就会采用基于行的复制。更智能,所以大部分情况下使用MIXED
STATEMENT
基于语句的复制
优点:执行效率高,占用空间小
缺点:无法保证在高并发高负载时候的精确度
ROW
基于行的复制
优点:精确度高
缺点:执行效率低,占用空间大
MIXED
混合类型的复制
默认采用基于语句的复制,一旦发现基于语句无法保证精确复制时,就会采用基于行的复制
3.主从复制的原理
就是基于二进制日志进行数据同步的
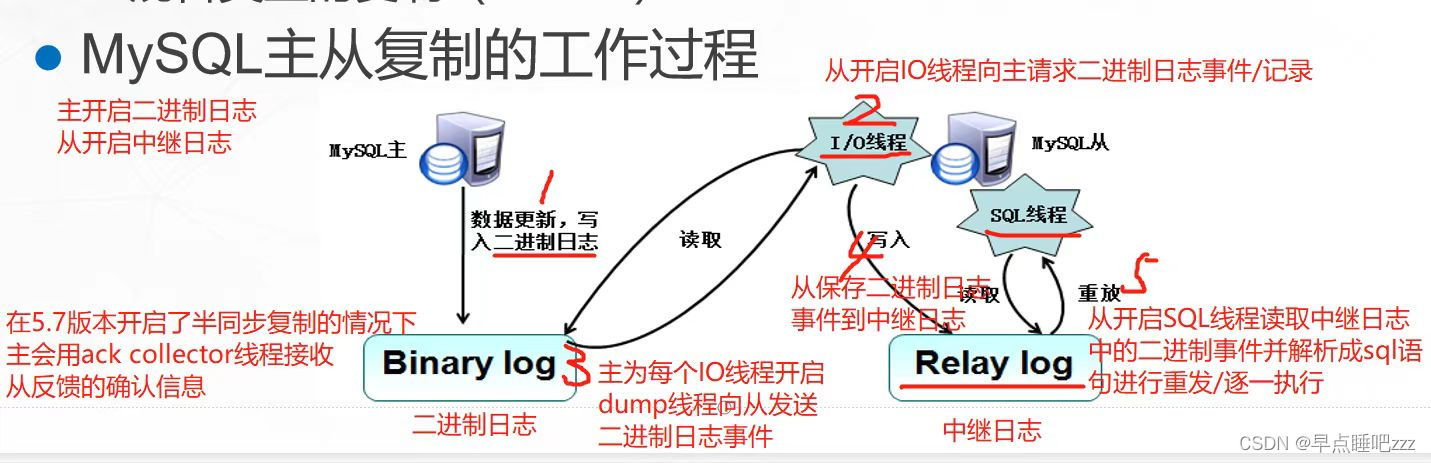
4.主从复制的过程
主从复制基于主mysql服务器和从mysql服务器的三个线程和两个日志展开进行的
两个日志:二进制日志(bin log) 、中继日志(Relay log)
三个线程:I/O线程、dump线程、SQL线程具体过程
- 主库(master)如果发生数据更新,会将写入操作记录到二进制日志(bin log)里
- 从库(slave)探测到主库的二进制日志发生了更新,就会开启IO线程向主库请求二进制日志事件
- 主库会为每个从库IO线程的请求开启DUMP线程,并发送二进制日志事件给从库
- 从库接收到二进制日志事件后会保存到自己的中继日志(relay log)中
- 附:在半同步模式下从库会返回确认信息给主库,主库会用ack收集线程接收从库反馈的确认信息(5.7版本开始支持)
- 从库还会开启SQL线程读取中继日志里的事件,并在本地重放(将二进制日志事件解析成sql语句逐一执行),从而实现主库和从库的数据一致
5.主从复制的配置步骤
- 主从服务器先做时间同步
- 修改主从数据库的配置文件,主库开启二进制日志,从库开启中继日志
- 在主库创建主从复制的用户,并授予主从复制的权限
- 在从库使用 change master to 对接主库,并 start slave 开启同步
- 在从库使用 show slave status\G 查看 IO线程和 SQL线程的状态是否都为 YES
6.主从复制的同步模式
异步复制
- 主库在执行完客户端提交的事务后就会立即响应给客户端
半同步复制
- 主库在执行完客户端提交的事务后,只要等待一个从库返回响应给主库,才会响应给客户端
全同步复制
- 主库在执行完客户端提交的事务后,要等待所有从库返回都响应给主库,才会响应给客户端
三、主从复制的常见问题及解决方案
1.主从复制延迟的原因及解决方案
主从复制延迟原因
- 主库写入操作并发量太大
- 网络延迟
- 从库硬件比主库差
- 使用了同步复制
- 慢SQL语句过多
根本原因
主库可以并发多线程执行写入操作,而从库的SQL线程默认是单线程串行化复制,从库的复制效率
可能会跟不上主库的写入速度
如何判断
通过在从库执行show slave status\G命令,查看输出的Seconds_Behind_Master参数的值来判断,
是否有发生主从延时。如果为正值表示主从已经出现延时,数字越大表示从库落后主库越多。
解决方案
(1)硬件方面
从库配置更好的硬件,提升随机写的性能。比如原本是机械盘,可以考虑更换为ssd固态。升级核心数更强的cpu、加大内存。避免使用虚拟云主机,使用物理主机
(2)网络方面
将从库分布在相同局域网内或网络延迟较小的环境中。尽量避免跨机房,跨网域进行主从数据库服务器的设置
(3)架构方面
在事务当中尽量对主库读写,其他非事务中的读在从库。消除一部分延迟带来的数据库不一致。增加缓存降低一些从库的负载。
(4)mysqld服务配置方面
该配置设置针对mysql主从复制性能优化最大化,安全性并不高。如果从安全的角度上考虑的话,就要设置双一设置
sync_binlog=0 innodb_flush_log_at_trx_commit=2
#由于从库不需要这么高的数据安全性,所以不使用 双1设置
logs-slave-updates=0
#从库同步的事件不记录到从库自身的二进制日志中
innodb_buffer_pool_size=物理内存的80%
#加大innodb引擎缓存池大小,让更多数据读写在内存中完成,减少磁盘的IO压力2.主从复制不一致的原因及解决方案
产生主从复制不一致的可能原因
- 人为原因导致从库与主库数据不一致(从库写入)
- 主从复制过程中,主库异常宕机
- 设置了ignore/do/rewrite等replication等规则
- binlog非row格式
- 异步复制本身不保证,半同步存在提交读的问题,增强半同步起来比较完美。 但对于异常重启(Replication Crash Safe),从库写数据(GTID)的防范,还需要策略来保证。
- 从库中断很久,binlog应用不连续,监控并及时修复主从
- 从库启用了诸如存储过程,从库禁用存储过程等
- 数据库大小版本/分支版本导致数据不一致?,主从版本统一
- 备份的时候没有指定参数 例如mysqldump --master-data=2 等
- 主从sql_mode 不一致
- 一主二从环境,二从的server id一致
- MySQL自增列 主从不一致
- 主从信息保存在文件里面,文件本身的刷新是非事务的,导致从库重启后开始执行点大于实际执行点
- 采用5.6的after_commit方式半同步,主库当机可能会引起主从不一致,要看binlog是否传到了从库
- 启用增强半同步了(5.7的after_sync方式),但是从库延迟超时自动切换成异步复制
解决方案
1.先进入主库,进行锁表,防止数据写入
flush tables with read lock;
set gloabl read_only=1;2.进行数据全量备份
mysqldump -u root -p密码 库名 表名 > XXX.sql3.使用scp命令把备份文件传到从库机器,进行数据恢复
scp XXX.sql 从库IP:目录/4.使用 change master to 重新做主从复制
change master to master_host='主库IP', master_port=3306, master_user='用户名', master_password='密码', master_log_file='二进制文件', master_log_pos=二进制事件位置;
附:二进制文件和二进制事件位置需要在主库查询 show master status;
start slave;5.主库解锁
unlock tables;
set gloabl read_only=03.MySQL从服务器挂了 恢复后怎么保证数据同步
- 物理方法: rsync 磁盘文件同步。 使用文件恢复,主节点需要停服务
- 主从复制: 将从节点原有库删除,通过偏移量,重新做一次主从复制
4.半同步复制什么情况下会降为异步复制?什么时候又会恢复半同步复制?
- 当主库在半同步复制超时时间内(rpl_semi_sync_master_timeout)没有收到从库的响应,就会自动降为半同步复制
- 当主库发送完一个事务事件后,主库在超时时间内收到了从库的响应,就会又恢复为半同步复制















 597
597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









