






RAG知识系列文章
- RAG入门实践:手把手Python实现搭建本地知识问答系统
- 从基础到模块化:深度解析RAG技术演进如何重塑AI知识边界
- 【RAG检索】RAG技术揭秘:检索≠召回?
- 【RAG增强】解密RAG系统排序优化:从基础原理到生产实践
- 【RAG生成】深入RAG生成模块(Generation)的学习指南
一、RAG是什么?为什么需要它?
RAG(检索增强生成) 是大语言模型(LLM)与知识库结合的解决方案。与直接让LLM生成答案不同,RAG会先从知识库检索相关内容,再结合上下文生成回答。这种模式既解决了LLM的"幻觉"问题,又能动态更新知识。
对比其他技术:
- 纯上下文问答:依赖LLM自身记忆,无法处理私有知识
- 模型微调:需重新训练模型,成本高且无法实时更新知识
- RAG优势:无需训练模型、支持动态更新、答案可溯源
RAG(检索增强生成)就像给AI装了个“智能小助手”,让AI在回答问题前先学会“查资料”。举个例子,假设你问AI:“最新的新能源汽车政策有什么变化?”传统AI可能只能凭记忆回答,但RAG会先做两件事:
-
查资料:AI会快速翻遍它连接的数据库、文档库(比如政策文件、行业报告),找到和“新能源汽车政策”相关的最新内容,就像你用百度搜索关键词一样。
-
整理答案:AI把这些资料读一遍,理解后再用“人话”总结出来,比如告诉你:“2024年起,购买新能源车补贴额度提高了5%,并且充电桩建设将优先覆盖一线城市。”
为什么选择从零构建RAG系统?超越无代码工具的三大实践价值
当LLM技术进入应用深水区,市面上涌现了众多「零代码部署RAG」的解决方案(如AnythingLLM、AWS Bedrock、Cohere Embedding API等)。但对于追求技术本质的AI学习者而言,模块化自建RAG系统才是解锁核心能力的密钥:
🛠️ 深度原理拆解优势
-
检索增强的透明化
通过手写向量检索逻辑(Chroma+FAISS),真正理解Query重写、向量对齐、相似度阈值调优等核心机制,而非停留在API调用层面。 -
数据管道的可控性
从原始文本清洗(正则处理)→ 语义分块(RecursiveSplitter)→ 向量编码(BERT/Embedding模型微调),全程掌控数据流转细节。 -
生成质量的调试权
自定义提示工程模板,结合Rouge-L/BLEU指标验证生成效果,而非接受黑箱系统的不可解释输出。
⚡ 技术能力成长路径
[编程实践] → [架构设计] → [生产级优化]
Python实现核心模块 分布式检索架构设计 缓存策略/降级方案
LangChain深度定制 多路召回融合 GPU量化加速
🚀 企业级扩展空间
当掌握自建RAG的完整实现后,可轻松演进至:
- 混合检索系统:结合传统BM25与神经检索的优势
- 多模态RAG:跨文本/图像/音视频的联合检索增强
- 增量学习引擎:动态更新知识库而不重建全量索引
为什么用RAG?
- 减少瞎编:传统AI容易“脑补”错误答案(比如编造不存在的政策),RAG靠真实资料生成,更靠谱。
- 与时俱进:资料库更新后,AI能立刻获取新知识,不用重新训练模型。
- 专业领域:比如医疗、法律,RAG能快速调用专业文档,让AI秒变“专家”。
简单来说,RAG=搜索引擎+写作助手,让AI既会找资料又会组织语言,回答更准、更实用。
RAG流程原理图:用户输入→文档检索→上下文拼接→LLM生成→答案输出
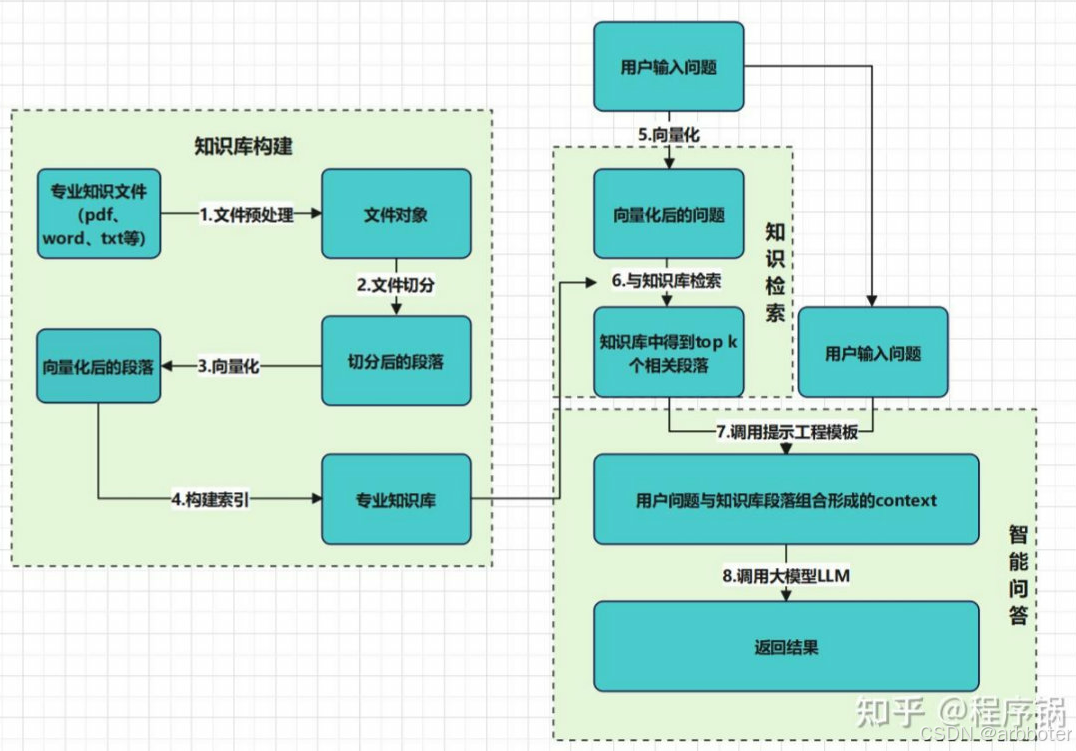
技术栈:
- LangChain + Chroma + Embedding模型(text2vec)
- 实现私有知识库问答系统(从PDF/网页数据提取到检索增强)
- 优化技巧:HyDE查询改写、多路召回融合(未完成)
二、核心工具全家桶
# 所需工具清单
tools = [
"ollama(本地LLM服务)",
"mxbai-embed-large(嵌入模型)",
"deepseek-r1:7b(思考模型)",
"langchain(流程编排框架)",
"RecursiveCharacterTextSplitter(文本分割)",
"Chroma(向量数据库)"
]
三、本地模型部署
1. 安装Ollama
curl -fsSL https://ollama.ai/install.sh | sh
2. 下载模型
# 嵌入模型(文本转向量)
ollama pull mxbai-embed-large
# 思考模型(生成答案)
ollama pull deepseek-r1:7b
模型优势对比:
| 模型名称 | 优势特点 |
|---|---|
| mxbai-embed-large | 支持512维向量/多语言/检索效率高 |
| deepseek-r1:7b | 7B参数/推理速度快/生成质量稳定 |
详细部署运行方法及说明请参考上篇文章
四、文档处理核心模块
1. 文档加载器(document_loaders)
langchain_community.document_loaders 是 LangChain 中用于从不同数据源加载文档的核心模块,其核心功能是将文件/数据转化为标准化的 Document 对象(包含文本内容和元数据)。
核心特性
- 多格式支持:支持 PDF、CSV、HTML、JSON、Word、Excel 等 80+ 格式
- 元数据保留:自动提取文件名、来源路径、创建时间等附加信息
- 灵活分割:与文本分割器配合实现长文本分块处理
- 延迟加载:支持按需加载大文件,避免内存溢出
常见文档加载器速览
| 加载器类 | 适用场景 | 关键参数示例 |
|---|---|---|
UnstructuredFileLoader | 通用文件(自动识别格式) | mode="elements"(按段落分割) |
PyMuPDFLoader | PDF 解析(保留文字布局) | text_chars_threshold=50 |
CSVLoader | 结构化表格数据 | csv_args={"delimiter": ","} |
WebBaseLoader | 网页内容抓取 | continue_on_failure=True |
JSONLoader | JSON 文件解析 | jq_schema=".[].content" |
代码示例(含 4 种典型场景)
# 安装依赖(运行前执行)
# pip install langchain-community unstructured pymupdf
from langchain_community.document_loaders import (
UnstructuredFileLoader,
PyMuPDFLoader,
CSVLoader,
WebBaseLoader
)
# 场景1:加载本地Word文档(按段落分割)
word_loader = UnstructuredFileLoader(
"report.docx",
mode="elements" # 按自然段落拆分
)
word_docs = word_loader.load()
print(f"Word段落数: {len(word_docs)}") # 输出段落数量
# 场景2:解析PDF并保留元数据
pdf_loader = PyMuPDFLoader("paper.pdf")
pdf_docs = pdf_loader.load()
# 查看第一页内容
print(pdf_docs[0].page_content[:100]) # 前100字符
print(pdf_docs[0].metadata) # {'source': 'paper.pdf', 'page': 1}
# 场景3:加载CSV表格数据(自定义列名)
csv_loader = CSVLoader(
"sales.csv",
csv_args={"fieldnames": ["日期", "销售额", "区域"]}
)
csv_docs = csv_loader.load()
# 输出首行数据
print(csv_docs[0].page_content) # "日期: 2023-01, 销售额: 150万, 区域: 华东"
# 场景4:抓取网页内容
web_loader = WebBaseLoader(["https://news.qq.com"])
web_docs = web_loader.load()
print(f"抓取到{len(web_docs)}篇网页内容")
技术细节说明
-
元数据保留
所有加载器自动添加source(文件路径/URL),部分加载器添加额外信息:# PDF示例元数据 {'source': 'paper.pdf', 'page': 2, 'format': 'PDF 1.5'} -
性能优化技巧
# 多线程加载大文件夹 from langchain_community.document_loaders import DirectoryLoader loader = DirectoryLoader( "data/", glob="**/*.pdf", use_multithreading=True # 启用多线程 ) -
异常处理
try: docs = loader.load() except Exception as e: print(f"加载失败: {str(e)}") docs = []
典型应用链路
文件加载 → 文本分割 → 向量化 → 存入数据库
(Document对象) → (TextSplitter) → (Embedding) → (VectorDB)
通过标准化 Document 格式,文档加载器成为 LangChain 处理非结构化数据的统一入口,为后续的检索增强生成(RAG)等应用奠定基础。
2. 文本分割器
langchain.text_splitter.RecursiveCharacterTextSplitter 是 LangChain 中用于递归分割文本的核心工具,其核心逻辑是优先保留大语义单元(段落 → 句子 → 单词),适用于需要保持上下文关联的场景。
核心特性
-
递归分割机制
按分隔符优先级顺序(默认["\n\n", "\n", " ", ""])逐级拆分文本,直到所有块满足chunk_size限制。 -
智能合并策略
当拆分后的片段过小时,会自动合并相邻片段,确保最终块长度不超过chunk_size。 -
上下文保留
通过chunk_overlap参数设置重叠字符数,避免关键信息被割裂。
关键参数解析
| 参数名 | 作用 | 默认值 |
|---|---|---|
chunk_size | 目标块的最大字符数 | 4000 |
chunk_overlap | 相邻块的重叠字符数 | 200 |
separators | 自定义分隔符列表(按优先级排序) | 根据语言预设 |
length_function | 计算文本长度的方法(如按字符数或token数) | len |
代码示例(含 3 种典型场景)
# 安装依赖(运行前执行)
# pip install langchain-text-splitters tiktoken
from langchain_text_splitters import RecursiveCharacterTextSplitter
# ===== 场景1:基础文本分割 =====
text = """人工智能(AI)是模拟人类智能的计算机系统。\n\n
这些系统能够学习、推理、自我修正和执行任务。\n
主要应用领域包括自然语言处理、计算机视觉等。"""
splitter_basic = RecursiveCharacterTextSplitter(
chunk_size=100, # 目标块大小
chunk_overlap=20, # 重叠字符数
separators=["\n\n", "\n", "。", " "] # 自定义分隔符优先级
)
docs = splitter_basic.create_documents([text])
for i, doc in enumerate(docs):
print(f"块{i+1}: {doc.page_content}\n长度: {len(doc.page_content)}\n")
# 输出示例:
# 块1: 人工智能(AI)是模拟人类智能的计算机系统。 (长度45)
# 块2: 这些系统能够学习、推理、自我修正和执行任务。 (长度44) [含20字符重叠]
# ===== 场景2:中文长文本分割 =====
chinese_text = "自然语言处理是人工智能的重要分支。它使计算机能够理解、生成人类语言。"
splitter_zh = RecursiveCharacterTextSplitter(
chunk_size=30,
chunk_overlap=10,
separators=["。", ",", "\n"] # 优先按句分割
)
zh_docs = splitter_zh.create_documents([chinese_text])
print([doc.page_content for doc in zh_docs])
# 输出: ['自然语言处理是人工智能的重要分支', '它使计算机能够理解、生成人类语言']
# ===== 场景3:代码文件分割 =====
python_code = """
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n-1)
print(factorial(5))
"""
code_splitter = RecursiveCharacterTextSplitter.from_language(
language="python", # 支持20+编程语言
chunk_size=50,
chunk_overlap=0
)
code_docs = code_splitter.create_documents([python_code])
print([doc.page_content.strip() for doc in code_docs])
# 输出: ['def factorial(n):\n if n == 0:\n return 1', 'else:\n return n * factorial(n-1)', 'print(factorial(5))']
技术原理详解
-
递归分割流程
原始文本 → 用第一级分隔符拆分 → 检查块大小 → 超过则用下一级分隔符 → 递归直到满足条件 -
长度计算逻辑
默认按字符数计算,也可通过length_function使用 token 计数器(如结合tiktoken):from tiktoken import encoding_for_model enc = encoding_for_model("gpt-4") splitter_token = RecursiveCharacterTextSplitter.from_tiktoken_encoder( model_name="gpt-4", chunk_size=100, # 按token计数 chunk_overlap=20 )
最佳实践建议
-
参数调优策略
- 技术文档:
chunk_size=800-1200,overlap=100-200 - 对话记录:
chunk_size=300-500,overlap=50-100 - 代码文件:使用
from_language()方法自动配置语言专用分隔符
- 技术文档:
-
异常处理
try: docs = splitter.create_documents([text]) except ValueError as e: print(f"分割失败: {str(e)}") # 可回退到字符级分割 emergency_splitter = RecursiveCharacterTextSplitter(chunk_size=500) docs = emergency_splitter.create_documents([text])
典型应用场景
-
RAG 知识库构建
将长 PDF 文档分割为带上下文的语义块,提升检索精度。 -
代码分析工具
保持函数/类的完整性进行代码片段分析。 -
对话历史处理
维护多轮对话的上下文连贯性。
五、向量数据库
向量数据库是专门为处理高维向量数据设计的数据库,核心功能是快速找到与目标最相似的向量。类比来说,传统数据库像图书馆按书名找书,向量数据库则能根据书的“内容特征”找到风格相似的书。
与传统数据库的区别(以关系型数据库为例)
| 对比维度 | 传统数据库 | 向量数据库 |
|---|---|---|
| 数据类型 | 表格、数字/文本等结构化数据 | 图片/音频/文本的向量(非结构化) |
| 核心操作 | 精确匹配(如姓名=“张三”) | 相似性搜索(如找最像的10张图) |
| 数据规模 | 亿级数据已是挑战 | 千亿级数据是常态 |
| 计算复杂度 | 简单条件筛选 | 高维向量距离计算(算力密集) |
| 典型应用 | 银行交易、订单管理 | 人脸识别、推荐系统、图片搜索 |
向量数据库的优点
-
高效处理非结构化数据
将图片、文本等转为向量存储,解决传统数据库无法直接处理的问题。
示例:人脸特征存为512维向量,搜索时直接比对特征相似度。 -
快速相似性搜索
支持毫秒级返回最相似结果,比传统遍历快数千倍。
技术支撑:HNSW、IVF索引优化计算效率。 -
支持高维数据和大规模扩展
单表可存千亿级向量,分布式架构轻松扩容。
案例:平安城市千亿人脸库,秒级检索。 -
与AI无缝结合
直接存储大模型生成的向量(如文本Embedding),加速RAG等应用。
主流向量数据库及适用场景
| 数据库 | 特点 | 适用场景 |
|---|---|---|
| Milvus(开源) | 分布式架构,支持海量数据,社区活跃 | 图片/视频检索、推荐系统 |
| Pinecone | 全托管服务,企业级稳定性,集成AI工具链 | 电商推荐、语义搜索(如Shopify) |
| 腾讯云向量数据库 | 高并发(百万QPS),10亿级向量检索 | 实时人脸识别、大模型知识库 |
| Qdrant | 轻量级,Rust开发,适合中小规模 | 文本相似性搜索、初创项目 |
| Weaviate | 内置Embedding模型,支持多模态 | 智能问答、知识图谱构建 |
| Chroma | 快速原型开发 |
典型应用场景
- 人脸识别
如:公安系统千亿级人脸库实时比对。 - 推荐系统
如:抖音根据用户行为向量推荐相似视频。 - 以图搜图
如:电商平台用商品图片特征向量找同款。 - 大模型增强
如:RAG技术中快速检索外部知识库提升回答准确性。
Chroma 使用示例
以下是一个使用 langchain_chroma 的完整 Python 示例,涵盖本地数据库初始化、文档新增、持久化和加载存量的全流程:
# 1. 安装依赖(运行前执行)
# pip install langchain-chroma langchain-community sentence-transformers
# 2. 代码示例
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
# 配置参数
persist_directory = "./my_chroma_db" # 持久化目录
doc_path = "./sample.txt" # 示例文档路径
# 初始化嵌入模型(使用轻量级sentence-transformers)
embedding = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# ===== 首次运行:创建数据库 =====
def create_and_save_db():
# 加载文档(示例文本文件)
loader = TextLoader(doc_path, encoding="utf-8")
documents = loader.load()
# 分割文本(每段1000字符,不重叠)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=0
)
splits = text_splitter.split_documents(documents)
# 创建并持久化向量数据库
vectordb = Chroma.from_documents(
documents=splits,
embedding=embedding,
persist_directory=persist_directory
)
vectordb.persist() # 显式保存
print("数据库创建完成,已持久化到:", persist_directory)
# ===== 后续运行:加载已有数据库 =====
def load_and_use_db():
# 直接加载已有数据库
vectordb = Chroma(
persist_directory=persist_directory,
embedding_function=embedding
)
# 验证数据(示例:统计文档数)
collection = vectordb._client.get_collection("langchain")
print(f"已加载数据库,当前文档数: {collection.count()}")
# 示例:新增文档
new_docs = ["OpenAI发布了GPT-5模型", "特斯拉推出新款电动跑车"]
vectordb.add_texts(new_docs)
vectordb.persist() # 再次保存
print("新增文档后文档数:", collection.count())
# 执行流程
if __name__ == "__main__":
# 首次运行创建数据库(完成后可注释掉)
# create_and_save_db()
# 后续运行加载已有数据库
load_and_use_db()
关键点说明:
- 持久化路径:
persist_directory参数指定本地存储位置 - 嵌入一致性:始终使用相同的
embedding模型保证向量兼容性 - 文档处理:
- 使用
TextLoader+RecursiveCharacterTextSplitter处理长文本 chunk_size=1000平衡上下文长度与检索精度
- 使用
- 增量更新:
add_texts()方法支持动态添加文档- 修改后需调用
persist()保存变更
- 性能优化:
- 轻量级
all-MiniLM-L6-v2模型适合本地运行 - 自动复用已有索引,避免重复计算
- 轻量级
文件结构示例:
项目目录/
├── sample.txt # 示例文档(需手动创建)
├── my_chroma_db/ # 自动生成的数据库目录
│ ├── chroma.sqlite3 # 元数据
│ └── index/ # 向量索引
└── demo.py # 上述代码文件
总结
向量数据库是AI时代的“数据配对专家”,用向量化思维解决非结构化数据的存储和检索难题,尤其适合需要相似性计算和实时响应的场景。随着大模型普及,它将成为AI应用的基础设施之一。
六、完整实现流程
Step 1 文档入库
from langchain_community.embeddings import OllamaEmbeddings
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
vector_db = Chroma.from_documents(
documents=texts,
embedding=embeddings,
persist_directory="./data"
)
Step 2 构建问答链
qa_chain = RetrievalQA.from_chain_type(
llm=Ollama(model="deepseek-r1:7b"),
retriever=vector_db.as_retriever(),
chain_type="stuff"
)
Step 3 测试问答
query = "RAG有哪些核心组件?"
result = qa_chain({"query": query})
print(result["result"])
七、完整测试代码
# app.py
import os,time,json
from flask import Flask, request, jsonify, render_template, Response
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain_community.document_loaders import PyPDFLoader, TextLoader
from langchain_ollama import OllamaEmbeddings, OllamaLLM
from langchain_chroma import Chroma
app = Flask(__name__)
UPLOAD_FOLDER = 'uploads'
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
# 初始化模型
# app.py 修改部分
# 新增配置参数
OLLAMA_HOST = os.getenv('OLLAMA_HOST', 'http://127.0.0.1:11434') # 从环境变量读取
# 修改模型初始化部分
embeddings = OllamaEmbeddings(
model='mxbai-embed-large',
base_url=OLLAMA_HOST # 添加base_url参数
)
llm = OllamaLLM(
model='deepseek-r1:7b',
temperature=0.3,
base_url=OLLAMA_HOST, # 添加base_url参数
)
vector_store = None
def init_vector_store(filepath=None):
global vector_store
# 空路径时初始化本地数据库
if not filepath:
if not vector_store:
if os.path.exists('chroma_db'):
vector_store = Chroma(
persist_directory='chroma_db',
embedding_function=embeddings
)
print(f"成功加载本地知识库,文档数:{vector_store._collection.count()}")
else:
raise ValueError("本地数据库不存在,请先添加文档")
return
# 非空路径时处理文档
try:
# 文档加载与分块
loader = PyPDFLoader(filepath) if filepath.endswith('.pdf') else TextLoader(filepath)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1024,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_documents(documents)
# 数据库操作
if vector_store:
vector_store.add_documents(chunks)
print(f'文档已追加: {filepath}')
else:
vector_store = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory='chroma_db'
)
print(f'新建知识库成功: {filepath}')
vector_store.persist() # 确保持久化存储
except Exception as e:
print(f"文档处理失败: {str(e)}")
raise
def upload_file():
if 'file' not in request.files:
return jsonify({'error': 'No file uploaded'}), 400
file = request.files['file']
if file.filename == '':
return jsonify({'error': 'Empty filename'}), 400
filepath = os.path.join(UPLOAD_FOLDER, f"{file.filename}")
try:
if not os.path.exists(filepath):
file.save(filepath)
init_vector_store(filepath)
return jsonify({'message': 'File processed successfully'})
except Exception as e:
return jsonify({'error': str(e)}), 500
def ask_question():
data = request.json
print('收到请求:', data)
if not data or 'question' not in data:
def error_stream():
yield json.dumps({'error': 'No question provided'}) + '\n'
return Response(error_stream(), mimetype='application/x-ndjson'), 400
try:
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vector_store.as_retriever(search_kwargs={'k': 3}),
chain_type="stuff",
)
def generate_stream():
try:
# 修改为流式调用方式
response_stream = qa_chain.stream({'query': data['question']})
for chunk in response_stream:
content = chunk['result']
# 逐块返回结果并立即刷新缓冲区
print('发送应答:', content)
yield content
except Exception as e:
yield f"data: {json.dumps({'error': str(e)})}\n\n"
# 设置流式响应头
return Response(
generate_stream(),
mimetype='text/event-stream',
headers={
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'X-Accel-Buffering': 'no'
}
)
except Exception as e:
def error_stream():
yield json.dumps({'error': str(e)}) + '\n'
return Response(error_stream(), mimetype='application/x-ndjson'), 500
if __name__ == '__main__':
init_vector_store()
app.run(host='0.0.0.0', port=5000, debug=True)
执行效果:
请输入问题: 本地部署RAG需要哪些组件?
答:需要嵌入模型、LLM、向量数据库、文档处理器...
通过自建RAG系统,您将获得完全可控的知识管理方案,快来打造您的专属AI助手吧!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









