









【花书阅读笔记】第七章:深度学习中的正则化 Part II
提前终止
在训练过程中训练集误差逐渐降低,但是测试集误差逐渐升高
我们只要返回验证集误差最低的参数设置,可以获得验证集误差更低的模型。
提前终止(early stopping):当算法停止时,我们返回的这些参数不是最新的参数。当验证集上的误差在指定的循环次数内没有进一步改善时, 算法就会终止。
令 n 为评估间隔的步数。 令 p 为“耐心 (patience)",即观察到较坏的验证集表现
p
p
p 次后终止。 令
θ
o
\theta_{o}
θo 为初始参数。
θ
←
θ
o
\boldsymbol{\theta} \leftarrow \boldsymbol{\theta}_{o}
θ←θo
i
←
0
i \leftarrow 0
i←0
j
←
0
j \leftarrow 0
j←0
v
←
∞
v \leftarrow \infty
v←∞
θ
∗
←
θ
\theta^{*} \leftarrow \theta
θ∗←θ
i
∗
←
i
i^{*} \leftarrow i
i∗←i
while
j
<
p
j<p
j<p do 运行训余算法
n
n
n 步,更新
θ
\theta
θ
i
←
i
+
n
i \leftarrow i+n
i←i+n
v
′
←
v^{\prime} \leftarrow
v′← ValidationSetError
(
θ
)
(\boldsymbol{\theta})
(θ)
if
v
′
<
v
v^{\prime}<v
v′<v then
j
←
0
j \leftarrow 0
j←0
$\boldsymbol{\theta}^{} \leftarrow \boldsymbol{\theta} $
$i^{} \leftarrow i $
v
←
v
′
v \leftarrow v^{\prime}
v←v′
else
j
←
j
+
1
j \leftarrow j+1
j←j+1
end if
end while
最佳参数为
θ
∗
,
\theta^{*},
θ∗, 最佳训练步数为
i
∗
i^{*}
i∗
提前终止是一种非常不显眼的正则化形式,它几乎不需要改变基本训练过程、目标函数或一组允许的参数值。权重衰减很容易地使网络陷入局部极小值。
考虑二次近似函数
J
J
J:
J
^
(
θ
)
=
J
(
w
∗
)
+
1
2
(
w
−
w
∗
)
⊤
H
(
w
−
w
∗
)
\hat{J}(\boldsymbol{\theta})=J\left(\boldsymbol{w}^{*}\right)+\frac{1}{2}\left(\boldsymbol{w}-\boldsymbol{w}^{*}\right)^{\top} \boldsymbol{H}\left(\boldsymbol{w}-\boldsymbol{w}^{*}\right)
J^(θ)=J(w∗)+21(w−w∗)⊤H(w−w∗)
梯度为
∇
w
J
^
(
w
)
=
H
(
w
−
w
∗
)
\nabla_{w} \hat{J}(\boldsymbol{w})=\boldsymbol{H}\left(\boldsymbol{w}-\boldsymbol{w}^{*}\right)
∇wJ^(w)=H(w−w∗)
下降的效果是:
w
(
τ
)
=
w
(
τ
−
1
)
−
ϵ
∇
w
J
^
(
w
(
τ
−
1
)
)
=
w
(
τ
−
1
)
−
ϵ
H
(
w
(
τ
−
1
)
−
w
∗
)
w
(
τ
)
−
w
∗
=
(
I
−
ϵ
H
)
(
w
(
τ
−
1
)
−
w
∗
)
\begin{aligned} \boldsymbol{w}^{(\tau)} &=\boldsymbol{w}^{(\tau-1)}-\epsilon \nabla_{\boldsymbol{w}} \hat{J}\left(\boldsymbol{w}^{(\tau-1)}\right) \\ &=\boldsymbol{w}^{(\tau-1)}-\epsilon \boldsymbol{H}\left(\boldsymbol{w}^{(\tau-1)}-\boldsymbol{w}^{*}\right) \\ \boldsymbol{w}^{(\tau)}-\boldsymbol{w}^{*} &=(\boldsymbol{I}-\epsilon \boldsymbol{H})\left(\boldsymbol{w}^{(\tau-1)}-\boldsymbol{w}^{*}\right) \end{aligned}
w(τ)w(τ)−w∗=w(τ−1)−ϵ∇wJ^(w(τ−1))=w(τ−1)−ϵH(w(τ−1)−w∗)=(I−ϵH)(w(τ−1)−w∗)
现在利用
H
H
H的特征分解
H
=
Q
Λ
Q
⊤
\boldsymbol{H}=\boldsymbol{Q} \boldsymbol{\Lambda} \boldsymbol{Q}^{\top}
H=QΛQ⊤得到:
$$
w{(\tau)}-w{} =\left(I-\epsilon Q \Lambda Q{\top}\right)\left(w{(\tau-1)}-w^{}\right) \
Q{\top}\left(w{(\tau)}-w^{}\right) =(I-\epsilon \Lambda) Q{\top}\left(w{(\tau-1)}-w^{}\right)
$$
假定
w
(
0
)
=
0
w^{(0)}=0
w(0)=0 并且
ϵ
\epsilon
ϵ 选择得足够小以保证
∣
1
−
ϵ
λ
i
∣
<
1
,
\left|1-\epsilon \lambda_{i}\right|<1,
∣1−ϵλi∣<1, 经过
τ
\tau
τ 次参数更新后轨迹如下:
Q
⊤
w
(
τ
)
=
[
I
−
(
I
−
ϵ
Λ
)
τ
]
Q
⊤
w
∗
\boldsymbol{Q}^{\top} \boldsymbol{w}^{(\tau)}=\left[\boldsymbol{I}-(\boldsymbol{I}-\epsilon \boldsymbol{\Lambda})^{\tau}\right] \boldsymbol{Q}^{\top} \boldsymbol{w}^{*}
Q⊤w(τ)=[I−(I−ϵΛ)τ]Q⊤w∗
在$ L^2$正则化的时候,我们可以得到
Q
⊤
w
~
=
(
Λ
+
α
I
)
−
1
Λ
Q
⊤
w
∗
Q
⊤
w
~
=
[
I
−
(
Λ
+
α
I
)
−
1
α
]
Q
⊤
w
∗
\begin{array}{l} \boldsymbol{Q}^{\top} \tilde{\boldsymbol{w}}=(\boldsymbol{\Lambda}+\alpha \boldsymbol{I})^{-1} \boldsymbol{\Lambda} \boldsymbol{Q}^{\top} \boldsymbol{w}^{*} \\ \boldsymbol{Q}^{\top} \tilde{\boldsymbol{w}}=\left[\boldsymbol{I}-(\boldsymbol{\Lambda}+\alpha \boldsymbol{I})^{-1} \alpha\right] \boldsymbol{Q}^{\top} \boldsymbol{w}^{*} \end{array}
Q⊤w~=(Λ+αI)−1ΛQ⊤w∗Q⊤w~=[I−(Λ+αI)−1α]Q⊤w∗
我们发现只需要满足:
(
I
−
ϵ
Λ
)
τ
=
(
Λ
+
α
I
)
−
1
α
(\boldsymbol{I}-\epsilon \boldsymbol{\Lambda})^{\tau}=(\boldsymbol{\Lambda}+\alpha \boldsymbol{I})^{-1} \alpha
(I−ϵΛ)τ=(Λ+αI)−1α
那么
L
2
L^2
L2正则与提前终止的结果等价
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n9KIiQSY-1596801134927)(image-20200807173548463.png)]
Bagging
Bagging (bootstrap aggregating)通过结合几个模型降低泛化误差。
主要的想法是通过训练几个不同的模型,然后让所有模型一起决策样例输出。这种技术成为集成方法。
假设我们有
k
k
k个模型, 在每个模型上的误差是
ϵ
i
\epsilon_i
ϵi, 这个误差的的零均值方差是
E
[
ϵ
i
2
]
=
v
\mathbb{E}\left[\epsilon_{i}^{2}\right]=v
E[ϵi2]=v, 且不同的误差之间的协方差是
E
[
ϵ
i
ϵ
j
]
=
c
\mathbb{E}\left[\epsilon_{i} \epsilon_{j}\right]=c
E[ϵiϵj]=c。 集成模型后的平均误差变为了
1
k
∑
i
ϵ
i
\frac{1}{k} \sum_{i} \epsilon_{i}
k1∑iϵi。而此时的零均方误差期望是:
E
[
(
1
k
∑
i
ϵ
i
)
2
]
=
1
k
2
E
[
∑
i
(
ϵ
i
2
+
∑
j
≠
i
ϵ
i
ϵ
j
)
]
=
1
k
v
+
k
−
1
k
c
\begin{aligned} \mathbb{E}\left[\left(\frac{1}{k} \sum_{i} \epsilon_{i}\right)^{2}\right] &=\frac{1}{k^{2}} \mathbb{E}\left[\sum_{i}\left(\epsilon_{i}^{2}+\sum_{j \neq i} \epsilon_{i} \epsilon_{j}\right)\right] \\ &=\frac{1}{k} v+\frac{k-1}{k} c \end{aligned}
E⎣⎡(k1i∑ϵi)2⎦⎤=k21E⎣⎡i∑⎝⎛ϵi2+j=i∑ϵiϵj⎠⎞⎦⎤=k1v+kk−1c
此时我们发现如果模型相关性越小,降低的均方误差越小。也就是说如果不同模型全部相同,那么均方误差将没有下降。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7BFQA50E-1596801134940)(image-20200807175925062.png)]
图为不同模型对数据集检测的差别,如果综合不同模型将会增大模型鲁棒性。
Dropout
dropout 可以被认为是集成大量深层神经网络的Bagging方法。dropout表示从基础网络中除去非输出单元后的子网络。
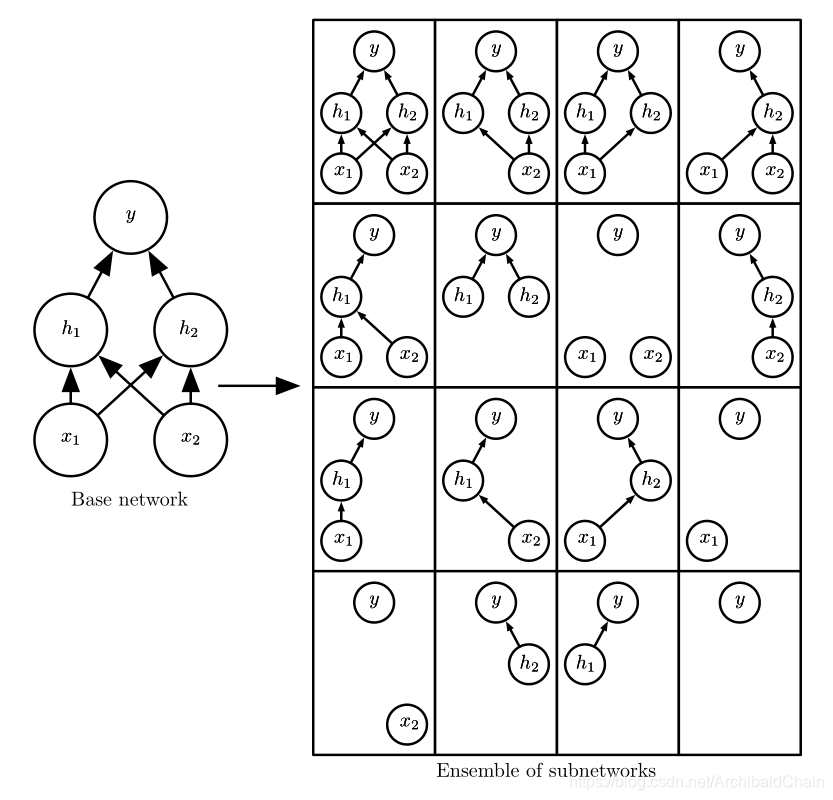
图中演示的是一个小的网络dropout的过程,其中有很多没有构成连接的网络。但通常在较大网络中,这种情况不怎么会出现。
。














 1636
1636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









