







 本文详细介绍了在Windows上安装Hadoop和Spark的步骤,包括Java环境配置、创建软链接、设置环境变量以及解决因路径空格导致的问题。在安装过程中,涉及Hadoop的core-site.xml、mapred-site.xml、hdfs-site.xml、yarn-site.xml等配置文件的修改,以及启动和测试HDFS的操作。
本文详细介绍了在Windows上安装Hadoop和Spark的步骤,包括Java环境配置、创建软链接、设置环境变量以及解决因路径空格导致的问题。在安装过程中,涉及Hadoop的core-site.xml、mapred-site.xml、hdfs-site.xml、yarn-site.xml等配置文件的修改,以及启动和测试HDFS的操作。


厦大Hadoop安装(Linux):http://dblab.xmu.edu.cn/blog/install-hadoop/
Java安装路径不能包含空格!!!
JAVA配置环境变量
使用Windows的软连接:
在Windows的命令终端(cmd)中,使用命令:
创建软连接:
mklink /J C:\myJava “C:\Program Files\Java\jdk1.8.0_221”
用户变量设置JAVA_HOME 设置
C:\myJava
添加双引号会使pyspark和maven无法运行,而空格又使hadoop无法运行; 用户变量path添加
%JAVA_HOME%\bin; CLASSPATH : .;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;
安装Hadoop
参考https://blog.csdn.net/a2099948768/article/details/79577246
https://www.cnblogs.com/yifengjianbai/p/8258898.html
下载hadoop:
https://archive.apache.org/dist/hadoop/common/ 下载2.7.1,解压即可
设置HADOOP_HOME:C:\hadoop
添加环境变量:%HADOOP_HOME%\bin
- 编辑“D:\hadoop\etc\hadoop”下的core-site.xml文件,将下列文本粘贴进去,并保存,在HADOOP_HOME目录下建立目录C:\hadoop\workplace/tmp和C:\hadoop\workplace/name;
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/hadoop/workplace/tmp</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/D:/hadoop/workplace/name</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2.编辑“D:\hadoop\etc\hadoop”目录下的mapred-site.xml(没有就将mapred-site.xml.template重命名为mapred-site.xml)文件,粘贴一下内容并保存:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
</configuration>
3.编辑“D:\hadoop\etc\hadoop”目录下的hdfs-site.xml文件,粘贴以下内容并保存。请自行创建data目录,在这里我是在HADOOP_HOME目录下创建了workplace/data目录:
<configuration>
<!-- 这个参数设置为1,因为是单机版hadoop -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/D:/hadoop/workplace/tmp</value>
</property>
</configuration>
4.编辑“D:\hadoop\etc\hadoop”目录下的yarn-site.xml文件,粘贴以下内容并保存;
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
5.编辑“D:\hadoop\etc\hadoop”目录下的hadoop-env.cmd文件,将JAVA_HOME用 @rem注释掉,编辑为JAVA_HOME的路径,然后保存:
@rem set JAVA_HOME=%JAVA_HOME%
set JAVA_HOME=D:\java\jdk
- 下载hadooponwindows-master.zip: https://github.com/sardetushar/hadooponwindows, 解压,将解压后的bin目录下的所有文件直接覆盖Hadoop的bin目录。
运行环境
2.运行cmd窗口,切换到hadoop的sbin目录,执行“start-all.cmd”,它将会启动以下四个进程。
测试:
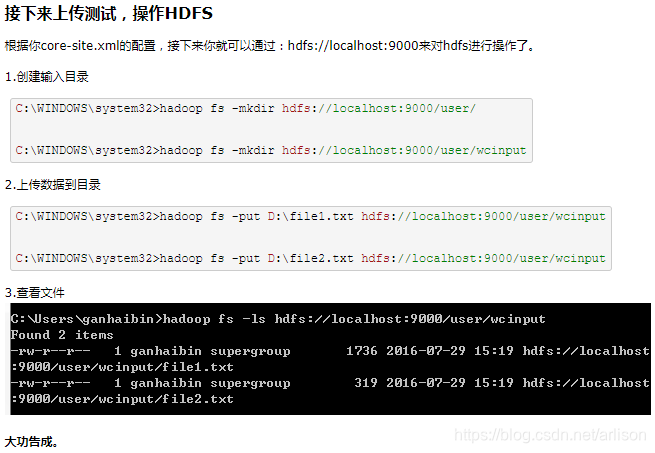
根据你core-site.xml的配置,接下来你就可以通过:hdfs://localhost:9000来对hdfs进行操作了。cmd创建输入目录:
C:\WINDOWS\system32>hadoop fs -mkdir hdfs://localhost:9000/user/
C:\WINDOWS\system32>hadoop fs -mkdir hdfs://localhost:9000/user/wcinput

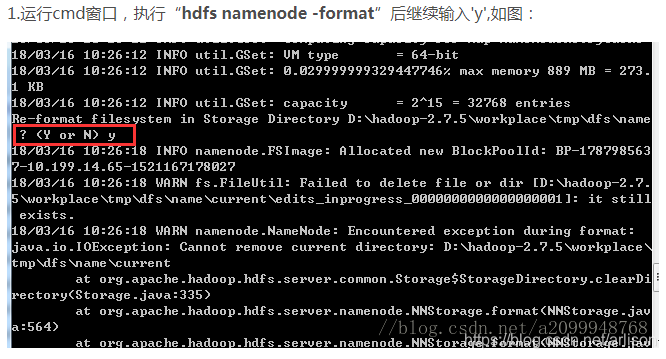
但是上传失败,反馈如下:

解决参考:http://blog.sina.com.cn/s/blog_61d8d9640102whof.html
在hdfs-site.xml里面的
dfs.datanode.data.dir
D:/hadoop/workplace/tmp
与core-site.xml里面的
hadoop.tmp.dir
D:/hadoop/workplace/tmp
两个配置应该是指向同一个目录地址,而且必须是一个已经存在的目录(不存在目录的话,在启动hadoop时,必须手动创建,否则put文件到hdfs系统时就会报错),今天报这个错就是因为两个配置没有指向同一个目录地址,已经更改上面的地址。

















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









