







从今天,我们正式开始大数据常用组件的讨论。要想在大数据这条路坚持走下去,并用好大数据,有几点建议:
1、系统的了解大数据生态中的技术框架(可通过以下文章了解)。
2、要有亲自动手的意识,并积极主动接触和学习新技术。
PS:最好能有一个自己的测试环境(有大量朋友因为环境而止步!)
3、学到的知识,多在合适的业务场景进行试用和验证。
4、一开始,不要面面俱到(不然容易受打击),针对典型的场景涉及的技术点不断深入研究。
另外,传统大数据生态涉及的技术点主要有:
1、操作系统方面:Linux常用命令、Shell编程(会ansible等类似技术更佳)。
PS:绝大部分朋友,平时工作环境应该以windows操作为主,为方便大家熟悉linux的环境,以及顺利部署和使用各个组件,后面我会专门补充一篇linux常用操作的文章。敬请期待。
2、编程语言方面:以Java/Python/Scala为主。
3、常用(或者叫 必须知道的)的组件有:
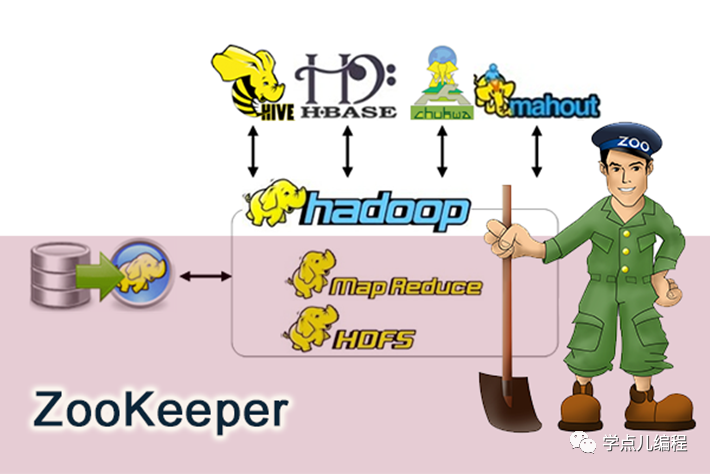
zookeeper
Flume
kafka
Elasticsearch
spark
HDFS
Hive
其他 ![]()
ZooKee
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









