







Trie,又名字典树。
Trie性能优越在于它将字符串公共前缀进行了合并,比如abcd和abd,节省了存储有一个ab的时间,同时树形的数据结构又给它带来查找上很优越的性能(优于线性表,不弱于hash),但有一个缺点是,如果字符串没有什么公共前缀,内存开销将会比较大。
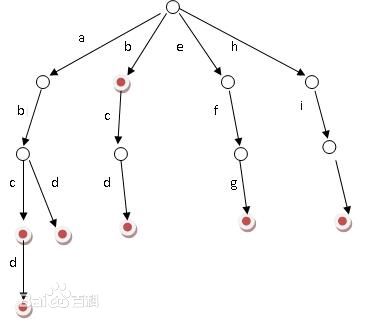
相信大家看过图之后大致应当已经了解Trie是个什么东西。
那么它有什么用呢?
①串的快速检索:对字典建树,沿边向下查找,时间复杂度O(len(s))。
②串排序:建树时,很明显这棵树的每个结点的所有儿子都按照其字母大小排序。要进行排序只需进行先序遍历。
③最长公共前缀:很明显最长公共前缀就是树根到他们最近公共祖先的树链,也就是到两个字符串分叉的节点。
④作为某些其他算法存储字符串的数据结构,如:AC自动机。
Trie的性质:
①根节点不包含字符,除根节点外每一个节点都只包含一个字符。
②从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串,也就是说只有表示字符串结尾的节点才有值。
③每个节点的所有子节点包含的字符都不相同。
大概YY一下都很好理解,有图有真相嘛……
代码实现比较简单。
struct Trie
{
int ch[maxnode][sigma_size];//这里采用儿子表示法,即列出所有儿子,效率较高,如对空间要求较高,可用儿子兄弟表示法。
int val[maxnode];
int sz;//节点总数
Trie() { sz=1; memset(ch[0],0,sizeof(ch[0])); }
int idx(char c) { return c-'a'; }
//插入字符串s,一路找下去,没有节点就新建,注意保证v非零。
void insert(char *s, int v)
{
int u=0,n=strlen(s);
for (int i=0; i<n; i++)
{
int c=idx(s[i]);
if (!ch[u][c])//节点不存在
{
memset(ch[sz],0,sizeof(ch[sz]));//新建节点
val[sz]=0;
ch[u][c]=sz++;
}
u=ch[u][c];//往下走
}
val[u]=v;//标记该字符串
}
//查找字符串,同样是一路找下去,找不到了就返回。
int find(char *s)
{
int u=0,n=strlen(s);
for (int i=0; i<n; i++)
{
int c=idx(s[i]);
if (!ch[u][c]) return 0;//不存在
u=ch[u][c];//往下走
}
return val[u];//找到了
}
};













 247
247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









