







分布式锁能帮助我们在分布式系统共享数据的并发中避免并发问题,要实现分布式锁必须保证加锁和解锁的操作是原子性的,redis的setnx和del刚好满足加锁和解锁的要求,下面使用setnx来实现可以超时的分布式锁:
import org.jmqtt.common.config.StoreConfig;
import redis.clients.jedis.JedisCluster;
import java.util.Random;
public class RedisLock {
private StoreConfig redisConfig;
private RedisStoreManager redisStoreManager;
public static JedisCluster cluster;
private static final int DEFAULT_LOCK_EXPIRSE_MILL_SECONDS = 30 * 1000;
private static final int DEFAULT_LOCK_WAIT_DEFAULT_TIME_OUT = 10 * 1000;
private static final int DEFAULT_LOOP_WAIT_TIME = 150;
private static final String LOCK_PREFIX = "LOCK:";
private boolean lock = false;
private String lockKey;
private int lockExpirseTimeout;
private int lockWaitTimeout;
public boolean isLock(){
return lock;
}
public void setLock(boolean lock) {
this.lock = lock;
}
public String getLockKey() {
return lockKey;
}
public void setLockKey(String lockKey) {
this.lockKey = LOCK_PREFIX + lockKey;
}
public int getLockExpirseTimeout() {
return lockExpirseTimeout;
}
public void setLockExpirseTimeout(int lockExpirseTimeout) {
this.lockExpirseTimeout = lockExpirseTimeout;
}
public int getLockWaitTimeout() {
return lockWaitTimeout;
}
public void setLockWaitTimeout(int lockWaitTimeout) {
this.lockWaitTimeout = lockWaitTimeout;
}
public RedisLock() {
}
public RedisLock(String lockKey, int lockExpirseTimeout, int lockWaitTimeout) {
redisConfig = new StoreConfig();
this.redisStoreManager = RedisStoreManager.getInstance(redisConfig);
redisStoreManager.initialization();
this.cluster = redisStoreManager.getCluster();
this.lockKey = LOCK_PREFIX + lockKey;
this.lockExpirseTimeout = lockExpirseTimeout;
this.lockWaitTimeout = lockWaitTimeout;
}
public boolean lock(){
int timeout = lockWaitTimeout;
while (timeout >= 0){
Long expires = System.currentTimeMillis() + lockExpirseTimeout + 1;
String expiresStr = String.valueOf(expires);
if (cluster.setnx(lockKey,expiresStr)==1){
lock = true;
return true;
}
String lockTimeStr = cluster.get(lockKey);
if (lockTimeStr != null && Long.parseLong(lockTimeStr) < System.currentTimeMillis()){
String oldLockTimeStr = cluster.getSet(lockKey,expiresStr);
if (oldLockTimeStr != null && oldLockTimeStr.equals(lockTimeStr)){
lock = true;
return true;
}
}
int sleepTime=new Random().nextInt(10)*100;
timeout -= sleepTime;
try {
Thread.sleep(sleepTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
return false;
}
public void unlock(){
if (lock){
cluster.del(lockKey);
lock = false;
}
}
}
把锁的超时时间当作value的值,每次线程需要锁,如果别的线程没有拥有锁,它立马获得锁,如果别的线程已经拥有锁了,就把超时时间取出来与系统现在的时间对比看是否超时了,如果超时了就尝试获得该锁,如果锁还没超时和释放,就休眠随机的时间,再尝试获得锁直到获得锁或timeout。
到这里只是实现,那思考去哪了呢,下面是当初我在测试这个锁的时候的一个错误的做法。
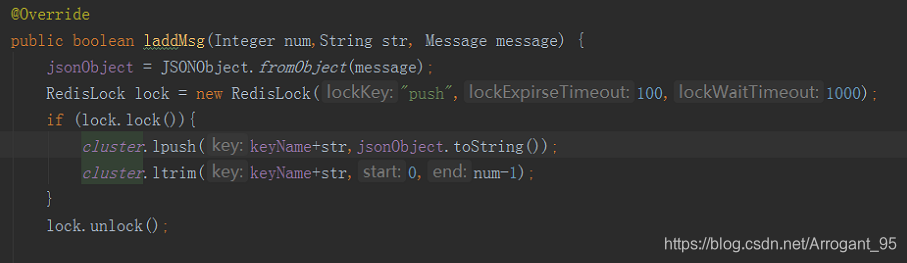
为了想保持最新的一定数量的值,避免在并发下lpush方法执行了但ltrim还没执行的时候取数据,这时候肯定比规定的数据要多的情况,这里使用了锁,然后测试代码如下:
public void RedisTest3() throws InterruptedException {
final CountDownLatch count = new CountDownLatch(150);
StoreConfig redisConfig = new StoreConfig();
redisConfig.setNodes("集群节点***.*.*.*:***");
RedisStoreUtil redisStoreUtil = new RedisStoreUtil(redisConfig,"llock");
redisStoreUtil.delete("150");
Message message = new Message();
ThreadPoolExecutor executor = new ThreadPoolExecutor(6, 10, 2000, TimeUnit.MILLISECONDS, new LinkedBlockingDeque<>(1000));
for (int i =0;i< 150;i++){
// Thread t = new Thread(new MyTask(i,redisStoreUtil,count));
// t.start();
MyTask mt = new MyTask(i,redisStoreUtil,count);
executor.execute(mt);
}
count.await();
executor.shutdown();
Collection<Message> al = redisStoreUtil.lgetAllMsg("150",100);
System.out.println(al.size());
Iterator it = al.iterator();
while (it.hasNext()){
System.out.println(it.next().toString());
}
class MyTask implements Runnable {
private int taskNum;
private RedisStoreUtil redisStoreUtil;
private Message message = new Message();
private CountDownLatch count;
public MyTask(int num,RedisStoreUtil redisStoreUtil,CountDownLatch count) {
this.taskNum = num;
this.redisStoreUtil = redisStoreUtil;
this.count = count;
}
@Override
public void run() {
System.out.println("正在执行task "+taskNum);
message.setMsgId(taskNum);
redisStoreUtil.laddMsg(100,"150",message); //调用上面加锁的方法
count.countDown();
}
}
}
这里使用了线程池来测试,往里面存150个数据,用不同的ID号代表不同的数据,保留最新的100个数据,等待所有线程结束再取数据,看上去貌似没有问题,然后问题来了,最后取出来的数据确实是100个,但最后的几个的ID都是一样的。
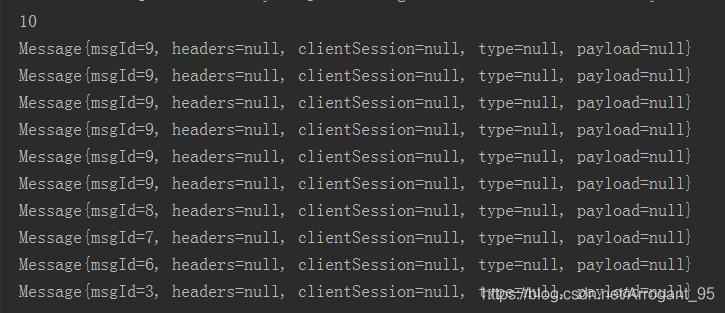
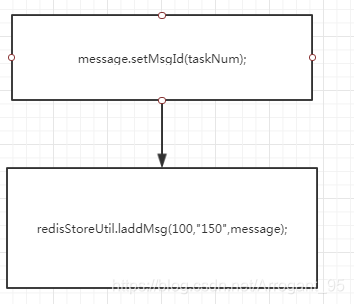
这个是我保存最新的10个数据时的测试图,难道是我写的锁实现有问题?没锁住,还是我的测试方式有问题?后来我终于发现问题所在了,之前为了偷懒只生成一个Message,通过修改它的ID来当作不同的数据,因为等待锁需要耗费时间,所以在 redisStoreUtil.laddMsg(100,“150”,message); 这个地方停得比较久,本来应该是这样的
但是机器却等不及了,先执行下一个线程task,从而修改了上一个线程本来要存的数据,变成了这个样子
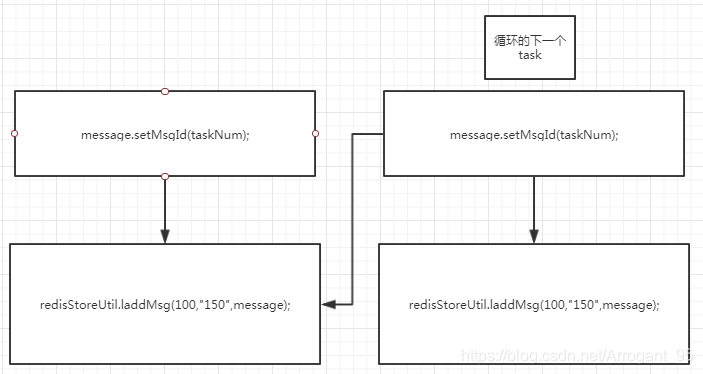
所以结果才会那么多个最后一个ID的数据,如果后面的操作不会影响前面要存入的数据,那么就不会发生这种情况。
这个redisLock代码并没有放到GitHub上,因为加锁太影响性能了,加了锁之后慢了10几秒,只要在取的时候限定取多少个就不会发生多取的情况,具体的代码和操作细节可联系我。如果您对我们的JMQTT项目感兴趣的话可以在GitHub上watch和star一下,地址:https://github.com/Cicizz/jmqtt














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









