







 Pattern是一个用于网络数据挖掘的Python库,包含多个模块,如pattern.web用于网络抓取,pattern.en处理英文文本,pattern.search进行词汇检索,pattern.vector进行分类,pattern.graph用于数据可视化。本文重点介绍了潜在语义分析(LSA),它通过SVD实现降维,将相关特征组合成概念。此外,还探讨了LSA在聚类和分类任务中的应用,以及分类算法如Naive Bayes、KNN、SLP和SVM。
Pattern是一个用于网络数据挖掘的Python库,包含多个模块,如pattern.web用于网络抓取,pattern.en处理英文文本,pattern.search进行词汇检索,pattern.vector进行分类,pattern.graph用于数据可视化。本文重点介绍了潜在语义分析(LSA),它通过SVD实现降维,将相关特征组合成概念。此外,还探讨了LSA在聚类和分类任务中的应用,以及分类算法如Naive Bayes、KNN、SLP和SVM。
http://www.clips.ua.ac.be/pattern
pattern是一个网络数据挖掘的一个工具,分为几个模块
pattern.web 是用来在网络抓取数据的,
pattern.en 是用来处理英文文本的
pattern.search是用来检索特定规律的词汇的
pattern.vector是用来分类的
pattern.graph用了d3的模块,可以用来可视化展现。
Latent semantic analysis(潜在语义分析)
Latent Semantic Analysis (LSA) is a statistical technique based on singular value decomposition (SVD). [1] [2]. It groups related features in the model into concepts (e.g., purr + fur + claw = feline concept). This is called dimensionality reduction. Each document in the model then gets a concept vector, a compressed approximation of the original vector that may be faster for cosine similarity, clustering and classification.
潜在语义分析(LSA)是一个基于奇异值分解的统计方法。它在模型中将相关特征关联成概念(比如咕噜+毛+爪子=猫科 概念)。这被称为降维。模型中的每个文档都有一个概念矩阵,一个对原始向量的近似压缩使得余弦相似度和聚类以及分类算法更快。
SVD requires the Python NumPy package (installed by default on Mac OS X). Given a matrix of documents × features, it yields a matrix U with documents × concepts, a diagonal matrix Σ with singular values, and a matrix Vtwith concepts × features.
SVD要求有NumPy的python包(Mac OS是默认安装的)。给定一个 文档 ×特征 的矩阵,生成U,用奇异值生成对角矩阵Σ,一个矩阵Vt。
from
numpy.linalg
import
svd
from
numpy
import
dot, diag
u, sigma, vt = svd(matrix, full_matrices=
False
)
for
i
in
range
(-k,
0
):
sigma[i] =
0
# Reduce k smallest singular values.
matrix = dot(u, dot(diag(sigma), vt))
|
Reference: Wilk J. (2007). http://blog.josephwilk.net/projects/latent-semantic-analysis-in-python.html
|
|
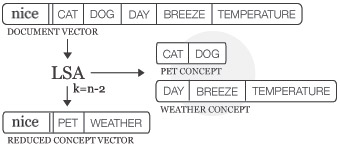
LSA concept space
The Model.reduce() method calculates SVD and stores the concept space in Model.lsa. The optional dimensions parameter defines the number of dimensions in the concept space: TOP300, L1,L2 (default), an int or a function. There is no universal optimal value, too many dimensions may result in noise while too few may remove useful information.
Model.reduce()函数计算SVD以及在Model.lsa存储概念空间。 可选择的dementions 参数定义了概念空间中的维度的数量:Top 300,L1,L2(默认),一个int或者一个function。没有全局优化值,太多维度可能导致 噪声,太少可能导致信息无用。
When Model.lsa is set, Model.similarity(), neighbors(), search() and cluster() will subsequently compute in LSA concept space. To undo the reduction, set Model.lsa to None. Adding or removing documents in the model will also undo the reduction.
Model.lsa是一个set,Model.similarity(), neighbors(), search() and cluster()在LSA概念空间中紧接着被计算。为了撤销减少,可以设置Model.lsa为None,添加或者删除模型中的文档也会导致降维。
lsa = Model.
reduce
(dimensions=L2)
|
lsa = Model.lsa
|
lsa = LSA(model, k=L2)
|
lsa.model
# Parent Model.
lsa.features
# List of features, same as Model.features.
lsa.concepts
# List of concepts, each a {feature: weight} dict.
lsa.vectors
# {Document.id: {concept_index: weight}}
|
lsa.transform(document)
|
| Dimensions | Description |
| TOP300 | Keep the top 300 dimensions (rule of thumb). |
| L1 | L1-norm of the singular values as the number of dimensions to remove. |
| L2 | L2-norm of the singular values as the number of dimensions to remove. |
| int | An int that is the number of dimensions to remove. |
| function | A function that takes the list of singular values and returns an int. |
LSA.transform() takes a Document and returns its Vector in concept space. This is useful for documents that are not part of the model – see also Classifier.classify().
LSA.transform() 输入Document 返回概念空间里的Vector 。这对于不在模型中的文档非常有用,同样可以见 Classifier.classify().
The following example demonstrates how related features are grouped after LSA:
以下例子展示的是相关特征怎么被LSA分组
>>>
from
pattern.vector
import
Document, Model
>>>
>>> d1 = Document(
'The cat purrs.'
, name=
'cat1'
)
>>> d2 = Document(
'Curiosity killed the cat.'
, name=
'cat2'
)
>>> d3 = Document(
'The dog wags his tail.'
, name=
'dog1'
)
>>> d4 = Document(
'The dog is happy.'
, name=
'dog2'
)
>>>
>>> m = Model([d1, d2, d3, d4])
>>> m.
reduce
(
2
)
>>>
>>>
for
d
in
m.documents:
>>>
print
>>>
print
d.name
>>>
for
concept, w1
in
m.lsa.vectors[d.
id
].items():
>>>
for
feature, w2
in
m.lsa.concepts[concept].items():
>>>
if
w1 !=
0
and
w2 !=
0
:
>>>
print
(feature, w1 * w2)
|
The model is reduced to two dimensions. So there are two concepts in the concept space. Each document has a concept vector with weights for each concept. As illustrated below, cat features have been grouped together and dog features have been grouped together.
model减为二维,在概念空间中有两个概念,每个文档都有一个概念向量,向量里面是每个概念的权重,就像下面展示的,猫的概念和狗的概念。(应该0是狗的概念,1是猫的概念吧?)
| concept | cat | curiosity | dog | happy | killed | purrs | tail | wags |
| 0 | 0.00 | 0.00 | +0.52 | +0.78 | 0.00 | 0.00 | +0.26 | +0.26 |
| 1 | -0.52 | -0.26 | 0.00 | 0.00 | -0.26 | -0.78 | 0.00 | 0.00 |
| concept | d1 (cat1) | d2 (cat2) | d3 (dog1) | d4 (dog2) |
| 0 | 0.00 | 0.00 | +0.45 | +0.90 |
| 1 | -0.90 | -0.45 | 0.00 | 0.00 |
Dimensionality reduction is useful with Model.cluster(). Clustering algorithms are exponentially slow (i.e., 3 nested for-loops). Clustering a model of a 1,000 documents with a 1,000 features takes a couple of minutes. However, it takes a couple of seconds to reduce this model to concept vectors with a 100 features, after which k-means clustering also runs in a couple of seconds. Note that document vectors are stored in sparse format (i.e., features with weight 0.0 are omitted), so it is often not necessary to reduce the model. Even if the model has a 1,000 features, each document might have no more than 5-10 features. To get an idea of the average document vector length:
降维对于Model.cluster()非常有用。聚类算法指数降低。聚类一个1000个拥有1000features的文档的model需要几分钟,然而,降维到100概念向量之后只用几秒钟,在降维之后,K-means聚类只用几秒钟。注意到文档向量用稀疏形式存储(比如权重为0的特征被忽略),所以降维也不一定非有必要。
sum(len(d.vector) for d in model.documents) / float(len(model))
ClusteringClustering is an unsupervised machine learning method that can be used to partition a set of unlabeled documents (i.e., Document objects without a type). Since the label (class, type, category) of a document is not known, clustering will attempt to create clusters (categories) of similar documents by measuring the distance between the document vectors. The optimal solution is then a set of dense clusters, where each cluster is made up of documents with the smallest possible distance between them.
Say we have a number of 2D points with coordinates x and y (horizontal and vertical position). Some points will be further apart than others. The figure below illustrates how we can partition the points by measuring their distance to two centroids. More centroids create more clusters. The principle holds for 3D points with x, y and z coordinates, or any n-D points (x, y, z, ..., n). This is how the k-means clustering algorithm works. A Document.vector is an n-dimensional point. Instead of coordinates x and y it has n features (words) and feature weights. We can calculate the distance between document vectors with cosine similarity.
 random points in 2D random points in 2D |
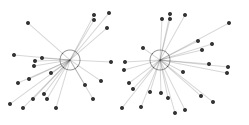 points by distance to centroid points by distance to centroid |
The Model.cluster() method returns a list of clusters using the KMEANS or the HIERARCHICAL algorithm. The optional distance parameter can be COSINE (default), EUCLIDEAN, MANHATTAN or HAMMING. An optionaldocuments parameter can be a selective list of documents in the model to cluster.
clusters = Model.cluster(method=KMEANS, k=
10
, iterations=
10
, distance=COSINE)
|
clusters = Model.cluster(method=HIERARCHICAL, k=
1
, iterations=
1000
, distance=COSINE)
|
>>>
from
pattern.vector
import
Document, Model, HIERARCHICAL
>>>
>>> d1 = Document(
'Cats are independent pets.'
, name=
'cat'
)
>>> d2 = Document(
'Dogs are trustworthy pets.'
, name=
'dog'
)
>>> d3 = Document(
'Boxes are made of cardboard.'
, name=
'box'
)
>>>
>>> m = Model((d1, d2, d3))
>>>
print
m.cluster(method=HIERARCHICAL, k=
2
)
Cluster([
Document(
id
=
3
, name=
'box'
),
Cluster([
Document(
id
=
2
, name=
'dog'
),
Document(
id
=
1
, name=
'cat'
)
])
])
|
k-means clustering
The k-means clustering algorithm partitions a set of unlabeled documents into k clusters, using k random centroids. It returns a list containing k lists of similar documents.
Model.cluster(method=KMEANS, k=
10
, iterations=
10
, distance=COSINE, seed=RANDOM, p=
0.8
)
|
The advantage of k-means is that it is fast. The drawback is that an optimal solution is not guaranteed, since the position of the centroids is random. Each iteration, the algorithm will swap documents between clusters to create denser clusters.
The optional seed parameter be RANDOM or KMPP. The KMPP or k-means++ initialization algorithm can be used to find better centroids. In many cases this is also faster. The optional parameter p sets the "relaxation" of the k-means algorithm. Relaxation is based on a mathematical trick called triangle inequality, where p=0.5is stable but slow and p=1.0 is prone to errors but faster, especially for higher k and document vectors with many features (i.e., higher dimensionality).
References:
Arthur, D. (2007). k-means++: the advantages of careful seeding. SODA'07 Proceedings.
Elkan, C. (2003). Using the Triangle Inequality to Accelerate k-Means. ICML'03 Proceedings.
Hierarchical clustering
The hierarchical clustering algorithm returns a tree of nested clusters. The top level item is a Cluster, a mixed list of Document and (nested) Cluster objects.
Model.cluster(method=HIERARCHICAL, k=
1
, iterations=
1000
, distance=COSINE)
|
The advantage of hierarchical clustering is that the optimal solution is guaranteed. Each iteration, the algorithm will cluster the two nearest documents. The drawback is that it is slow.
A Cluster is a list of Document and Cluster objects, with some additional properties:
cluster = Cluster([])
|
cluster.depth
# Returns the maximum depth of nested clusters.
cluster.flatten(depth=
1000
)
# Returns a flat list, down to the given depth.
cluster.traverse(visit=
lambda
cluster:
None
)
|
>>>
from
pattern.vector
import
Cluster
>>>
>>> cluster = Cluster((
1
, Cluster((
2
, Cluster((
3
,
4
))))))
>>>
print
cluster.depth
>>>
print
cluster.flatten(
1
)
2
[
1
,
2
, Cluster([
3
,
4
])]
|
Note: the maximum recursion depth in Python is 1,000. For deeper clusters, raise sys.setrecursionlimit().
Centroid
The centroid() function takes a Cluster, or a list of Cluster, Document and Vector objects, and returns the mean Vector. The distance() function returns the distance between two vectors. A common problem is that a cluster has no meaningful descriptive name. One solution is to calculate its centroid, and use theDocument.type of the document vector(s) nearest to the centroid.
centroid(vectors=[])
# Returns the mean Vector.
|
distance(v1, v2, method=COSINE)
# COSINE | EUCLIDEAN | MANHATTAN | HAMMING
|
Classification
Classification can be used to predict the label of an unlabeled document. More specifically, classification is a supervised machine learning method that uses labeled documents (i.e., Document objects with a type) as training examples to statistically predict the label (class, type) of new documents, based on their similarity to the training examples using a distance metric (e.g., cosine similarity). A Document is a bag-of-words representation of a text, i.e., unordered words + word count. The Document.vector maps the words (or features) to their weight (absolute or relative word count, tf-idf, ...). The weight of a word represents its relevancy in the text. So we can compare how similar two documents are by measuring if they have relevant words in common. Given an unlabeled document, a classifier yields the label of the most similar document(s) in its training set. This implies that a larger training set with more features (and less labels) gives better performance.
分类器能够用来标签未标签的文档。更特别的,分类器是一种监督的机器学习方法,用已经标签的文档(比如Document和type)作为训练集去统计性地预测新文档的标签(class,type)。文档是文本的词袋表示。
For example, if we have a corpus of product reviews (training data) for which the star rating of each product review is known (labels, e.g., ★★★☆☆ = 3), we can use it to predict the star rating of other reviews, based on common words (features) in the text. We could represent each review as a vector of adjectives (e.g., good, bad, awesome, awful, ...) since positive reviews (good, awesome) will most likely contain different adjectives than negative reviews (bad, awful).
The pattern.vector module implements four classification algorithms:
- NB: Naive Bayes, based on the probability that a feature occurs in a class.
- KNN: k-nearest neighbor, based on the k most similar documents in the training set.
- SLP: single-layer averaged perceptron, based on an artificial neural network.
- SVM: support vector machine, based on a representation of the documents in a high-dimensional space separated by hyperplanes (see further).
classifier = NB(train=[], baseline=MAJORITY, method=MULTINOMIAL, alpha=
0.0001
)
|
classifier = KNN(train=[], baseline=MAJORITY, k=
10
, distance=COSINE)
|
classifier = SLP(train=[], baseline=MAJORITY, iterations=
1
)
|
classifier = SVM(train=[],
type
=CLASSIFICATION, kernel=LINEAR)
|
Classifier
The NB, KNN, SLP and SVM classifiers inherit from the Classifier base class:
classifier = Classifier(train=[], baseline=MAJORITY)
|
classifier = Classifier.load(path)
|
classifier.features
# List of trained features (words).
classifier.classes
|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









