







数据库版本:
test=# select version();
version
----------------------------------------------------------------------------------------------------------------------
KingbaseES V008R006C005B0041 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.1.2 20080704 (Red Hat 4.1.2-46), 64-bit
(1 row)
主机节点信息:
[kingbase@node101 bin]$ cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.101 node101 #原主库
192.168.1.102 node102 #原备库
集群节点信息:
ID | Name | Role | Status | Upstream | repmgrd | PID | Paused? | Upstream last seen
----+---------+---------+-----------+----------+---------+-------+---------+--------------------
1 | node101 | primary | * running | | running | 11180 | no | n/a
2 | node102 | standby | running | node101 | running | 9242 | no | 0 second(s) ago
一、查看集群状态及配置信息
1、集群节点状态
[kingbase@node101 bin]$ ./repmgr cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+----------------------------------------------------------------------------------------------------------------------------------------------------
1 | node101 | primary | * running | | default | 100 | 1 | host=192.168.1.101 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node102 | standby | running | node101 | default | 100 | 1 | host=192.168.1.102 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2、集群配置信息

二、将主库网卡down测试
1、主库网卡down
[root@node101 ~]# ifconfig enp0s3 down
2、主库messages日志
Mar 29 16:39:47 node101 avahi-daemon[782]: Interface enp0s3.IPv4 no longer relevant for mDNS.
Mar 29 16:39:47 node101 avahi-daemon[782]: Leaving mDNS multicast group on interface enp0s3.IPv4 with address 192.168.1.101.
Mar 29 16:39:47 node101 avahi-daemon[782]: Withdrawing address record for fe80::a00:27ff:fe73:47f6 on enp0s3.
Mar 29 16:39:47 node101 avahi-daemon[782]: Withdrawing address record for 192.168.1.101 on enp0s3.
3、备库hamgr.log日志
=== 从以下日志看,可以分成两部分===
1)备库和主库的PQping测试失败,超过阈值后,触发主备切换。
2)由于recovery=‘automatic’,则对主库进行recovery,将原主库作为备库加入到集群。由于主库网卡down,备库一直尝试连接原主库,当原主库网络正常后,recovery成功。
[2022-03-29 16:36:52] [INFO] node "node102" (ID: 2) monitoring upstream node "node101" (ID: 1) in normal state
[2022-03-29 16:39:58] [WARNING] unable to ping "host=192.168.1.101 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3"
[2022-03-29 16:39:58] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2022-03-29 16:39:58] [WARNING] unable to connect to upstream node "node101" (ID: 1)
[2022-03-29 16:39:58] [INFO] sleeping 6 seconds until next reconnection attempt
[2022-03-29 16:40:04] [INFO] checking state of node 1, 1 of 10 attempts
......
[2022-03-29 16:41:52] [INFO] checking state of node 1, 10 of 10 attempts
[2022-03-29 16:41:53] [WARNING] unable to ping "user=system connect_timeout=10 dbname=esrep host=192.168.1.101 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr"
[2022-03-29 16:41:53] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2022-03-29 16:41:53] [WARNING] unable to reconnect to node 1 after 10 attempts
[2022-03-29 16:41:53] [NOTICE] setting "wal_retrieve_retry_interval" to 86405000 milliseconds
[2022-03-29 16:41:53] [WARNING] wal receiver not running
[2022-03-29 16:41:53] [NOTICE] WAL receiver disconnected on all sibling nodes
[2022-03-29 16:41:53] [INFO] WAL receiver disconnected on all 0 sibling nodes
[2022-03-29 16:41:53] [INFO] 0 active sibling nodes registered
[2022-03-29 16:41:53] [INFO] primary and this node have the same location ("default")
[2022-03-29 16:41:53] [INFO] no other sibling nodes - we win by default
[2022-03-29 16:41:53] [NOTICE] setting "wal_retrieve_retry_interval" to 5000 ms
[2022-03-29 16:41:53] [NOTICE] this node is the only available candidate and will now promote itself
[2022-03-29 16:41:53] [INFO] try to ping the trusted_servers "192.168.1.1" before execute promote_command
[2022-03-29 16:41:55] [NOTICE] PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
--- 192.168.1.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1999ms
rtt min/avg/max/mdev = 0.204/0.237/0.296/0.045 ms
[2022-03-29 16:41:55] [NOTICE] successfully ping one or more of the trusted_servers "192.168.1.1"
[2022-03-29 16:41:55] [INFO] promote_command is:
"/home/kingbase/cluster/R6HA/kha/kingbase/bin/repmgr standby promote -f /home/kingbase/cluster/R6HA/kha/kingbase/etc/repmgr.conf"
NOTICE: promoting standby to primary
DETAIL: promoting server "node102" (ID: 2) using sys_promote()
NOTICE: waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete
NOTICE: STANDBY PROMOTE successful
DETAIL: server "node102" (ID: 2) was successfully promoted to primary
[2022-03-29 16:41:57] [INFO] switching to primary monitoring mode
[2022-03-29 16:41:57] [NOTICE] monitoring cluster primary "node102" (ID: 2)
[2022-03-29 16:41:57] [INFO] create a thread 0x7f9ae9028700 to check the cluster status
[2022-03-29 16:41:57] [INFO] child node: 1; attached: no
[2022-03-29 16:41:57] [INFO] check node status again, try 1 / 10 times
......
[2022-03-29 16:42:15] [INFO] check node status again, try 10 / 10 times
[2022-03-29 16:42:17] [WARNING] [thread 0x7f9ae9028700] unable to connect via ES to host "192.168.1.101"
[2022-03-29 16:42:17] [INFO] child node: 1; attached: no
[2022-03-29 16:42:17] [INFO] found node down, recovery will be triggered after recovery delay time 20s
[2022-03-29 16:42:19] [INFO] child node: 1; attached: no
.......
[2022-03-29 16:42:27] [INFO] child node: 1; attached: no
[2022-03-29 16:42:29] [WARNING] [thread 0x7f9ae9028700] unable to connect via ES to host "192.168.1.101"
[2022-03-29 16:42:29] [INFO] child node: 1; attached: no
.......
[2022-03-29 16:42:37] [INFO] child node: 1; attached: no
[2022-03-29 16:42:37] [INFO] recovery delay time reached. can do recovery now.
[2022-03-29 16:42:37] [INFO] [thread pid:2995] do_nodes_recovery thread begin. The pthread_t tid is 0x7f9ae9829700
[2022-03-29 16:42:37] [NOTICE] [thread pid:2995] node (ID: 1; host: "192.168.1.101") is not attached, ready to auto-recovery
[2022-03-29 16:42:41] [NOTICE] [thread pid:2995] Now, the primary host ip: 192.168.1.102
[2022-03-29 16:42:47] [WARNING] unable to connect to remote host "192.168.1.101" via ES
[2022-03-29 16:42:47] [NOTICE] [thread pid:2995] node "node101" (ID: 1) auto-recovery failed: unable to connect via ES to host "192.168.1.101", user "", do nothing
[2022-03-29 16:42:47] [WARNING] [thread pid:2995] node (ID: 1) auto-recovery failed: unable to connect via ES to host "192.168.1.101", user "", do nothing
[2022-03-29 16:42:47] [INFO] [thread pid:2995] Is standby node "node101" (ID: 1) ready for connection?
[2022-03-29 16:42:53] [ERROR] [thread pid:2995] standby node "node101" (ID: 1) connected ... FAILED
[2022-03-29 16:42:53] [DETAIL] [thread pid:2995] could not connect to server: No route to host
Is the server running on host "192.168.1.101" and accepting
TCP/IP connections on port 54321?
......
[2022-03-29 16:44:05] [ERROR] [thread pid:3259] standby node "node101" (ID: 1) connected ... FAILED
[2022-03-29 16:44:05] [DETAIL] [thread pid:3259] could not connect to server: No route to host
Is the server running on host "192.168.1.101" and accepting
TCP/IP connections on port 54321?
[2022-03-29 16:44:05] [INFO] [thread pid:3259] do_nodes_recovery thread ends. The pthread_t tid is 0x7f9ae9829700
[2022-03-29 16:44:05] [WARNING] [thread 0x7f9ae9028700] unable to connect via ES to host "192.168.1.101"
[2022-03-29 16:44:06] [INFO] thread tid:0x7f9ae9829700 is not running
[2022-03-29 16:44:06] [INFO] the recovery thread was exited, reset tid
[2022-03-29 16:44:06] [INFO] child node: 1; attached: no
[2022-03-29 16:44:06] [INFO] found node down, recovery will be triggered after recovery delay time 20s
[2022-03-29 16:44:07] [NOTICE] [thread 0x7f9ae9028700] the TimeLineID (1) of node (ID: 1) is smaller than the TimeLineID (2) of local node (ID: 2)
[2022-03-29 16:44:07] [NOTICE] [thread 0x7f9ae9028700] try to stop primary db on node (ID: 1, host: "192.168.1.101")
[2022-03-29 16:44:06] [INFO] stop database ...
[2022-03-29 16:44:07] [INFO] stop db done.
[2022-03-29 16:44:08] [NOTICE] [thread 0x7f9ae9028700] success to stop primary db on node (ID: 1, host: "192.168.1.101")
[2022-03-29 16:44:08] [INFO] child node: 1; attached: no
[2022-03-29 16:44:10] [INFO] child node: 1; attached: no
[2022-03-29 16:44:11] [INFO] node (ID: 1): no server running
[2022-03-29 16:44:11] [INFO] [thread 0x7f9ae9028700] the cluster has no other running primary node, exit
[2022-03-29 16:44:12] [INFO] child node: 1; attached: no
.......
[2022-03-29 16:44:26] [INFO] child node: 1; attached: no
[2022-03-29 16:44:26] [INFO] recovery delay time reached. can do recovery now.
[2022-03-29 16:44:26] [INFO] [thread pid:3662] do_nodes_recovery thread begin. The pthread_t tid is 0x7f9ae9028700
[2022-03-29 16:44:26] [NOTICE] [thread pid:3662] node (ID: 1; host: "192.168.1.101") is not attached, ready to auto-recovery
[2022-03-29 16:44:26] [NOTICE] [thread pid:3662] Now, the primary host ip: 192.168.1.102
[2022-03-29 16:44:27] [INFO] [thread pid:3662] ES connection to host "192.168.1.101" succeeded, ready to do auto-recovery
[2022-03-29 16:44:27] [INFO] unlink file /tmp/.s.KINGBASE.54321.lock
### 执行“repmgr standby rejoin --force-rewind”,对主库执行recovery。
[2022-03-29 16:44:27] [NOTICE] executing repmgr command "/home/kingbase/cluster/R6HA/kha/kingbase/bin/repmgr --dbname="host=192.168.1.102 dbname=esrep user=system port=54321" node rejoin --force-rewind"
NOTICE: sys_rewind execution required for this node to attach to rejoin target node 2
DETAIL: rejoin target server's timeline 2 forked off current database system timeline 1 before current recovery point 0/7000028
NOTICE: executing sys_rewind
DETAIL: sys_rewind command is "/home/kingbase/cluster/R6HA/kha/kingbase/bin/sys_rewind -D '/home/kingbase/cluster/R6HA/kha/kingbase/data' --source-server='host=192.168.1.102 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3'"
sys_rewind: servers diverged at WAL location 0/6001210 on timeline 1
sys_rewind: rewinding from last common checkpoint at 0/5000498 on timeline 1
sys_rewind: find last common checkpoint start time from 2022-03-29 16:44:27.204902 CST to 2022-03-29 16:44:27.308161 CST, in "0.103259" seconds.
sys_rewind: update the control file: minRecoveryPoint is '0/600FE20', minRecoveryPointTLI is '2', and database state is 'in archive recovery'
sys_rewind: we will remove the dir '/home/kingbase/cluster/R6HA/kha/kingbase/data/sys_replslot/repmgr_slot_2.rewind' and all the file/dir in it.
sys_rewind: rewind start wal location 0/5000468 (file 000000010000000000000005), end wal location 0/600FE20 (file 000000020000000000000006). time from 2022-03-29 16:44:27.204902 CST to 2022-03-29 16:44:28.615051 CST, in "1.410149" seconds.
sys_rewind: Done!
NOTICE: 0 files copied to /home/kingbase/cluster/R6HA/kha/kingbase/data
NOTICE: setting node 1's upstream to node 2
WARNING: unable to ping "host=192.168.1.101 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3"
DETAIL: PQping() returned "PQPING_NO_RESPONSE"
NOTICE: begin to start server at 2022-03-29 16:44:28.628597
NOTICE: starting server using "/home/kingbase/cluster/R6HA/kha/kingbase/bin/sys_ctl -w -t 90 -D '/home/kingbase/cluster/R6HA/kha/kingbase/data' -l /home/kingbase/cluster/R6HA/kha/kingbase/bin/logfile start"
NOTICE: start server finish at 2022-03-29 16:44:29.034402
NOTICE: NODE REJOIN successful
DETAIL: node 1 is now attached to node 2
[2022-03-29 16:44:29] [NOTICE] kbha: node (ID: 1) rejoin success.
[2022-03-29 16:44:29] [NOTICE] [thread pid:3662] node "node101" (ID: 1) auto-recovery success
[2022-03-29 16:44:29] [INFO] [thread pid:3662] Is standby node "node101" (ID: 1) ready for connection?
[2022-03-29 16:44:29] [INFO] [thread pid:3662] the standby node "node101" (ID: 1) connected ... OK
[2022-03-29 16:44:29] [INFO] [thread pid:3662] do_nodes_recovery thread ends. The pthread_t tid is 0x7f9ae9028700
[2022-03-29 16:44:30] [INFO] SET synchronous TO "quorum" on primary host
[2022-03-29 16:44:30] [INFO] thread tid:0x7f9ae9028700 is not running
[2022-03-29 16:44:30] [INFO] the recovery thread was exited, reset tid
[2022-03-29 16:44:30] [NOTICE] Some nodes reconnect, all standby nodes are OK now
[2022-03-29 16:44:34] [NOTICE] new standby "node101" (ID: 1) has connected
[2022-03-29 16:46:57] [INFO] monitoring primary node "node102" (ID: 2) in normal state
三、主库网卡恢复正常(up)
1、查看备库hamgr.log日志
=如下所示,原主库网卡up后,因为recovery=‘automatic’,对原主库执行recovery,作为新备库加入到集群。=
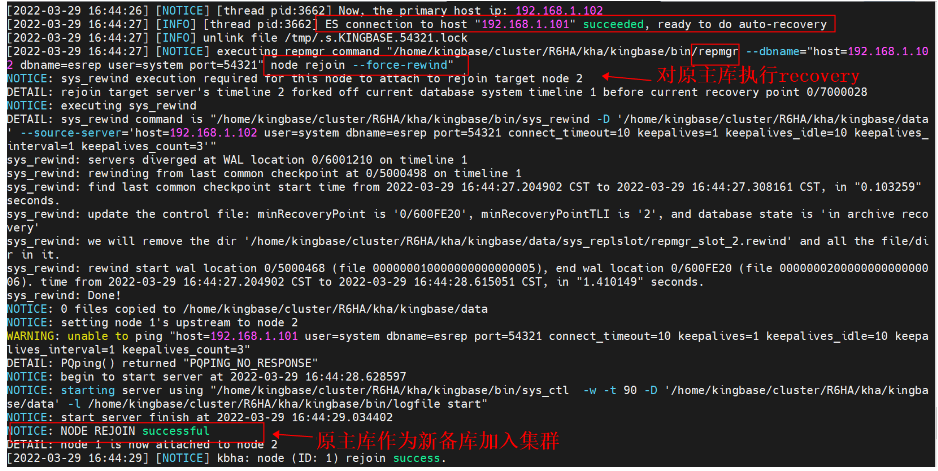
2、查看集群状态信息
=== 如下图所示,主备发生了切换,并且原主库作为新备库加入到集群。===

四、总结
1、对于主库,网卡down后,备库无法和主库通讯,超过阈值后,会触发集群主备切换。
2、对于参数recovery='automatic‘配置,主库网卡恢复正常后,集群执行recovery,将原主库作为新的备库加入到集群中。















 894
894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









