







算法的时间复杂度定义为:
在进行算法分析时,语句总的执行次数T(n)是关于问题规模n的函数,进而分析T(n)随n的变化情况并确定T(n)的数量级。算法的时间复杂度,也就是算法的时间量度,记作:T(n}=0(f(n))。它表示随问题规模n的增大,算法执行时间的埔长率和 f(n)的埔长率相同,称作算法的渐近时间复杂度,简称为时间复杂度。其中f( n)是问题规横n的某个函数。
根据定义,求解算法的时间复杂度的具体步骤是:
⑴ 找出算法中的基本语句;
算法中执行次数最多的那条语句就是基本语句,通常是最内层循环的循环体。
⑵ 计算基本语句的执行次数的数量级;
只需计算基本语句执行次数的数量级,这就意味着只要保证基本语句执行次数的函数中的最高次幂正确即可,可以忽略所有低次幂和最高次幂的系数。这样能够简化算法分析,并且使注意力集中在最重要的一点上:增长率。
⑶ 用大Ο记号表示算法的时间性能。
将基本语句执行次数的数量级放入大Ο记号中。
如何推导大o阶呢?我们给出了下面 的推导方法:
1.用常数1取代运行时间中的所有加法常数。
2.在修改后的运行次数函数中,只保留最髙阶项。
3.如果最高阶项存在且不是1,则去除与这个项相乘的常数。
简单的说,就是保留求出次数的最高次幂,并且把系数去掉。 如T(n)=2n^2+n+1 =O(n^2)
举个例子。
按照上面推导“大O阶”的步骤,我们来看
第一步:“用常数 1 取代运行时间中的所有加法常数”,
则上面的算式变为:执行总次数 =3n^2 + 3n + 1
(直接相加的话,应该是T(n) = 1 + n+1 + n + n*(n+1) + n*n + n*n + 1 = 3n^2 + 3n + 3。现在用常数 1 取代运行时间中的所有加法常数,就是把T(n) = 3n^2 + 3n + 3中的最后一个3改为1. 就得到了 T(n) = 3n^2 + 3n + 1)
第二步:“在修改后的运行次数函数中,只保留最高阶项”。
这里的最高阶是 n 的二次方,所以算式变为:执行总次数 = 3n^2
第三步:“如果最高阶项存在且不是 1 ,则去除与这个项相乘的常数”。
这里 n 的二次方不是 1 所以要去除这个项的相乘常数,算式变为:执行总次数 = n^2
因此最后我们得到上面那段代码的算法时间复杂度表示为: O( n^2 )
下面我把常见的算法时间复杂度以及他们在效率上的高低顺序记录在这里,使大家对算法的效率有个直观的认识。
O(1) 常数阶 < O(logn) 对数阶 < O(n) 线性阶 < O(nlogn) < O(n^2) 平方阶 < O(n^3) < { O(2^n) < O(n!) < O(n^n) }
最后三项用大括号把他们括起来是想要告诉大家,如果日后大家设计的算法推导出的“大O阶”是大括号中的这几位,那么趁早放弃这个算法,在去研究新的算法出来吧。因为大括号中的这几位即便是在 n 的规模比较小的情况下仍然要耗费大量的时间,算法的时间复杂度大的离谱,基本上就是“不可用状态”。
好了,原理就介绍到这里了。下面通过几个例子具体分析下时间复杂度计算过程。
一。计算 1 + 2 + 3 + 4 + ...... + 100。
常规算法,代码如下:
从代码附加的注释可以看到所有代码都执行了多少次。那么这写代码语句执行次数的总和就可以理解为是该算法计算出结果所需要的时间。该算法所用的时间(算法语句执行的总次数)为: 1 + ( n + 1 ) + n + 1 = 2n + 3
而当 n 不断增大,比如我们这次所要计算的不是 1 + 2 + 3 + 4 + ...... + 100 = ? 而是 1 + 2 + 3 + 4 + ...... + n = ?其中 n 是一个十分大的数字,那么由此可见,上述算法的执行总次数(所需时间)会随着 n 的增大而增加,但是在 for 循环以外的语句并不受 n 的规模影响(永远都只执行一次)。所以我们可以将上述算法的执行总次数简单的记做: 2n 或者简记 n
这样我们就得到了我们设计的算法的时间复杂度,我们把它记作: O(n)
再来看看高斯的算法,代码如下:
这个算法的时间复杂度: O(3),但一般记作 O(1)。
从感官上我们就不难看出,从算法的效率上看,O(1) < O(n) 的,所以高斯的算法更快,更优秀。
这也就难怪为什么每本算法书开篇都是拿高斯的这个例子来举例了(至少我看的都是)...人家也确实有那个资本。
二。求两个n阶方阵C=A*B的乘积其算法如下:
则该算法所有语句的频度之和为:
T(n) = 2n^3+3n^2+2n+1; 利用大O表示法,该算法的时间复杂度为O(n^3)。
三。分析下列时间复杂度
设for循环语句执行次数为T(n),则 i = 2T(n) + 1 <= n - 1, 即T(n) <= n/2 - 1 = O(n)
四。分析下列时间复杂度
其中,算法的基本运算语句是
if (b[k] > b[j])
{
k = j;
}
其执行次数T(n)为:
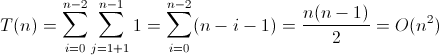
五。分析下列时间复杂度
其中,算法的基本运算语句即while循环内部分,
设while循环语句执行次数为T(n),则
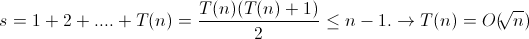
六。Hanoi(递归算法)时间复杂度分析
对于递归函数的分析,跟设计递归函数一样,要先考虑基情况(比如hanoi中n==1时候),这样把一个大问题划分为多个子问题的求解。
故此上述算法的时间复杂度的递归关系如下:
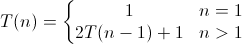
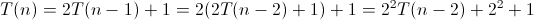
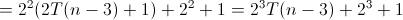

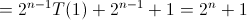
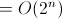















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









