







图形处理单元
数据并行处理结构
目标:尽量避免gpu处理单元处于空闲状态。
GPU中包含数千个着色器核心(shader core)。
GPU可以按顺序并行处理大量的相似数据,这些处理过程之间相互独立,不依赖其他过程的结果和内存。
由于缓冲区和逻辑控制的芯片面积较少,所以单个着色器核心的延迟远大于CPU。
如果让一个着色器核心处理若干个片段,在缓冲区进行运算时的速度非常快,可以认为没有延迟,但是一旦涉及到内存访问,比如纹理采样,就会花费相当多的时间。在这期间着色器核心就会处于空闲等待状态,导致效率低下。
为了解决着色器核心等待的问题,为每一个片段留下一部分空间作为本地寄存器。当着色器核心处于等待状态的时候,让其保存当前片段的运行环境后转换到其他的片段继续执行。转换过程十分快。着色器核心进行运算直到再次遇到内存访问,就保存运行环境后执行另一个片段,以此类推直到所有片段执行了一遍,处理器就会回到第一个片段继续执行,此时内存访问的数据已经获得了,可以接着执行,一直执行到遇到下一个内存访问命令或者程序结束为止。这种方法增加了一个片段的执行时间,但却大大缩短了整体时间。
GPU通过让和核心保持忙碌来减少延迟,更进一步减少延迟的方法是将指令从数据中分离出来。称之为单指令多数据(SIMD)。该方法的优势在于相较于使用独立逻辑和调度单元去运行每个程序,其功耗要小得多。
每一个片段着色器处理一个片段称作一个线程。它包含了片段着色器的输入参数以及一些用于运行的寄存器空间。使用相同逻辑的线程被打包为一个包,称作warps(NVIDIA),wavefonts(AMD)。每一个warps都由一定数量的着色器核心来进行SIMD处理,每一个线程都会被映射到SMID通道中。
每个warps的处理过程和处理一个片段是类似的,warps的所有线程都由相同的指令进行处理,所以当遇到内存访问的指令时,所有的线程都会同时遇到,这时该warps就会转向去运行另外的线程。转换速度和转换一个一样快。每一个线程都有其单独的寄存器,每一个warp都跟踪其正在运行的指令。(所以SIMD所谓的指令和数据分离是指将数据由线程保存,将指令由warp保存)。
warp-swapping(上述过程)是最主要的减少延迟的方式。
影响warp-swapping的因素:
-
线程过少,会导致生成的warp太少,导致效率变低
-
每个线程使用的寄存器数量。使用数量过多的话,会导致能够生成的线程数量太少,导致效率变低。
-
内存访问的次数。
-
动态分支的使用(使用了varying inputs 的 if,循环),由于warp-swapping会对warp中的每一个线程使用相同的命令,这就导致了如果有个别线程采用了不同的分支,GPU必须对其使用相应的命令,而其他的线程也必须执行相同的命令,然后抛弃各个线程不需要的结果后才能继续执行,严重影响了效率。该问题被称作thread divergence
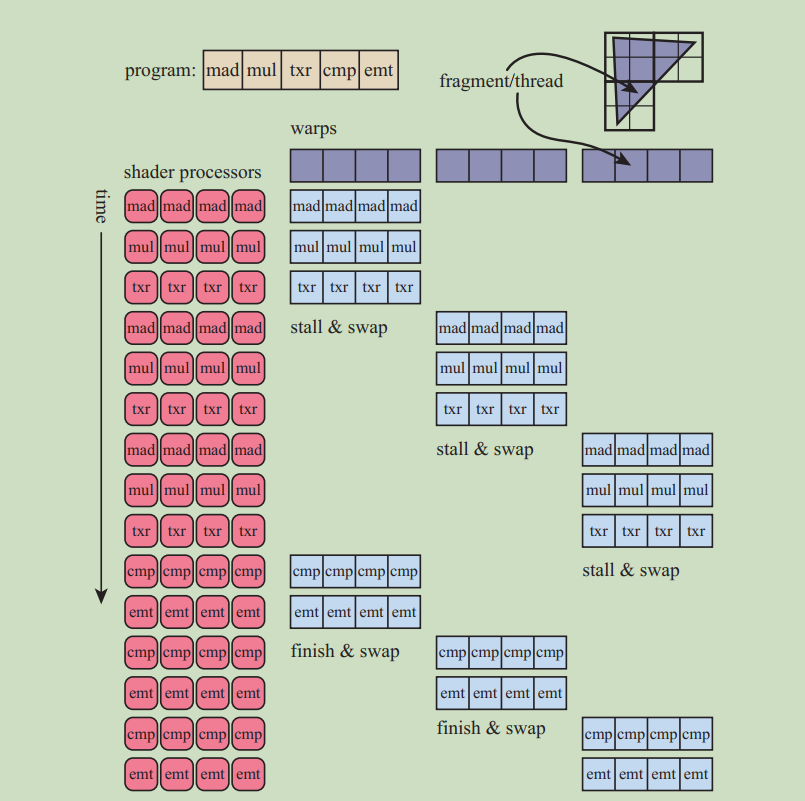
简单的shader处理过程。(生成warps->执行至内存访问->停止该线程组,转换到其他线程组->获得内存数据后继续执行->程序完成后或者再次遇到内存访问进行转换)
可编程着色阶段
现代GPU都使用一种统一的着色器设计,即所有的shader都使用同一种编程模型。它们拥有相同的ISA(工业标准体系结构)。
使用这种统一模型的处理器成为通用着色器核心。
why?:为了让GPU能够更加灵活的分配各种着色器核心所负责的工作。假如GPU所拥有的着色器核心只专门负责处理一种任务(顶点或者片段),这就意味着对于不同的情况,保持所有核心都处于繁忙状态的设想很难实现。而全部都是通用核心的话,GPU就可以自己决定如何合理分配核心去处理不同的任务。
HLSL可以将代码编译成IL(中间码),用于保证硬件独立性。
最基本的数据类型是32位的单精度浮点标量和矢量,GPU同样支持32位整形,64位浮点数,结构体,数组,矩阵等。
每个可编程的着色器阶段都拥有两种输入数据:
- uniform inputs,该输入值在一次drawcall中不会改变。比如光源颜色,纹理
- varying inputs,来自于顶点或者光栅化阶段。比如法线坐标
GPU提供寄存器来保存这些输入数据(纹理不一定),其中uniform inputs的寄存器数量远大于varying inputs,因为varying inputs的数据在每一次的处理中都是不一样的,而uniform inputs是整个drawcall中一直使用的。
GPU中还提供temporary registers ,可以通过索引从该寄存器中访问到所有的输入数据。
flow control是用于实现if,循环等操作的,GPU包含两种flow control:
- static flow control,它是依靠uniform inputs来实现的,可以使得一种shader能应对不同情况(比如灯光的数量不同),由于所有的线程都需要完成那么多次循环,所以它不会出现thread divergence。
- dynamic flow control,它是依靠varying inputs来实现的,它比static flow control更加强大,但是会花费更多的代价。
顶点着色器
顶点着色器之前还有一些数据处理过程,在dx中被称为input assember(输入汇编器)。它的主要功能就是将数据流转换为管线所需要的顶点或者片元。比如:一个模型由顶点以及相应的顶点颜色来表示,这个阶段就会将传入的数据流转换为模型顶点的数据,每个顶点数据包含位置信息以及颜色信息。该阶段也支持instancing(实例化),即在一次drawcall中一个物体可以被不同的数据多次绘制。
顶点数据包含很多有用的数据,其中的法线会有一些不同,某些三角形顶点的法线并不是真正意义上的三角形的法线,而会有些偏差,这是因为某些模型中,该三角面代表的其实是一种曲面,而它的法线也是该曲面在该点的法线
。如图所示:平滑曲面的法线和尖锐曲面的法线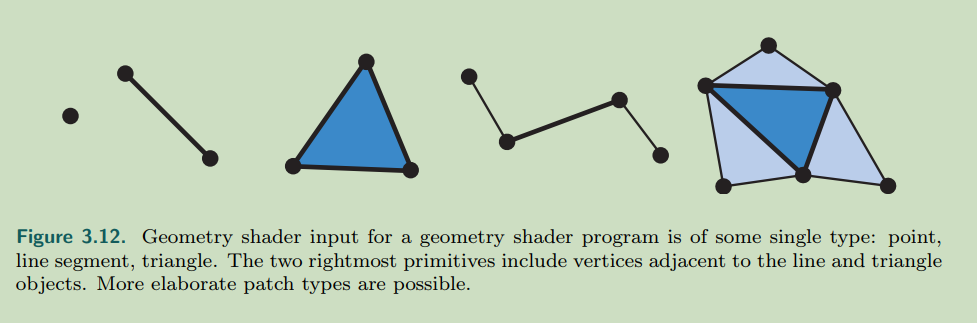
顶点着色器无法使用那些用于描述形成三角形的数据,它只能使用顶点的数据。
顶点着色器必须要输出顶点在裁剪空间的位置信息。
顶点着色器每个顶点的处理过程是独立的,各个点之间无法传递数据。
顶点着色器会输出一组顶点数据,这些数据会在之后的阶段被插值形成更多的数据(所以顶点数远小于片段数)。
顶点着色器没有增加和销毁顶点的能力。
逻辑模型表明数据的组装是发生在顶点着色器之前的,但是在物理模型上,这个阶段可能是悄然发生在顶点着色阶段的。
顶点着色器的用途:
- 动画关节的混合
- 轮廓渲染
- 生成物体,通过顶点着色器改变网格来生成新的物体
- 程序化变形,旗帜,衣服
- 粒子生成
- 在经历过程序化变形的网格上使用完整的帧缓冲作为纹理的技术,光学畸变,热浪,水波
- 地图高度场的应用
顶点着色器的输出可以作为图元的组成成员,被光栅化后形成片段供片段着色器处理。也可以输入到曲面细分着色器或者几何着色器进行进一步处理,也可以输入到内存中。
曲面细分着色器
曲面细分着色器允许我们渲染弯曲的表面。它将每个表面转换为适合数量的三角面。
使用曲面细分着色器能防止CPU与GPU之间的总线称为某个模型的瓶颈。可以通过调整生成适合数量的三角形来高效渲染一个模型。比如针对不同的距离或者不同的平台为一个模型生成不同三角形数量。
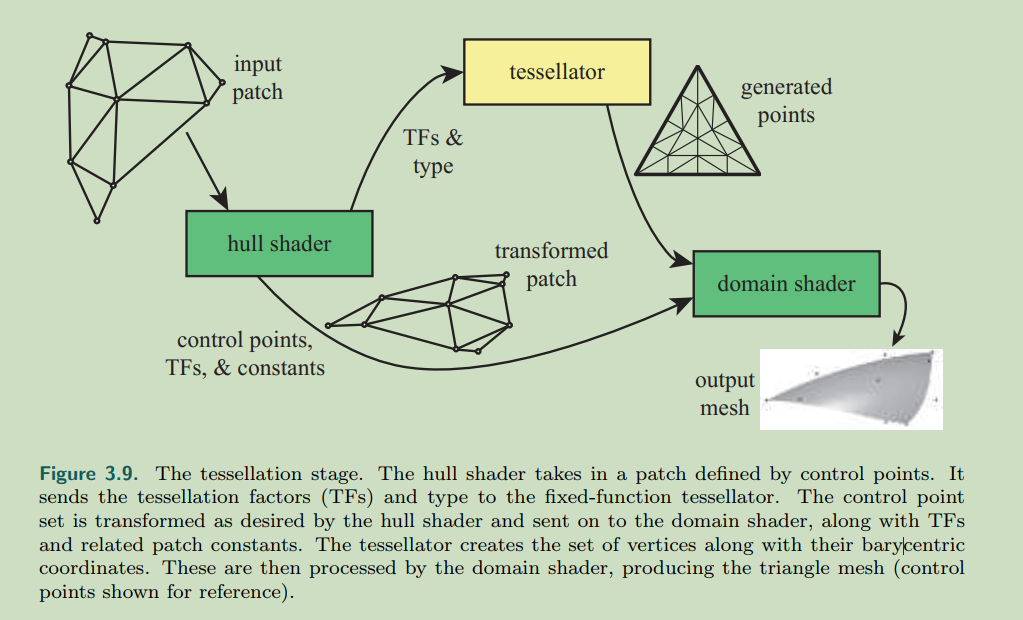
曲面细分由3个部分组成:
- hull shader(dx)tessellation control shader(opengl)
- tessellator(dx)primitive generator(opengl)
- domain shader(dx) tessellation evaluation shader(opengl)
几何着色器
几何着色器能够将图元转换为其他图元,比如通过将三角形的三条边扩展称为3个新的三角形使得原来的三角形称为一个网格。或者将3条边扩展称为4边形,并让4边形朝向观察者,使得三角形看起来有了更厚的边。
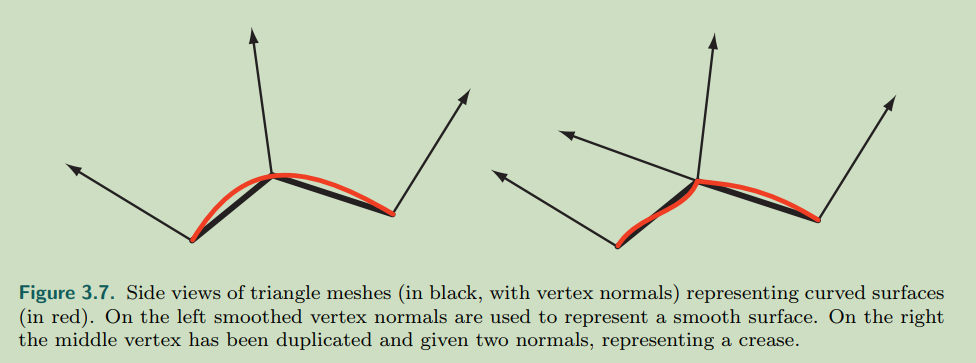
几何着色器的输入是由,点,线段或者三角形构成的物体对象,每个三角形可以额外传入3个外部的顶点,以形成网格。每个线段可以额外传入两个顶点,来使之成为折线。
前3种是传入的图元,后两种是扩展的图元。
几何处理阶段接受图元,输出0个或者更多的图元(大于输入图元的顶点数),注意:几何着色器不产生输出(应该是几何处理阶段的其他部分产生的)
几何着色器用于调整输入的数据或者制作有限数量的副本。比如:立方体贴图的6个面可以由其生成,生成级联阴影。
dx11使得几何着色器有了使用实例化的能力,这使得几何着色器能够在一个图元上进行多次运行。几何着色器可以输出高达4个流的数据,可以指定其输入到具体渲染目标。
几何着色器保证图元的输入和输出顺序一致,这导致了效率的降低。
几何着色器由于其不是很匹配GPU的长处(并行处理),所以它的使用比较少。
数据流式输出
顶点着色器产生的结果不仅仅可以输送到光栅化阶段,也可以输入到一个流种,即有序数组。可以关闭管线后面的部分,将着色器作为一个流数据处理器来使用。得到的数据可以再被送回管线中进行再次处理。这种技术可以用来模拟水流或者人物蒙皮等操作。
流式输出只以浮点数的形式输出,所以其空间占用是可知的,流式输出是工作在图元上的,而非顶点。输入的网格中的每一个三角形都会生成3个顶点的数据(比如被两个三角形公用的顶点会形成两个顶点)。因此,更通常的做法是输入顶点作为图元的数据。流时输出的用途大多是用于进行顶点的变换然后进行进一步处理。
片段着色器
经过顶点着色器,曲面细分,几何着色器处理后的图元会被送到光栅化阶段进行处理,该阶段会利用顶点进行插值,计算出图元覆盖的每一个像素的值,由此产生了片段。
插值类型通常由片段着色器进行指定,通常使用的是透视矫正插值。
片段着色器的输入通常是指由顶点着色器的输出插值形成片段,单还有其他的输入,例如:片段的屏幕坐标以及三角形的那个面是可见的等。
片段着色器的工作通常就是计算并且输出一个片段的最终颜色(不是像素的最终颜色),也可以进行透明度的计算或者调整深度值。这些值在最后的测试混合阶段进行处理并最终计算出显示在像素上的颜色。
片段着色器可以抛弃特定的片段。
片段着色器不仅仅是将输出传递给测试混合阶段以计算像素的最终颜色,还可以将其值输出到各种其他的缓冲区(渲染目标,4个或者8个)上。输出的值也不仅仅只是颜色值以及深度值,也可以是法线、金属度等其他值。由于片段着色器的这些能力,催生了多渲染目标技术(MRT),即为片段着色器一次处理,将不同的值输出到不同的渲染目标之中,一次生成多张和屏幕大小相同的缓冲区。延迟渲染就是基于这个原理产生的(所以延迟渲染的计算复杂度只和屏幕大小有关,所有的光照计算都只需要在屏幕空间大小的缓冲区上进行计算)
片段着色器在运行时不能获得其周边片段的值(依旧是并行处理的问题),不过一次执行所生成的图片数据可以被下一次执行任意访问。访问片段周边的值可以用于图片处理。
有一个例外,片段着色器可以在计算gradient(梯度)或者derivative(导数)时可以间接获得周边片段的信息。GPU实现其是将4个像片段组成一个quad进行计算。这仅仅局限于一个warp中的不同线程(因为在其他warp中的线程并不一定计算出了值)。同时,在一个warp中的线程也要求不能被动态分支所影响(使用varying inputs的分支语句),因为要保证用于计算梯度的值都是经过相同的计算过程。(//TODO:关于计算梯度的quad现在还无法理解)
dx11引入了一种可以对任意位置进行写访问的缓冲区,称作UAV(unordered access view),OpenGL中对应的是SSBO(shader storage buffer object)。片段着色器以无序的方式并行执行,该缓冲区在它们之间共享。
有些机制会导致数据竞争,即为两个着色器程序同时对一个位置进行读写。GPU解决这种问题使用了,即为同时只允许一个着色器访问该内存,这可能会导致其他着色器处于等待状态。(机制类似于cpu)
对于那些需要以特定顺序进行的算法(比如透明度混合),GPU提供了RAV(Rasterizer order views),类似UAV的读写方式,不过其保证获取数据是按照顺序来的。RAV允许片段着色器定义自己的混合方式,甚至可以舍去混合阶段。代价是:如果有对于RAV的写入访问,该片段着色器可能会停止执行,直到在它之前的片段全部绘制进去之后才进行写入。
参考资料
RTR4















 970
970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









