







Java 虚拟机(Java virtual machine,JVM)是运行 Java 程序必不可少的机制。
JVM实现了Java语言最重要的特征:即平台无关性。这是因为:编译后的 Java 程序指令并不直接在硬件系统的 CPU 上执行,而是由 JVM 执行。JVM屏蔽了与具体平台相关的信息,使Java语言编译程序只需要生成在JVM上运行的目标字节码(.class),就可以在多种平台上不加修改地运行。Java 虚拟机在执行字节码时,把字节码解释成具体平台上的机器指令执行。因此实现java平台无关性。它是 Java 程序能在多平台间进行无缝移植的可靠保证,同时也是 Java 程序的安全检验引擎(还进行安全检查)。
JVM是编译后的 Java 程序(.class文件)和硬件系统之间的接口 ( 编译后:javac 是收录于 JDK 中的 Java 语言编译器。该工具可以将后缀名为. java 的源文件编译为后缀名为. class 的可以运行于 Java 虚拟机的字节码。)
JVM architecture

图片摘自 httpjavapapers.comjavajava-garbage-collection-introduction
JVM = 类加载器 classloader + 执行引擎 execution engine + 运行时数据区域 runtime data area classloader 把硬盘上的class 文件加载到JVM中的运行时数据区域, 但是它不负责这个类文件能否执行,而这个是 执行引擎 负责的。
classloader
作用:装载.class文件
classloader 有两种装载class的方式 (时机):
-
隐式:运行过程中,碰到new方式生成对象时,隐式调用classLoader到JVM
-
显式:通过class.forname()动态加载
双亲委派模型(Parent Delegation Model):
类的加载过程采用双亲委托机制,这种机制能更好的保证 Java 平台的安全。 该模型要求除了顶层的Bootstrap class loader启动类加载器外,其余的类加载器都应当有自己的父类加载器。子类加载器和父类加载器不是以继承(Inheritance)的关系来实现,而是通过组合(Composition)关系来复用父加载器的代码。每个类加载器都有自己的命名空间(由该加载器及所有父类加载器所加载的类组成,在同一个命名空间中,不会出现类的完整名字(包括类的包名)相同的两个类;在不同的命名空间中,有可能会出现类的完整名字(包括类的包名)相同的两个类)。
双亲委派模型的工作过程为:
1.当前 ClassLoader 首先从自己已经加载的类中查询是否此类已经加载,如果已经加载则直接返回原来已经加载的类。
每个类加载器都有自己的加载缓存,当一个类被加载了以后就会放入缓存, 等下次加载的时候就可以直接返回了。
2.当前 classLoader 的缓存中没有找到被加载的类的时候,委托父类加载器去加载,父类加载器采用同样的策略,首先查看自己的缓存,然后委托父类的父类去加载,一直到 bootstrap ClassLoader.
3.当所有的父类加载器都没有加载的时候,再由当前的类加载器加载,并将其放入它自己的缓存中,以便下次有加载请求的时候直接返回。
使用这种模型来组织类加载器之间的关系的好处 主要是为了安全性,避免用户自己编写的类动态替换 Java 的一些核心类,比如 String,同时也避免了重复加载,因为 JVM 中区分不同类,不仅仅是根据类名,相同的 class 文件被不同的 ClassLoader 加载就是不同的两个类,如果相互转型的话会抛java.lang.ClassCaseException.
类加载器 classloader 是具有层次结构的,也就是父子关系。其中,Bootstrap 是所有类加载器的父亲。如下图所示:
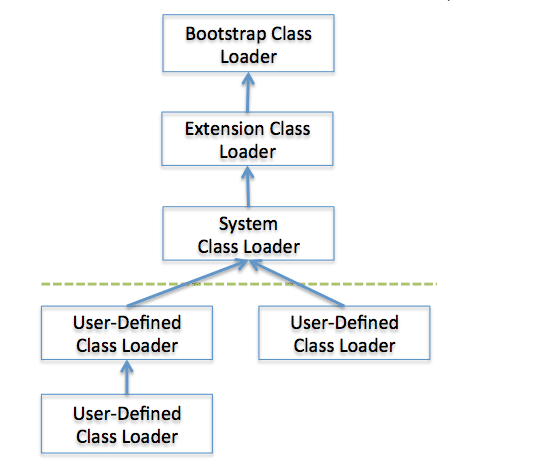
Bootstrap class loader: 父类 当运行 java 虚拟机时,这个类加载器被创建,它负责加载虚拟机的核心类库,如 java.lang. 等。例如 java.lang.Object 就是由根类加载器加载的。需要注意的是,这个类加载器不是用 java 语言写的,而是用 CC++ 写的。
Extension class loader 这个加载器加载出了基本 API 之外的一些拓展类。
AppClass Loader 加载应用程序和程序员自定义的类。
除了以上虚拟机自带的加载器以外,用户还可以定制自己的类加载器(User-defined Class Loader)。Java 提供了抽象类 java.lang.ClassLoader,所有用户自定义的类加载器应该继承 ClassLoader 类。
这是JVM分工自治生态系统的一个很好的体现。
执行引擎与区域划分
jvm的区域划分如下所示:

大致就是分为:程序计数器,虚拟机栈,堆,方法区,本地方法栈,这几个部分。
接下来我们从自己写好的Java代码如何通过JVM来运行的角度,来分析一下JVM里这些区域是如何支撑我们的Java代码跑起来的。
程序计数器
假设我们有如下的一个类,就是最最基本的一个HelloWorld而已:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello World");
}
}
上面那段代码首先会存在于 “.java” 后缀的文件里,这个文件就是java源代码文件,但是这个文件是面向我们程序员的,计算机看不懂这段代码
所以此时就得通过编译器,把“.java”后缀的源代码文件编译为“.class”后缀的字节码文件。
这个“.class”后缀的字节码文件里,存放的就是对你写出来的代码编译好的字节码了。
这个字节码才是计算器可以理解的一种语言,而不是我们写出来的那一堆代码。
这个字节码看起来大概是下面这样的:

说明一下:这段字节码并不是完全对照着HelloWorld那个类来写的,就是给一段示例,让大家知道“.java”翻译成的“.class”是大概什么样子。
比如这里的“0: aload_0”这样的东西,就是“字节码指令”,他对应了一条一条的机器指令,计算机只有读到这种机器码指令,才知道具体应该要干什么。
比如说字节码指令可能会让计算机从内存里读取某个数据,或者把某个数据写入到内存里去。
总之,各种各样的指令,就会指示计算机去干各种各样的事情。
所以现在首先明白一点:我们写好的Java代码是会被翻译成字节码的,对应各种字节码指令。那么Java代码通过JVM跑起来的第一件事情就明确了。
接下来,在执行字节码指令时,JVM里的程序计数器就是用来记录每个线程当前执行的字节码指令的位置的,记录当前线程目前执行到了哪一条字节码指令。
因为会有多个线程来并发的执行各种不同的代码,所以每个线程都有自己的一个程序计数器,专门记录当前这个线程目前执行到了哪一条字节码指令了
下图更加清晰的展示出了他们之间的关系。

Java虚拟机栈
Java代码在执行的时候,一定是线程来执行某个方法中的代码,哪怕上面那个最基础的HelloWorld代码,也会有一个main线程来执行main方法里的代码。
在方法里,经常会定义一些方法内的局部变量,比如下面这样,就在方法里定义了一个局部变量“name”。
public void sayHello() {
String name = "hello";
}
所以JVM必须有一块区域来保存每个方法内的局部变量等数据,这个区域就是Java虚拟机栈
每个线程都会去执行各种方法的代码,方法内还会嵌套调用其他的方法,所以每个线程都有自己的Java虚拟机栈。
如果线程执行了一个方法,那么就会为这个方法调用创建对应的一个栈帧
栈帧里有这个方法的局部变量表 、操作数栈、动态链接、方法出口等东西,但是这里别的不太好理解,先理解一个局部变量就可以。
举例,比如一个线程调用了上面写的 “sayHello” 方法,那么就会为“sayHello”方法创建一个栈帧,压入线程自己的Java虚拟机栈里面去。
在栈帧的局部变量表里就会有“name”这个局部变量。
下图展示了这个过程。

接着如果“sayHello”方法调用了另外一个“greeting”方法 ,比如下面那样的代码:

这时会给“greeting”方法又创建一个栈帧,压入线程的Java虚拟机栈里,因为开始执行“greeting”方法了。
而且“greeting”方法的栈帧的局部变量表里会有一个“greet”变量,这是“greeting”方法的局部变量。

接着如果“greeting”方法执行完毕了,就会把“greeting”方法对应的栈帧从Java虚拟机栈里给出栈。
然后接下来如果“sayHello”方法也执行完毕了,就会把“sayHello”方法也从Java虚拟机栈里出栈。
这就是JVM中的 “ Java虚拟机栈 ” 这个组件的作用:调用执行任何方法的时候,都会给方法创建栈帧,然后入栈。
而在栈帧里存放了这个方法对应的局部变量之类的数据,包括这个方法执行的其他相关的信息,方法执行完毕之后就出栈。
Java堆内存
JVM中有另外一个非常关键的区域,就是Java堆,这里就是存放我们在代码中创建的各种对象的,比如说下面的代码:
public void sayHello(String name) {
Student student = new Student(name);
student.study();
}
上面的 “new Student(name)” 这个代码,就是创建了一个Student类型的对象实例,这个对象实例里面会包含一些数据。
比如说这个Student的“name”就是属于这个对象实例的数据,类似Student这样的对象,就会存放在Java堆内存里。
Java堆内存区域里会放入类似Student的对象,然后方法的栈帧的局部变量表里,会存放这个引用类型的“student”局部变量,即存放Student对象的地址。
相当于你可以认为局部变量表里的“student”指向了Java堆里的Student对象。
看下图会更加清晰一些。

方法区 / Metaspace
这个方法区是在JDK 1.8以前的版本里,代表JVM中的一块区域.
他主要是放类似Student类自己的信息的,平时用到的各种类的信息,都是放在这个区域里,还会有一些类似常量池的东西放在这个区域里。
但是在JDK 1.8以后,这块区域的名字改了,叫做“Metaspace”,可以认为是“元数据空间”这样的意思,当然他主要还是存放我们自己写的各种类相关的信息。
本地方法栈
其实在JDK很多底层API里,比如IO相关的,NIO相关的,网络Socket相关的,如果去看他内部的源码,会发现很多地方都不是Java代码了。
很多地方都会去走native方法,去调用本地操作系统里面的一些方法,可能调用的都是c语言写的方法,或者一些底层类库,比如下面这样的:
public native int hashCode();
在调用这种 native 方法时,就会有线程对应的本地方法栈,这个里面也是跟Java虚拟机栈类似的,也是存放各种native方法的局部变量表之类的信息。
堆外内存
还有一个区域,是不属于JVM的,通过NIO中的 allocateDirect 这种API,可以在Java堆外分配内存空间。
然后通过Java虚拟机里的 DirectByteBuffer 来引用和操作堆外内存空间,其实很多技术都会用这种方式,因为在一些场景下,堆外内存分配可以提升性能。
1
总结
最后做一点总结,我们的Java代码通过JVM来运行时:
1、PC程序计数器:一块较小的内存空间,可以看做是当前线程所执行的字节码的行号指示器, NAMELY存储每个线程下一步将执行的JVM指令,如该方法为native的,则PC寄存器中不存储任何信息。Java 的多线程机制离不开程序计数器,每个线程都有一个自己的PC,以便完成不同线程上下文环境的切换。首先一定会一行一行执行编译好的字节码指令。
2、java虚拟机栈:与 PC 一样,java 虚拟机栈也是线程私有的。每一个 JVM 线程都有自己的 java 虚拟机栈,这个栈与线程同时创建,它的生命周期与线程相同。虚拟机栈描述的是Java 方法执行的内存模型:每个方法被执行的时候都会同时创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法被调用直至执行完成的过程就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。然后在执行的过程中,对于方法的调用,会通过Java虚拟机栈来为每个方法创建栈帧来入栈和出栈,而且栈帧里有方法的局部变量表。
3、本地方法栈:与虚拟机栈的作用相似,虚拟机栈为虚拟机执行执行java方法服务,而本地方法栈则为虚拟机使用到的本地方法服务。
4、Java堆:被所有线程共享的一块存储区域,在虚拟机启动时创建,它是JVM用来存储对象实例以及数组值的区域,可以认为Java中所有通过new创建的对象的内存都在此分配。
Java堆在JVM启动的时候就被创建,堆中储存了各种对象,这些对象被自动管理内存系统(Automatic Storage Management System,也即是常说的 “Garbage Collector(垃圾回收器)”)所管理。这些对象无需、也无法显示地被销毁。
JVM将Heap分为两块:新生代New Generation和旧生代Old Generation
Note: - 堆在JVM是所有线程共享的,因此在其上进行对象内存的分配均需要进行加锁,这也是new开销比较大的原因。 - 鉴于上面的原因,Sun Hotspot JVM为了提升对象内存分配的效率,对于所创建的线程都会分配一块独立的空间,这块空间又称为TLAB - TLAB仅作用于新生代的Eden Space,因此在编写Java程序时,通常多个小的对象比大的对象分配起来更加高效
5、方法区 / Metaspace(jdk8之后改名元数据空间)
方法区和堆区域一样,是各个线程共享的内存区域,它用于存储每一个类的结构信息,例如运行时常量池,成员变量和方法数据,构造函数和普通函数的字节码内容,还包括一些在类、实例、接口初始化时用到的特殊方法。当开发人员在程序中通过Class对象中的getName、isInstance等方法获取信息时,这些数据都来自方法区。
方法区也是全局共享的,在虚拟机启动时候创建。在一定条件下它也会被GC。这块区域对应Permanent Generation 持久代。 XX:PermSize指定大小。
6、运行时常量池 其空间从方法区中分配,存放的为类中固定的常量信息、方法和域的引用信息。
另外有两块特殊的区域:
-
本地方法栈,是执行native方法时候用的栈,跟Java虚拟机栈是类似的
-
堆外内存,可以在Java堆外分配内存空间来存储一些对象
GC
Java garbage collection is an automatic process to manage the runtime memory used by programs. By doing it automatic JVM relieves the programmer of the overhead of assigning and freeing up memory resources in a program.
java 与 C语言相比的一个优势是,可以通过自己的JVM自动分配和回收内存空间。
何为GC?
垃圾回收机制是由垃圾收集器Garbage Collection GC来实现的,GC是后台的守护进程。它的特别之处是它是一个低优先级进程,但是可以根据内存的使用情况动态的调整他的优先级。因此,它是在内存中低到一定限度时才会自动运行,从而实现对内存的回收。这就是垃圾回收的时间不确定的原因。
为何要这样设计:因为GC也是进程,也要消耗CPU等资源,如果GC执行过于频繁会对java的程序的执行产生较大的影响(java解释器本来就不快),因此JVM的设计者们选着了不定期的gc。
GC有关的是 runtime data area 中的 heap(对象实例会存储在这里) 和 gabage collector方法。
程序运行期间,所有对象实例存储在运行时数据区域的heap中,当一个对象不再被引用(使用),它就需要被收回。在GC过程中,这些不再被使用的对象从heap中收回,这样就会有空间被循环利用。
GC为内存中不再使用的对象进行回收,GC中调用回收的方法–收集器garbage collector. 由于GC要消耗一些资源和时间,Java 在对对象的生命周期特征(eden or survivor)进行分析之后,采用了分代的方式进行对象的收集,以缩短GC对应用造成的暂停。
在垃圾回收器回收内存之前,还需要一些清理工作。
因为垃圾回收gc只能回收通过new关键字申请的内存(在堆上),但是堆上的内存并不完全是通过new申请分配的。还有一些本地方法(一般是调用的C方法)。这部分“特殊的内存”如果不手动释放,就会导致内存泄露,gc是无法回收这部分内存的。 所以需要在finalize中用本地方法(native method)如free操作等,再使用gc方法。显示的GC方法是system.gc()
垃圾回收技术
方法一:引用计数法。简单但速度很慢。缺陷是:不能处理循环引用的情况。
方法二:停止-复制(stop and copy)。效率低,需要的空间大,优点,不会产生碎片。
方法三:标记 - 清除算法 (mark and sweep)。速度较快,占用空间少,标记清除后会产生大量的碎片。
JAVA虚拟机中是如何做的? java的做法很聪明,我们称之为自适应的垃圾回收器,或者是自适应的、分代的、停止-复制、标记-清扫式垃圾回收器。它会根据不同的环境和需要选择不同的处理方式。
heap组成
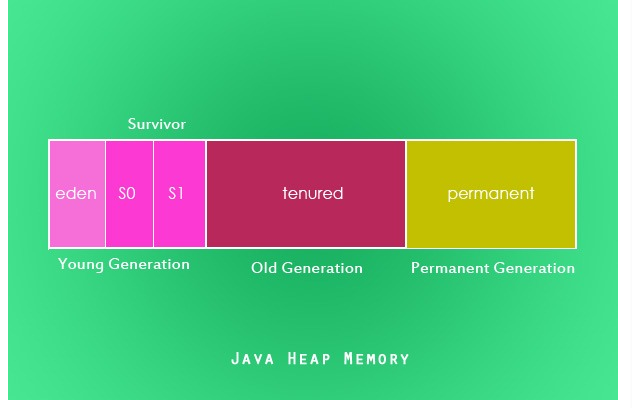
由于GC需要消耗一些资源和时间的,Java在对对象的生命周期特征进行分析后,采用了分代的方式来进行对象的收集,即按照新生代、旧生代的方式来对对象进行收集,以尽可能的缩短GC对应用造成的暂停. heap 的组成有三区域世代:(可以理解随着时间,对象实例不断变换heap中的等级,有点像年级)
-
新生代 Young Generation 1. Eden Space 任何新进入运行时数据区域的实例都会存放在此 2. S0 Suvivor Space 存在时间较长,经过垃圾回收没有被清除的实例,就从Eden 搬到了S0 3. S1 Survivor Space 同理,存在时间更长的实例,就从S0 搬到了S1
-
旧生代 Old Generationtenured 同理,存在时间更长的实例,对象多次回收没被清除,就从S1 搬到了tenured
-
Perm 存放运行时数据区的方法区
Java 不同的世代使用不同的 GC 算法。
- Minor collection: 新生代 Young Generation 使用将 Eden 还有 Survivor 内的数据利用 semi-space 做复制收集(Copying collection), 并将原本 Survivor 内经过多次垃圾收集仍然存活的对象移动到 Tenured。
- Major collection 则会进行 Minor collection,Tenured 世代则进行标记压缩收集。
To note that 这个搬运工作都是GC完成的,这也是garbage collector 的名字来源,而不是叫garbage cleaner. GC负责在heap中搬运实例,以及收回存储空间。
GC工作原理
JVM 分别对新生代和旧生代采用不同的垃圾回收机制
何为垃圾?
Java中那些不可达的对象就会变成垃圾。那么什么叫做不可达?其实就是没有办法再引用到该对象了。主要有以下情况使对象变为垃圾:
1.对非线程的对象来说,所有的活动线程都不能访问该对象,那么该对象就会变为垃圾。
2.对线程对象来说,满足上面的条件,且线程未启动或者已停止。
例如: (1)改变对象的引用,如置为null或者指向其他对象。
Object x=new Object();object1
Object y=new Object();object2
x=y;object1 变为垃圾
x=y=null;object2 变为垃圾
(2)超出作用域
if(i==0){ Object x=new Object();object1 }//括号结束后object1将无法被引用,变为垃圾
(3)类嵌套导致未完全释放
class A{ A a; } A x= new A();//分配一个空间 x.a= new A();//又分配了一个空间 x=null;//将会产生两个垃圾
(4)线程中的垃圾
class A implements Runnable{
void run(){ …. } } main A x=new A();object1 x.start(); x=null;//等线程执行完后object1才被认定为垃圾 这样看,确实在代码执行过程中会产生很多垃圾,不过不用担心,java可以有效地处理他们。
JVM中将对象的引用分为了四种类型,不同的对象引用类型会造成GC采用不同的方法进行回收: (1)强引用:默认情况下,对象采用的均为强引用 (GC不会回收)
(2)软引用:软引用是Java中提供的一种比较适合于缓存场景的应用 (只有在内存不够用的情况下才会被GC)
(3)弱引用:在GC时一定会被GC回收
(4)虚引用:在GC时一定会被GC回收














 697
697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









