






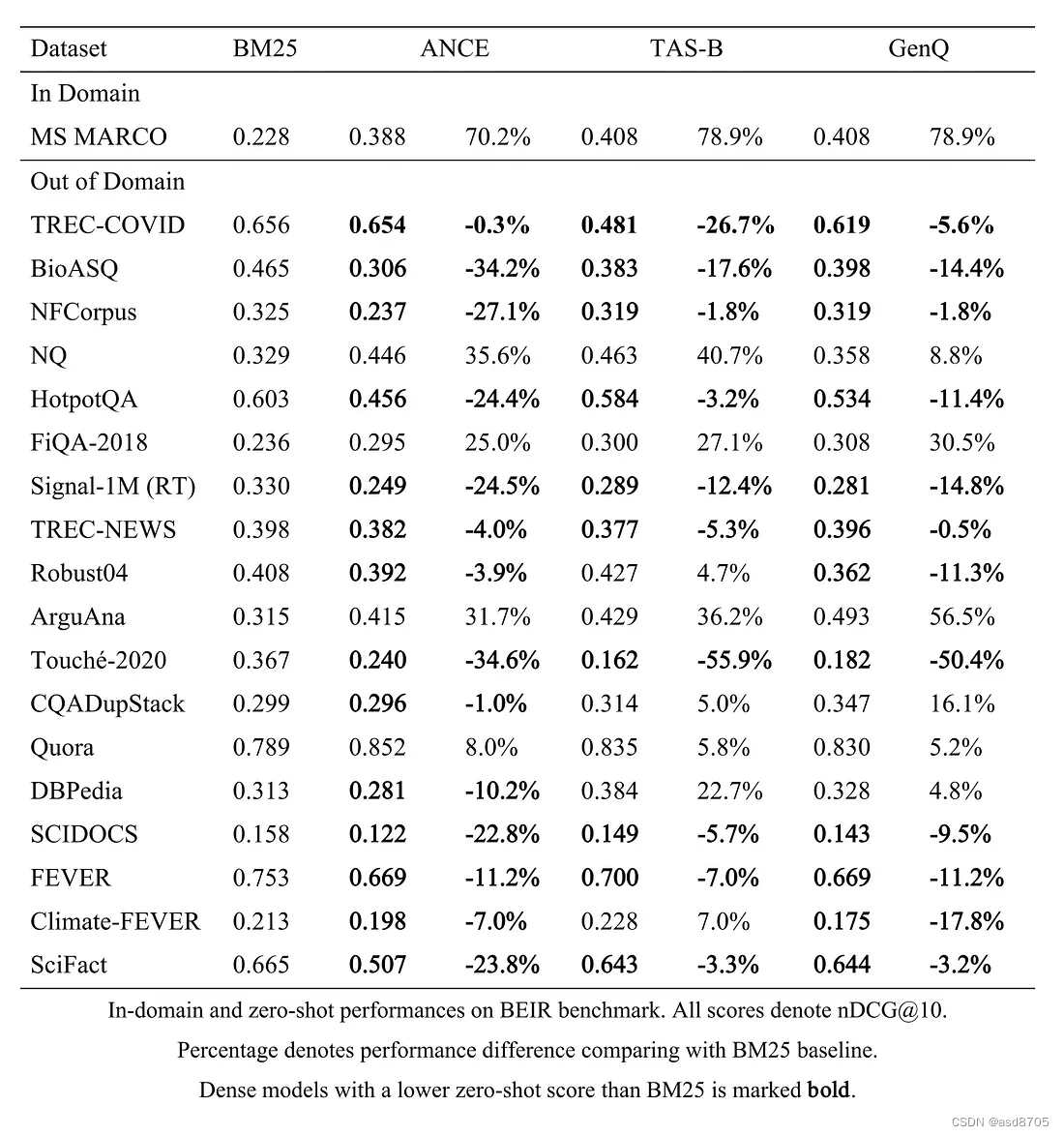
信息检索方法的发展旅程从传统的基于关键词的统计匹配,到深度学习模型如BERT的颠覆性力量,已经经历了巨大的变化。虽然传统方法提供了坚实的基础,但它们往往在捕捉文本的微妙语义关系方面需要额外的帮助。类似于BERT的密集检索方法通过利用高维向量来封装上下文语义,带来了显著的提升。然而,在脱离领域知识的情况下,它们面临挑战,因为这些方法过于依赖特定领域的知识。
在这种背景下,学习稀疏嵌入成为提升信息检索性能的一个有前景的方向。稀疏嵌入利用较少的维度来表示文本,这不仅减少了计算复杂度,而且还有助于更好地捕捉语义信息。与密集向量相比,它们在表示文本时更加高效,尤其是在处理大规模数据集时。此外,稀疏嵌入模型通常具有更好的泛化能力,能够在不同领域或未见过的上下文中提供更准确的信息检索结果。
本文旨在探讨如何通过学习稀疏嵌入来优化信息检索系统的性能。我们将探讨稀疏嵌入的基本原理、它们如何与信息检索任务相结合,以及如何利用这些技术来改进检索系统的准确性和效率。同时,我们还将分析稀疏嵌入在实际应用中的优势和局限性,并讨论它们如何与现有的信息检索技术相互补充,以提供更全面、更有效的检索解决方案。
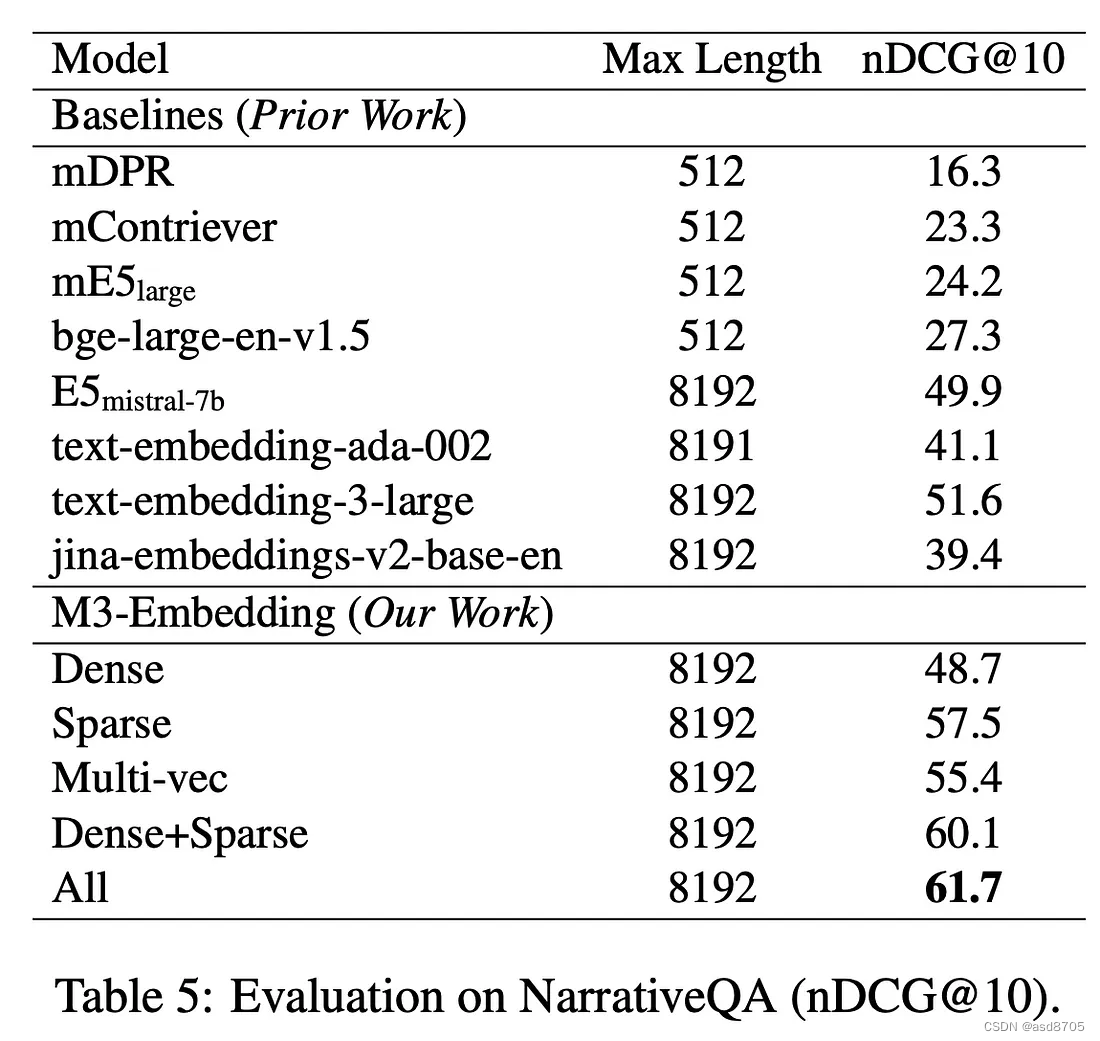
通过学习稀疏嵌入Learned sparse embeddings提供了一种独特的解决方式,将稀疏表示的可解释性与深度学习模型的上下文理解能力融合在一起。本文档旨在深入探讨,通过利用Milvus向量数据库,学习到的稀疏嵌入的工作机制、优势以及在实际应用中的潜力。这一讨论将揭示它们如何通过增强效率和可解释性,从根本上改变信息检索系统的运作方式。
从关键词匹配到上下文理解:信息检索方法的演变
在早期,信息检索系统主要依赖基于统计的关键词匹配方法,如词袋模型算法(如TF-IDF和BM25)。这些方法通过分析整个文档集合中术语的频率和分布来评估文档的相关性。尽管这些方法简单,但它们却极其丰富,在互联网爆炸性增长的时期成为了无处不在的工具。
2013年,谷歌推出了Word2Vec,这是首次尝试使用高维向量来表示单词并封装其语义细微差别。这一方法标志着信息检索方法从传统统计方法向基于机器学习的方法的初步转变。
随着BERT的出现,情况发生了巨大的变化。BERT是基于变换器的预训练语言模型,彻底改变了信息检索的最佳实践。借助注意力机制驱动的变换器,BERT捕获了文档的复杂上下文语义。它将它们压缩成密集向量,使得通过最近邻向量搜索对任何给定查询进行稳健且语义准确的检索成为可能。因此,由此引发了一系列重大进展,从根本上提高了检索过程的效率与效果。
三个月后,Nogueira 和 Cho 将BERT应用于MS MARCO段落排名任务。BERT在有效性上比之前的最佳方法IRNet提高了30%,比BM25基线高出了两倍。快进到2024年3月,文本排名分数已经达到了令人印象深刻的0.450和0.463,分别对应于评估和开发集。

这些进展凸显了信息检索方法的持续演变,标志着自然语言处理(NLP)领域神经时代的到来。
跨域信息检索挑战
像BERT这样的密集向量技术在信息检索中相对于传统的词袋模型提供了明显的优势。BERT的强大之处在于它能够理解文本中的细微上下文语义,这一特性显著提高了它在处理熟悉领域内的查询时的表现。
然而,当BERT尝试跨越熟悉的领域边界进行跨域检索(Out-of-Domain, OOD)时,它会遇到挑战。BERT的训练过程本质上使其偏向于训练数据的特性,这使得它在对OOD数据集中未见过的文本片段生成有意义的嵌入时表现不佳。这一限制在充斥着领域特定术语的数据集上表现得尤为明显。
缓解这一问题的一种潜在方法是微调(fine-tuning)。然而,这种方法并非总是可行或经济的。微调需要访问包含与目标领域相关的查询、正文档和负文档的中到大规模注释数据集。此外,创建这样的数据集需要领域专家的专业知识来保证数据质量,这一过程既费时又可能成本高昂。
另一方面,传统的词袋算法在跨域信息检索中尽管面临着词汇不匹配的问题(查询与相关文档之间的术语重叠通常不足),但在OOD检索中仍然优于BERT。这是因为在词袋算法中,未识别的术语不是“学习”的,而是进行精确的“匹配”。
学习稀疏嵌入:传统稀疏向量表示与上下文信息的融合
将确切术语匹配技术(如词袋方法)的强项与领域内或语义检索中稠密检索方法(如BERT)的强项相结合,一直是信息检索领域的一大追求。幸运的是,一种有前景的解决方案出现了:学习稀疏嵌入。
但学习稀疏嵌入到底是什么呢?
学习稀疏嵌入指的是通过复杂机器学习模型(如SPLADE和BGE-M3)构建的数据的稀疏向量表示。与仅依赖统计方法(如BM25)的传统稀疏向量不同,学习稀疏嵌入在保持关键词搜索能力的同时,通过引入上下文信息来丰富稀疏表示。它们能够识别文本中虽未明确出现但与相邻或相关词汇具有重要意义的隐含信息,从而形成一个“学习”得到的稀疏表示,能够捕捉到相关的关键词和类别。
以SPLADE为例。在编码给定文本时,SPLADE会产生一种以词到权重映射形式的稀疏嵌入,例如:
{"hello": 0.33, "world": "0.72"}乍一看,这些嵌入与由统计方法生成的传统稀疏嵌入看起来相似。然而,关键的区别在于它们的构成:维度(术语)和权重。携带上下文信息的机器学习模型决定了学习稀疏嵌入的维度(术语)和权重。
简而言之,学习稀疏嵌入是通过机器学习模型生成的,这些模型不仅考虑了文本中的关键词,还考虑了上下文信息,从而生成了更加丰富和具有语义理解能力的稀疏表示。这种嵌入方式能够更好地捕捉和利用文本中的语义信息,为信息检索提供更准确和相关的结果。
将稀疏表示与学习到的上下文相结合,为信息检索任务提供了一种强大的工具,能够无缝地链接精确术语匹配与语义理解之间,从而显著提升检索性能和结果的相关性。这种方法不仅能够高效地识别和匹配文本中的关键词,还能够理解文本之间的隐含关联和语义关系,使得信息检索更加精准、高效和智能化。这对于处理复杂、多变的信息检索场景尤为重要,如在大规模、多模态数据集中的跨领域检索任务,能够大幅提升检索系统的性能和用户体验。
与包含在长向量中的大量详细信息的密集嵌入不同,学习到的稀疏嵌入采取了一种更为精炼的方法,仅保留关键的文本信息。这种有意的简化有助于防止对训练数据的过拟合,增强模型在遇到跨域信息检索场景中新颖数据模式时的泛化能力。在未见过的数据上,稀疏嵌入能够更有效地区分和匹配文本,减少对特定领域特征的依赖,从而提高模型的适应性和鲁棒性。这使得它们在处理多样化、非典型数据时展现出优势,特别是在那些需要广泛覆盖不同领域知识的任务中。
通过优先考虑关键文本元素并丢弃多余细节,学习到的稀疏嵌入在捕获相关信息的同时避免了过拟合的陷阱,从而增强了它们在各种检索任务中的应用价值。这种平衡使得模型能够在保持高效处理能力的同时,对未知数据具有更好的泛化能力,尤其在跨领域、跨模态的信息检索任务中表现出色。此外,稀疏嵌入的特性有助于减少计算复杂性和存储需求,使其在资源受限的环境中也能高效运行。总的来说,它们为构建更加灵活、适应性强的信息检索系统提供了有力的技术支持。

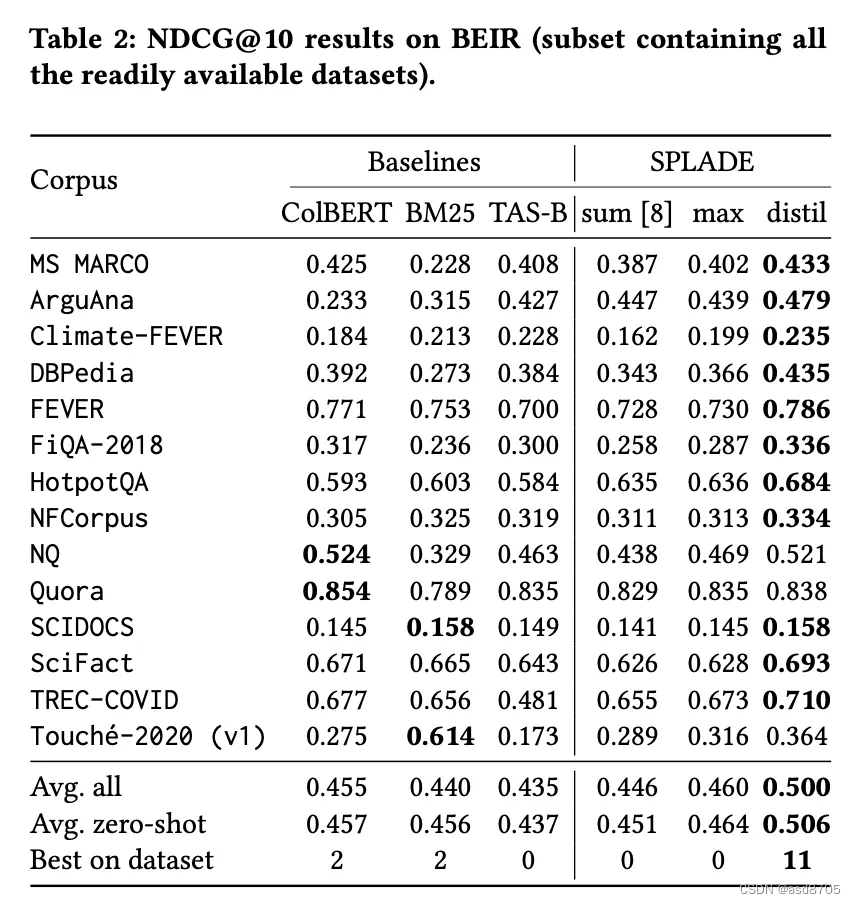
学习得到的稀疏嵌入在领域内信息检索中与密集检索方法表现出惊人的协同作用。根据BGE-M3作者进行的实验结果,学习得到的稀疏嵌入在多语言或跨语言检索任务中始终优于密集嵌入,展现出更高的准确率。更进一步地,当这些嵌入被整合使用时,它们的组合使用能够带来更大的准确率提升,这强调了稀疏检索技术和密集检索技术之间的互补性。这种协同效应不仅提升了信息检索的效率和精度,也为构建多语言、多模态的信息检索系统提供了理论基础和实践路径。
此外,这种嵌入的内在稀疏性使得向量相似性搜索变得轻松,只需要很少的计算资源即可完成。学习得到的稀疏嵌入的术语匹配特性增强了可解释性,因为你可以快速查看匹配的文档来识别对应的匹配词汇。这一特性使得能够对检索过程的底层机制进行更精确的洞察,从而提高系统的整体透明度和可用性。通过这种直观的匹配过程,用户可以更好地理解系统是如何找到相关结果的,从而增强用户对系统的信任和满意度。
A Showcase
This section demonstrates how learned sparse embeddings excel in situations where dense retrieval falls short.
Dataset: MIRACL.
Query: What years did Zhu Xi live?
Notes:
- Zhu Xi was a Chinese calligrapher, historian, philosopher, poet, and politician during the Song dynasty.
- The MIRACL dataset is multilingual, and we only use the “train” split of the English part in this showcase. It contains 26746 passages, seven of which are related to Zhu Xi.
We retrieved these seven relevant stories based on the query using dense and sparse retrieval methodologies, respectively. Initially, we encoded all stories into dense or sparse embeddings, respectively, and stored them in the Milvus vector database. Subsequently, we encoded the query and identified the top 10 stories closest to the query embedding using KNN search. Notably, the stories related to Zhu Xi are highlighted in bold in the following result:
Sparse Search Results(IP distance, larger is closer):
Score: 26.221 Id: 244468#1 Text: Zhu Xi, whose family originated in Wuyuan County, Huizhou …
Score: 26.041 Id: 244468#3 Text: In 1208, eight years after his death, Emperor Ningzong of Song rehabilitated Zhu Xi and honored him …
Score: 25.772 Id: 244468#2 Text: In 1179, after not serving in an official capacity since 1156, Zhu Xi was appointed Prefect of Nankang Military District (南康軍) …
Score: 23.905 Id: 5823#39 Text: During the Song dynasty, the scholar Zhu Xi (AD 1130–1200) added ideas from Daoism and Buddhism into Confucianism …
Score: 23.639 Id: 337115#2 Text: … During the Song Dynasty, the scholar Zhu Xi (AD 1130–1200) added ideas from Taoism and Buddhism into Confucianism …
Score: 23.061 Id: 10443808#22 Text: Zhu Xi was one of many critics who argued that …
Score: 22.577 Id: 55800148#11 Text: In February 1930, Zhu decided to live the life of a devoted revolutionary after leaving his family at home …
Score: 20.779 Id: 12662060#3 Text: Holding to Confucius and Mencius' conception of humanity as innately good, Zhu Xi articulated an understanding of "li" as the basic pattern of the universe …
Score: 20.061 Id: 244468#28 Text: Tao Chung Yi (around 1329~1412) of the Ming dynasty: Whilst Master Zhu inherited the orthodox teaching and propagated it to the realm of sages …
Score: 19.991 Id: 13658250#10 Text: Zhu Shugui was 66 years old (by Chinese reckoning; 65 by Western standards) at the time of his suicide …
Dense Search Results(L2 distance, smaller is closer):
Score: 0.600 Id: 244468#1 Text: Zhu Xi, whose family originated in Wuyuan County, Huizhou …
Score: 0.706 Id: 244468#3 Text: In 1208, eight years after his death, Emperor Ningzong of Song rehabilitated Zhu Xi and honored him …
Score: 0.759 Id: 13658250#10 Text: Zhu Shugui was 66 years old (by Chinese reckoning; 65 by Western standards) at the time of his suicide …
Score: 0.804 Id: 6667852#0 Text: King Zhaoxiang of Qin (; 325–251 BC), or King Zhao of Qin (秦昭王), born Ying Ji …
Score: 0.818 Id: 259901#4 Text: According to the 3rd-century historical text "Records of the Three Kingdoms", Liu Bei was born in Zhuo County …
Score: 0.868 Id: 343207#0 Text: Ruzi Ying (; 5–25), also known as Emperor Ruzi of Han and the personal name of Liu Ying (劉嬰), was the last emperor …
Score: 0.876 Id: 31071887#1 Text: The founder of the Ming dynasty was the Hongwu Emperor (21 October 1328–24 June 1398), who is also known variably by his personal name "Zhu Yuanzhang" …
Score: 0.882 Id: 2945225#0 Text: Emperor Ai of Tang (27 October 89226 March 908), also known as Emperor Zhaoxuan (), born Li Zuo, later known as Li Chu …
Score: 0.890 Id: 33230345#0 Text: Li Xi or Li Qi (李谿 per the "Zizhi Tongjian" and the "History of the Five Dynasties" or 李磎 per the "Old Book of Tang" …
Score: 0.893 Id: 172890#1 Text: The Wusun originally lived between the Qilian Mountains and Dunhuang (Gansu) near the Yuezhi …Look closer at the result: all 7 stories are ranked top 10 in sparse retrieval, while only 2 are ranked in the top 10 in dense retrieval. Both sparse and dense methods correctly identify passages numbered 244468#1 and 244468#3, yet dense retrieval fails to include any additional relevant stories. Instead, the eight other stories returned by the dense method pertain to Chinese historical narratives, which the model deems relevant but unrelated to our focal character, Zhu Xi.
If you’re eager to delve into the mechanics behind our approach, jump ahead to the next section, where we detail our vector search process using Milvus.
A Step-by-Step Guide: How to Perform Vector Search with Milvus
Milvus is an open-source vector database renowned for scalability and performance. The latest release, Milvus 2.4, offers beta support for both sparse and dense vectors. In this demo, we’ll use Milvus 2.4 to store the dataset and conduct vector searches.
We’ll also walk you through how to perform the query above, What years did Zhu Xi live? in Milvus against the MIRACL dataset.
We’ll use SPLADE and MiniLM-L6-v2 models to transform the query and the MIRACL source dataset into sparse and dense embeddings, respectively.
To begin our journey, let’s make a directory and set up the environment and the Milvus service. Make sure you have installed python(>=3.8), virtualenv, docker and docker-compose.
mkdir milvus_sparse_demo && cd milvus_sparse_demo
# spin up a milvus local cluster
wget https://github.com/milvus-io/milvus/releases/download/v2.4.0-rc.1/milvus-standalone-docker-compose.yml -O docker-compose.yml
docker-compose up -d
# create a virtual environment
virtualenv -p python3.8 .venv && source .venv/bin/activate
touch milvus_sparse_demo.pyStarting from version 2.4, pymilvus, the Python SDK for Milvus, introduces an optional `model` module. This module simplifies the process of encoding texts into sparse or dense embeddings using your preferred models. Additionally, to access the necessary datasets from HuggingFace, we utilize pip for installation.
pip install "pymilvus[model]" datasets tqdmFirst, download the dataset using the HuggingFace `Datasets` library, and collect all passages.
from datasets import load_dataset
miracl = load_dataset('miracl/miracl', 'en')['train']
# collect all passages in the dataset
docs = list({doc['docid']: doc for entry in miracl for doc in entry['positive_passages'] + entry['negative_passages']}.values())
print(docs[0])
# {'docid': '2078963#10', 'text': 'The third thread in the development of quantum field theory…'}Encode the queries:
from pymilvus import model
sparse_ef = model.sparse.SpladeEmbeddingFunction(
model_name="naver/splade-cocondenser-selfdistil",
device="cpu",
)
dense_ef = model.dense.SentenceTransformerEmbeddingFunction(
model_name='all-MiniLM-L6-v2',
device='cpu',
)
query = "What years did Zhu Xi live?"
query_sparse_emb = sparse_ef([query])
query_dense_emb = dense_ef([query])We can inspect the sparse embedding generated and find the tokens with the highest weights:
sparse_token_weights = sorted([(sparse_ef.model.tokenizer.decode(col), query_sparse_emb[0, col])
for col in query_sparse_emb.indices[query_sparse_emb.indptr[0]:query_sparse_emb.indptr[1]]], key=lambda item: item[1], reverse=True)
print(sparse_token_weights[:7])
# [('zhu', 3.0623178), ('xi', 2.4944391), ('zhang', 1.4790473), ('date', 1.4589322), ('years', 1.4154341), ('live', 1.3365831), ('china', 1.2351396)]Encode all the documents:
from tqdm import tqdm
doc_sparse_embs = [sparse_ef([doc['text']]) for doc in tqdm(docs, desc='Encoding Sparse')]
doc_dense_embs = [dense_ef([doc['text']])[0] for doc in tqdm(docs, desc='Encoding Dense')]Next, we create a collection in Milvus to store everything, including the doc id, texts, dense and sparse embeddings and insert the entire dataset.
from pymilvus import (
MilvusClient, FieldSchema, CollectionSchema, DataType
)
milvus_client = MilvusClient("http://localhost:19530")
collection_name = 'miracl_demo'
fields = [
FieldSchema(name="doc_id", dtype=DataType.VARCHAR, is_primary=True, auto_id=False, max_length=100),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=65530),
FieldSchema(name="sparse_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
FieldSchema(name="dense_vector", dtype=DataType.FLOAT_VECTOR, dim=384),
]
milvus_client.create_collection(collection_name, schema=CollectionSchema(fields, "miracl demo"), timeout=5, consistency_level="Strong")
batch_size = 30
n_docs = len(docs)
for i in tqdm(range(0, n_docs, batch_size), desc='Inserting documents'):
milvus_client.insert(collection_name, [
{
"doc_id": docs[idx]['docid'],
"text": docs[idx]['text'],
"sparse_vector": doc_sparse_embs[idx],
"dense_vector": doc_dense_embs[idx]
}
for idx in range(i, min(i+batch_size, n_docs))
])To speed up the search process, we create indexes for the vector fields:
index_params = milvus_client.prepare_index_params()
index_params.add_index(
field_name="sparse_vector",
index_type="SPARSE_INVERTED_INDEX",
metric_type="IP",
)
index_params.add_index(
field_name="dense_vector",
index_type="FLAT",
metric_type="L2",
)
milvus_client.create_index(collection_name, index_params=index_params)
milvus_client.load_collection(collection_name)Now we can perform the search and inspect the result:
k = 10
sparse_results = milvus_client.search(collection_name, query_sparse_emb, anns_field="sparse_vector", limit=k, search_params={"metric_type": "IP"}, output_fields=['doc_id', 'text'])[0]
dense_results = milvus_client.search(collection_name, query_dense_emb, anns_field="dense_vector", limit=k, search_params={"metric_type": "L2"}, output_fields=['doc_id', 'text'])[0]
print(f'Sparse Search Results:')
for result in sparse_results:
print(f"\tScore: {result['distance']} Id: {result['entity']['doc_id']} Text: {result['entity']['text']}")
print(f'Dense Search Results:')
for result in dense_results:
print(f"\tScore: {result['distance']} Id: {result['entity']['doc_id']} Text: {result['entity']['text']}")You’ll see the following output. In the results of dense retrieval, only the first two stories are related to Zhu Xi. I trimmed the texts for readability.
Sparse Search Results:
Score: 26.221 Id: 244468#1 Text: Zhu Xi, whose family originated in Wuyuan County, Huizhou ...
Score: 26.041 Id: 244468#3 Text: In 1208, eight years after his death, Emperor Ningzong of Song rehabilitated Zhu Xi and honored him ...
Score: 25.772 Id: 244468#2 Text: In 1179, after not serving in an official capacity since 1156, Zhu Xi was appointed Prefect of Nankang Military District (南康軍) ...
Score: 23.905 Id: 5823#39 Text: During the Song dynasty, the scholar Zhu Xi (AD 1130–1200) added ideas from Daoism and Buddhism into Confucianism ...
Score: 23.639 Id: 337115#2 Text: ... During the Song Dynasty, the scholar Zhu Xi (AD 1130–1200) added ideas from Taoism and Buddhism into Confucianism ...
Score: 23.061 Id: 10443808#22 Text: Zhu Xi was one of many critics who argued that ...
Score: 22.577 Id: 55800148#11 Text: In February 1930, Zhu decided to live the life of a devoted revolutionary after leaving his family at home ...
Score: 20.779 Id: 12662060#3 Text: Holding to Confucius and Mencius' conception of humanity as innately good, Zhu Xi articulated an understanding of "li" as the basic pattern of the universe ...
Score: 20.061 Id: 244468#28 Text: Tao Chung Yi (around 1329~1412) of the Ming dynasty: Whilst Master Zhu inherited the orthodox teaching and propagated it to the realm of sages ...
Score: 19.991 Id: 13658250#10 Text: Zhu Shugui was 66 years old (by Chinese reckoning; 65 by Western standards) at the time of his suicide ...
Dense Search Results:
Score: 0.600 Id: 244468#1 Text: Zhu Xi, whose family originated in Wuyuan County, Huizhou ...
Score: 0.706 Id: 244468#3 Text: In 1208, eight years after his death, Emperor Ningzong of Song rehabilitated Zhu Xi and honored him ...
Score: 0.759 Id: 13658250#10 Text: Zhu Shugui was 66 years old (by Chinese reckoning; 65 by Western standards) at the time of his suicide ...
Score: 0.804 Id: 6667852#0 Text: King Zhaoxiang of Qin (; 325–251 BC), or King Zhao of Qin (秦昭王), born Ying Ji ...
Score: 0.818 Id: 259901#4 Text: According to the 3rd-century historical text "Records of the Three Kingdoms", Liu Bei was born in Zhuo County ...
Score: 0.868 Id: 343207#0 Text: Ruzi Ying (; 5 – 25), also known as Emperor Ruzi of Han and the personal name of Liu Ying (劉嬰), was the last emperor ...
Score: 0.876 Id: 31071887#1 Text: The founder of the Ming dynasty was the Hongwu Emperor (21 October 1328 – 24 June 1398), who is also known variably by his personal name "Zhu Yuanzhang" ...
Score: 0.882 Id: 2945225#0 Text: Emperor Ai of Tang (27 October 89226 March 908), also known as Emperor Zhaoxuan (), born Li Zuo, later known as Li Chu ...
Score: 0.890 Id: 33230345#0 Text: Li Xi or Li Qi (李谿 per the "Zizhi Tongjian" and the "History of the Five Dynasties" or 李磎 per the "Old Book of Tang" ...
Score: 0.893 Id: 172890#1 Text: The Wusun originally lived between the Qilian Mountains and Dunhuang (Gansu) near the Yuezhi ...Finally, clean up.
docker-compose down
cd .. && rm -rf milvus_sparse_demo总结
总的来说,探索学习得到的稀疏嵌入揭示了信息检索方法学的一个范式转变。通过利用传统稀疏表示与上下文信息的融合,这些嵌入提供了一种多面的解决方案,能够应对精确术语匹配和语义理解的固有挑战。
我们观察到,学习得到的稀疏嵌入在捕捉相关关键词和类别的同时保持可解释性,从而在信息检索任务中实现了效率和清晰度之间的微妙平衡。它们与密集检索方法的协同集成进一步提高了准确性和性能,强调了它们在现代信息检索系统中的不可或缺性。
通过使用Milvus进行实际演示,我们展示了学习得到的稀疏嵌入在现实世界场景中的实际好处,展示了它们在精确和高效地检索相关信息方面的强大能力。这一过程不仅验证了理论上的优势,也提供了实用的指导,有助于开发和优化未来的信息检索系统。
References
- Devlin, J., Chang, M.W., Lee, K. and Toutanova, K., 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Thakur, N., Reimers, N., Rücklé, A., Srivastava, A. and Gurevych, I., 2021. Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models. arXiv preprint arXiv:2104.08663.
- Bajaj, P., Campos, D., Craswell, N., Deng, L., Gao, J., Liu, X., Majumder, R., McNamara, A., Mitra, B., Nguyen, T. and Rosenberg, M., 2016. Ms marco: A human generated machine reading comprehension dataset. arXiv preprint arXiv:1611.09268.
- Lin, J., Nogueira, R. and Yates, A., 2022. Pretrained transformers for text ranking: Bert and beyond. Springer Nature.
- Chen, J., Xiao, S., Zhang, P., Luo, K., Lian, D. and Liu, Z., 2024. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. arXiv preprint arXiv:2402.03216.
- Formal, T., Piwowarski, B. and Clinchant, S., 2021, July. SPLADE: Sparse lexical and expansion model for first stage ranking. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 2288–2292).
- Formal, T., Lassance, C., Piwowarski, B. and Clinchant, S., 2021. SPLADE v2: Sparse lexical and expansion model for information retrieval. arXiv preprint arXiv:2109.10086.
- Lassance, C., Déjean, H., Formal, T. and Clinchant, S., 2024. SPLADE-v3: New baselines for SPLADE. arXiv preprint arXiv:2403.06789.
- Chen, C., Zhang, B., Cao, L., Shen, J., Gunter, T., Jose, A.M., Toshev, A., Shlens, J., Pang, R. and Yang, Y., 2023. Stair: Learning sparse text and image representation in grounded tokens. arXiv preprint arXiv:2301.13081.
- Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J. and Krueger, G., 2021, July. Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748–8763). PMLR.
- Chen, T., Zhang, M., Lu, J., Bendersky, M. and Najork, M., 2022, April. Out-of-domain semantics to the rescue! zero-shot hybrid retrieval models. In European Conference on Information Retrieval (pp. 95–110). Cham: Springer International Publishing.
- Mikolov, T., Chen, K., Corrado, G. and Dean, J., 2013. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
- MS Marco Leaderboard
- MIRACL 🌍🙌🌏 (Multilingual Information Retrieval Across a Continuum of Languages) Dataset
- Zhu Xi — Wikipedia















 806
806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









