







 本文整理了SAP BW系统中涉及的多种技术细节和最佳实践,包括Query查询注意事项、DSO和Cube的管理、传输请求、授权控制、数据加载策略等。通过这些技巧,可以提升SAP BW的开发效率和系统性能。
本文整理了SAP BW系统中涉及的多种技术细节和最佳实践,包括Query查询注意事项、DSO和Cube的管理、传输请求、授权控制、数据加载策略等。通过这些技巧,可以提升SAP BW的开发效率和系统性能。
1 同一个变量名的UID可能有多个,记得注意
2 在查找时要注意技术名称还是名称,因为查询时会在两个中进行,模糊查询时要细心,FV与V都可以查到
3 复制的时候注意长度,过长的会不能显示
4 开着Query不能删除
5 se01 Transport Organizer
6 行列只是用来放特征和关键值
7 行和列都是死的是固定报表,行和列都是灵活的是灵活报表,行或列有一个是死的,有一个是灵活的是半灵活报表
8 SAP portal增量链接的时候别忘记打开目的地,不然不会显示菜单的
9 P采购 purchasing,I库存 inventory
10 传输请求的时候,DSO传输过,转换会变灰,就是说底层变,上层会有问题
11 M版本不等于A版本,可能是修改以后没有激活
12 SID -- Surrogate-ID
13 YTD,QTD,PTD 年初至今,季初至今,期初至今
14 BOM 物料清单
15 报表和BEx请求要进ZBW_LYHG包,其余的都进ZBW包
16 请求出错,到英文系统看明细日志
17 mb51,收+,发-
18 312为测试系统,300-302,200-222
19 收集转换的时候要收集例程,收集DTP的时候要带信息包
20 se03 显示/更改命名空间,可以看到类似于/BIO/ /BIC/的文本描述
/BI0/ 业务信息仓库:SAP 命名空间 SAP AG Walldorf
/BIC/ 业务信息仓库:客户命名空间 客户名称空间
21 有时候,结果行的显示会有错误,可以再Query里将 计算结果 改为 合计
22 主链修改后需要计划之,即执行
23 做完报表要传Portal的
24 用户出口:SD,绑定给一个,不能重用;客户出口,ALL;BTE业务交易事件,FI;BADI业务附加(NEW),用户出口与BTE的结合
25 RRM_SV_VAR_WHERE_USED_LIST_GET
26 01交易数据,02主数据,03层次,04空
27 压缩:F事实表压缩至E事实表,压缩之后F表清空,直接从E表取数,加快速度。如果有聚集,要先上传至聚集,再压缩。
28 开发类:逻辑上相关的一组对象,也就是说,这组对象必须一起开发、维护和传输
本地对象:将对象指派给$TMP,不可传输到其他系统
自建开发类:以Y或者Z开头
29 CCMS: Computer center Management System
30 TCODE: SSAA
31 关于DB Statistics,计算统计数据时,SAP_ANALYZE_ALL_INFOCUBES
使用的信息立方体数据量<=20%时,BW将会使用10%的信息立方体数据来估计统计数据,
否则,BW将计算实际的统计数据。此时,Oracle PL/SQL包DBMS_STATS就是更好的选择,如果可能会调用并行的查询来收集统计数据;否则调用一个顺序查询或者ANALYZE语句。索引统计数据并不是并行收集的。TCODE: DB20
32 每次加载数据时,自动刷新统计信息:Environment-->Automatic Request Processing
33 分区查看:SE11-->Utilities-->Database Object-->Database Utilities-->Storage Parameters-->Partition
34 分区管理:打开Cube-->Extras-->DB Performance-->Partitioning,来个例子,很简单的解释,很透彻
我选择额的是0CALMONTH,按月来分区:
Example
Value range for FYear/Calendar Month
- from 01.1998
- to 12.2003
6 Years * 12 Months + 2 = 74 partitions will be created (2 partitions for values that lie outside of the range, meaning <01.1998 or > 12.2003).
35 如果可能,在传输规则而不是更新规则中执行数据的转换。传输规则:PSA-->DSO,更新规则:DSO-->Cube
36 考虑使用数据库的NOARCHIVELOG模式
37 将实例的描述参数rdisp/max_wprun_time设置为0,允许对话工作进程占用无限的CPU时间
38 加载交易数据时:
1、加载所有的主数据
2、删除信息立方体及其聚集的索引
3、打开数字范围缓冲(Number range buffering)
4、设置一个合适的数据包大小
5、加载交易数据
6、重建索引
7、关闭数字范围缓冲
8、刷新统计数据
39 事实表命名:</BIC|/BIO>/F<信息立方体名>,同理,E事实表
| </BIC|/BIO>/D<信息立方体名>P |
数据包维度 |
Package |
| </BIC|/BIO>/D<信息立方体名>T |
时间维度 |
Time |
| </BIC|/BIO>/D<信息立方体名>U |
单位维度 |
Unit |
40 SID:Surrogate-ID(替代标识)
| </BIC|/BIO>/S<特征名> |
SID表 |
| </BIC|/BIO>/P<特征名> |
主数据表 |
| </BIC|/BIO>/T<特征名> |
文本表 |
| </BIC|/BIO>/H<特征名> |
层次表 |
| </BIC|/BIO>/I<特征名> |
层次表I |
| </BIC|/BIO>/K<特征名> |
层次表K |
| </BIC|/BIO>/S<特征名> |
层次表S |
| </BIC|/BIO>/M<特征名> |
主数据视图 |
维度表和SID表之间,主数据表和SID表之间,都是虚线关系,虚线关系表示由ABAP程序维护,不受到外键补充。使得我们能够加载交易数据,即使数据库中不存在任何主数据也可以。Always update data, even if no master data exists for the data!
41 BW多种建模,参照BW Accelerator, Multi-Dimensional Modeling with BW
42 维度特征 or 维度属性:
1、如果**数据包含在交易数据中,那么应将**用作为维度特征,而不要用做维度属性。
2、如果**频繁用于导航,那么应将**用做维度特征,而不要用做维度属性。
43 维度:
1、如果特征具有一对多的关系,那么应将它们组合在同一维度中。
2、如果特征具有多对多的关系,那么应将他们组合在不同维度中。(合并关系很小除外)
44 复合属性(组合属性 Compounding):
除非绝对必要,不要采用复合属性,代价比较大。
理解:IO_HOUSE拥有一条White house的记录,为了区别是来自政府源系统还是家居网站,将IO_HOUSE和0SOURCESYSTEM复合起来澄清特征的具体含义。
45 线性项维度:
如果维度只有一个特征,可以设为线性项特征。导致并未创建维度表,关键字是SID表的SID,事实表通过SID表连接到主数据、文本和层级表,同时删除了维度表的一个中间层,提高效率。
46 粒度(Granularity):信息具体的程度
47 PSA:数据以包为单位进行传输
48 IDoc:数据以IDoc为单位进行传输,字符格式中,传输结构不能超过1000字节
49 BW收集传输数据步骤:
1、BW传递一个加载请求IDoc给R/3
2、在加载请求IDoc触发时,R/3将启动一个后台任务。后台任务从数据库中收集数据,并保存在事先定义好大小的包中
3、收集了第一个数据包以后,后台任务启动一个对话工作进程(如果可用),将第一个数据包从R/3传递给BW
4、如果需要传递更多数据,后台工作将继续收集第二个包的数据,而不必等第一个数据包完成其传递过程。收集完毕发送
5、在前面的步骤进行时,R/3传递信息IDoc给BW,通知BW数据抽取的传输状态
6、按照上面的方式过程继续进行,直到所有请求的数据得以传输和选择
因此,信息包的大小很重要

上面两张图,一个是表ROIDOCPRMS,里面存储的是关于信息包的设置
设置方法:SBIW-->General Settings-->Maintain Control Parameters for Data Transfer
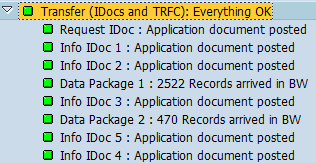
另一个是数据抽取的过程:几个IDoc的Info status分别是:
| 0 |
Data request received |
| 1 |
Data selection started |
| 2 |
Data selection running |
| 5 |
Error in data selection |
| 6 |
Transfer structure obsolete, transfer rules regeneration |
| 8 |
No data available, data selection ended |
| 9 |
Data selection ended |
这里的几个状态分别为:
| Info IDoc 1 |
Info Idoc 2 |
Info Idoc 3 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1237
1237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









