









题目:


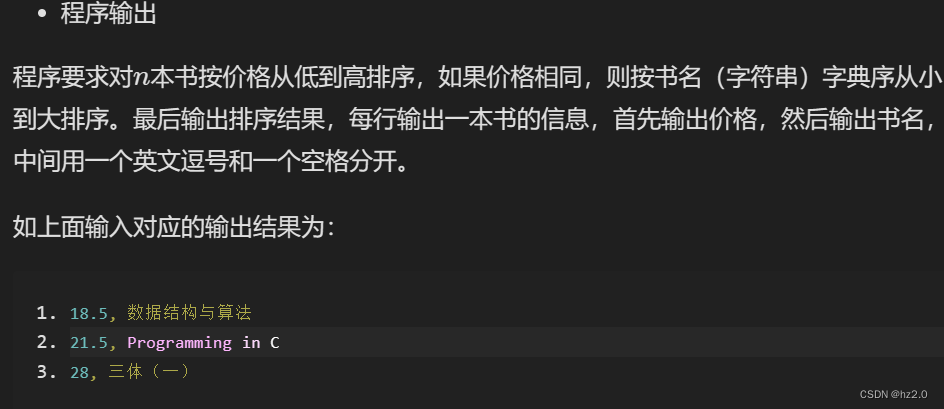
思路:
1.字符串字典序排序---> 利用string.h里面的strcmp,由其返回值确定两字符串大小。(p=strcmp(a,b),若p>1,则a字典序大于b。)
2.当不能定义字符串string时,只能用字符数组来容纳字符串。但字符数组不可以向string定义的字符串那样用cin一次性输入,需要for循环一个字符一个字符的cin,太复杂了,故这里我们用cin.getline(arr,len)一次性输入一行字符(这样就相当于输入一个字符串了)。
3.特别注意:在每次cin.getline之前要用getchar()吸收掉前面cin结束后留下的回车符!
代码:
#include <string.h>
#include <iostream>
using namespace std;
typedef struct _book
{
float price;
char name[50];
}mybook;
int main()
{
int n,i,j,min;
mybook book[55];
cin >> n;
for (i = 0; i < n; i++) {
getchar(); //!!!!吸收掉上面 cin>>n 时输入的回车符号
cin.getline(book[i].name, 55);//name被定义为字符而非字符串,不可以只通过一个cin输入,故用getline
cin>> book[i].price;
}
//选择排序
for (i = 0; i < n-1; i++) {
min = i;
for (j = i + 1; j < n; j++) {
if (book[j].price < book[min].price)min = j;
//在价格相等的情况下比较书名字典序--->字符串比字典序用strcpy
else if (book[min].price == book[j].price && strcmp(book[min].name, book[j].name)>0)min = j;
}
//交换(结构体可以理解多赋值,直接赋值不用重载"=")
if (min != i) {
mybook t;
t = book[min];
book[min] = book[i];
book[i] = t;
}
}
//输出
for (i = 0; i < n; i++)cout << book[i].price << ", " << book[i].name << "\n";
}















 1754
1754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











