







文章目录
关键字
- 定义:被Java语言赋予了特殊含义,用做专门用途的字符串(单词)
- 特点:关键字中所有字母都为小写
保留字
- 现有Java版本尚未使用,但以后版本可能会作为关键字使用。
- 自己命名标识符时要避免使用这些保留字,例如: goto 、const
标识符
- Java 对各种变量、方法和类等要素命名时使用的字符序列称为标识符
- 技巧:凡是自己可以起名字的地方都叫标识符。
- 定义合法标识符规则
- 由26个英文字母大小写,0-9 ,_或 $ 组成
- 数字不可以开头。
- 不可以使用关键字和保留字,但能包含关键字和保留字
- Java中严格区分大小写,长度无限制
- 标识符不能包含空格
- Java中的名称命名规范
- 包名:多单词组成时所有字母都小写:xxxyyyzzz
- 类名、接口名:多单词组成时,所有单词的首字母大写:XxxYyyZzz
- 变量名、方法名:多单词组成时,第一个单词首字母小写,第二个单词开始每个 单词首字母大写:xxxYyyZzz
- 常量名:所有字母都大写。多单词时每个单词用下划线连接:XXX_YYY_ZZZ
变量
变量的分类
按数据类型分:

按声明的位置的不同:
- 在方法体外,类体内声明的变量称为成员变量
- 在方法体内部声明的变量称为局部变量。
- 注意:二者在初始化值方面的异同:
- 同:都有生命周期 异:局部变量除形参外,需显式初始化。

整数类型
| 类型 | 占用储存空间 | 表示数的范围 |
|---|---|---|
| byte | 1字节 = 8 bit位 | -128 ~ 127 |
| short | 2字节 | -215 ~215-1 |
| int | 4字节 | -215 ~215-1 |
| long | 8字节 | -263 ~ 263-1 |
- Java的整型常量默认为 int 型,声明long型常量须后加‘l’或‘L’
- Java程序中变量通常声明为int型,除非不足以表示较大的数,才使用long
- bit: 计算机中的最小存储单位。byte:计算机中基本存储单元。
浮点类型
| 类型 | 占用储存空间 | 表示数的范围 |
|---|---|---|
| 单精度float | 4字节 | -3.403E38 ~ 3.403E38 |
| 双精度double | 8字节 | -1.798E308 ~ 1.798E308 |
- float:单精度,尾数可以精确到7位有效数字。很多情况下,精度很难满足需求。
- double:双精度,精度是float的两倍。通常采用此类型。
- Java 的浮点型常量默认为double型,声明float型常量,须后加‘f’或‘F’。
字符类型
-
char 型数据用来表示通常意义上“字符”(2字节)
-
Java中的所有字符都使用Unicode编码,故一个字符可以存储一个字 母,一个汉字,或其他书面语的一个字符
-
三种表现形式:
- 字符常量是用单引号(‘ ’)括起来的单个字符
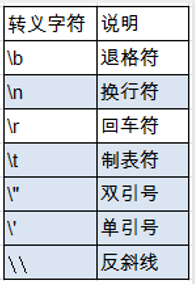
- 转义字符‘\’来将其后的字符转变为特殊字符型常量
- 直接使用 Unicode 值来表示字符型常量:‘\uXXXX’。其中,XXXX代表 一个十六进制整数。如:\u000a 表示 \n。
-
char类型是可以进行运算的。因为它都对应有Unicode码。
注:字符型不是必须要加’'
//这种写法就是将int类型的97强制类型转换成char型对应的ASCLL码
char c = 97;
System.out.println(c); //a
char c = '5'; //字符5,对应ASCLL码为53,所以运算时便转成对应ASCLL码为53
char c1 = 5; //对应为ASCLL码为5的字符
int i = c + 1; //54 (自动类型转换)
int i1 = c1 + 1; //6
布尔类型
- boolean 类型用来判断逻辑条件,一般用于程序流程控制
- boolean类型数据只允许取值true和false,无null。
基本数据类型转换
- 自动类型转换:容量小的类型自动转换为容量大的数据类型。数据类型按容 量大小排序为:

- 有多种类型的数据混合运算时,系统首先自动将所有数据转换成容量最大的那种数据类型,然后再进行计算
- 说明:此时的容量大小指的是,表示数的范围的大和小。比如:float容量要大于long的容量
- byte,short,char之间不会相互转换,他们三者在计算时首先转换为int类型。
- boolean类型不能与其它数据类型运算。
- 当把任何基本数据类型的值和字符串(String)进行连接运算时(+),基本数据类型的值将自动转化为字符串(String)类型。
特殊情况:
//不报错,是因为后面没写L时,会认为这个数是int类型,自动类型提升为long型
long l = 123456;
//编译失败,过大的整数
long l1 = 123456789123;
//错误:不兼容的类型:从double装换到float可能会有损失
float f1 = 12.3;
//通过
float f1 = (float)12.3;
//错误:不兼容的类型:从int转换到byte可能会有损失
byte b = 12;
byte b1 = b + 1;
//直接按String进行计算
boolean b = false;
String s = "123" + b; //123false
String s = 123; //错误:不兼容的类型:int无法转换为String
String s1 = 123 + ""; //可以
字符串类型
- String不是基本数据类型,属于引用数据类型
注意:
//报错:char型里必须要有一个字符
char c = '';
//错误:String类型只能用""表示
String s1 = '';
//通过
String s = "";
char c = 'a'; //97 A:65
int num = 10;
String str= "hello";
System.out.println(c + num + str); //107hello
System.out.println(c + str + num); //ahello10
System.out.println(c + (num + str)); //a10hello
System.out.println((c + num) + str); //107hello
System.out.println(str + num + c); //hello10a
//* *
System.out.println("* *");
System.out.println('*' + '\t' + '*'); //93,一个*42,一个\t9
System.out.println('*' + "\t" + '*');
System.out.println('*' + '\t' + "*"); //51*
System.out.println('*' + ('\t' + "*"));
以上说明:用字符进行 + 时,会对应它的ASCII 码进行计算,当有Strng加入时,会全部转为字符串进行连接处理
强制类型转换
-
自动类型转换的逆过程,将容量大的数据类型转换为容量小的数据类型。使用时要加上强制转换符:() ,但可能造成精度降低或溢出,格外要注意。
-
//截断操作,向下取整 double d1 = 12.9; int i1 = (int)d1; //12 int i2 = 128; byte b = (byte)i2; //-128
-
-
通常,字符串不能直接转换为基本类型,但通过基本类型对应的包装类则可以实现把字符串转换成基本类型。
-
String a = “43”; int i = Integer.parseInt(a); -
boolean类型不可以转换为其它的数据类型。
-
ASCII 码(了解)
- 在计算机内部,所有数据都使用二进制表示。每一个二进制位(bit)有 0 和 1 两种状态, 因此 8 个二进制位就可以组合出 256 种状态,这被称为一个字节(byte)。一个字节一 共可以用来表示 256 种不同的状态,每一个状态对应一个符号,就是 256 个符号,从 0000000 到 11111111。
- ASCII码:上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的 关系,做了统一规定。这被称为ASCII码。ASCII码一共规定了128个字符的编码,比如 空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。这 128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前 面的1位统一规定为0。
- 缺点:
- 不能表示所有字符。
- 相同的编码表示的字符不一样:比如,130在法语编码中代表了é,在希伯来语编码中却代表 了字母Gimel ( )
Unicode 编码(了解)
- 乱码:世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因 此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读, 就会出现乱码。
- Unicode:一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一 无二的编码,使用 Unicode 没有乱码的问题。
- Unicode 的缺点:Unicode 只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储:无法区别 Unicode 和ASCII:计算机无法区分三个字节表示一个符号还是分别表示三个符号。另外,我们知道,英文字母只用一个字节表示就够了,如果 unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储空间来说是极大的浪费。
UTF-8 (了解)
- UTF-8 是在互联网上使用最广的一种 Unicode 的实现方式。
- UTF-8 是一种变长的编码方式。它可以使用 1-6 个字节表示一个符号,根据不同的符号而变化字节长度。
- UTF-8的编码规则:
- 对于单字节的UTF-8编码,该字节的最高位为0,其余7位用来对字符进行编码(等同于 ASCII码)。
- 对于多字节的UTF-8编码,如果编码包含 n 个字节,那么第一个字节的前 n 位为1,第一 个字节的第 n+1 位为0,该字节的剩余各位用来对字符进行编码。在第一个字节之后的 所有的字节,都是最高两位为"10",其余6位用来对字符进行编码。
进制
- 所有数字在计算机底层都以二进制形式存在。
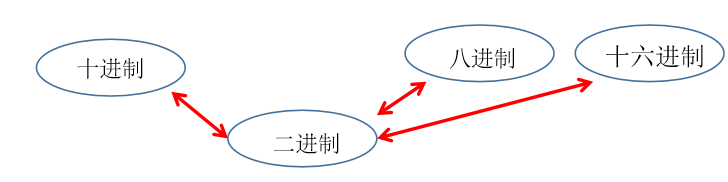
- 对于整数,有四种表示方式:
- 二进制(binary):0,1 ,满2进1.以0b或0B开头。
- 十进制(decimal):0-9 ,满10进1。
- 八进制(octal):0-7 ,满8进1. 以数字0开头表示。
- 十六进制(hex):0-9及A-F,满16进1. 以0x或0X开头表示。此处的A-F不区分大小写。 如:0x21AF +1= 0X21B0
二进制
- Java整数常量默认是int类型,当用二进制定义整数时,其第32位是符号位; 当是long类型时,二进制默认占64位,第64位是符号位
- 二进制的整数有如下三种形式:
- 原码:直接将一个数值换成二进制数。最高位是符号位
- 负数的反码:是对原码按位取反,只是最高位(符号位)确定为1。
- 负数的补码:其反码加1。
- 计算机以二进制补码的形式保存所有的整数
- 正数的原码、反码、补码都相同
- 负数的补码是其反码+1
- 为什么要使用原码、反码、补码表示形式呢?
- 计算机辨别“符号位”显然会让计算机的基础电路设计变得十分复杂! 于是人们想出了将符号位也参与运算的方法. 我们知道, 根据运算法则减去一个正数等于加上一个负数, 即: 1-1 = 1 + (-1) = 0 , 所以机器可以只有加法而没有减法, 这样计算机运算的设计就更简单了。



所以在一个int型的128在强转成byte时变成-128的原因是:
- 计算机辨别“符号位”显然会让计算机的基础电路设计变得十分复杂! 于是人们想出了将符号位也参与运算的方法. 我们知道, 根据运算法则减去一个正数等于加上一个负数, 即: 1-1 = 1 + (-1) = 0 , 所以机器可以只有加法而没有减法, 这样计算机运算的设计就更简单了。
int i = 128;
byte b = (byte)i; //-128

进制之间的转换



进制转换的方法:

String string = Integer.toBinaryString(127); //1111111
String string1 = Integer.toHexString(127); //7f
String string2 = Integer.toOctalString(127); //177
运算符
算术运算符

除号
int num1 = 12;
int num2 = 5;
double result = num1 / num2; //2.0
double result1 = num1 / (double)num2; //2.4
double result2 = 0.0 + num1 / num2; //2.0
double result3 = (double)num1 / num2; //2.4
double result4 = (double)(num1 / num2); //2.0
result为2.0是因为num1 / num2结果为2.4,转成int型为2,然后用double接收后向上转型为2.0
result1和result3都是先把一个数转成double型,进行计算得到的结果为2.4
result2是先算出num1 / num2为2,然后加0.0转成double为2.0,再用double接收为2.0
result4也是先算num1 / num2再整体转成double,所以结果也为2.0
取模
- 结果的符号与被模数的符号相同
- 如果对负数取模,可以把模数负号忽略不记,如:5%-2=1。 但被模数是负数则不可忽略。此外,取模运算的结果不一定总是整数。
自增
byte b = 127;
b++;
System.out.print(b); //-128
赋值运算符
- +=不改变本身数据的类型
short s = 3;
s = s + 2; //编译不通过,因为后面计算的结果为int型不能用short接收
s += 2; //说明+=的区别是不改变本身数据的类型
int i = 1;
i *= 0.1; //0
int m = 2;
int n = 3;
n *= m++; //n = n * m++;
System.out.println("m=" + m); //m=3
System.out.println("n=" + n); //n=6
int n = 10;
n += (n++) + (++n); //n = n + (n++) + (++n); 10 + 10 + 11,这段执行返回的n为31,执行完后再n++,n最后为32
System.out.println(n); //32
比较运算符

- 比较运算符的结果都是boolean型,也就是要么是true,要么是false。
- 比较运算符“= =”不能误写成“=”
逻辑运算符

- “&”和“&&”的区别:
- 单&时,左边无论真假,右边都进行运算;
- 双&时,如果左边为真,右边参与运算,如果左边为假,那么右边不参与运算。
- “|”和“||”的区别同理,||表示:当左边为真,右边不参与运算。
- 异或( ^ )与或( | )的不同之处是:当左右都为true时,结果为false。
- 区分逻辑运算符和位运算符:
- 逻辑运算符两边的是boolean类型,而位运算符两边是int型
笔试题
public class E {
public static void main(String[] args) {
boolean x = true;
boolean y = false;
short z = 42;
//if(y == true)
if ((z++ == 42) && (y = true)) z++; //z = 44,y = true
//x = false:这里先是进行赋值操作,把false赋值给x,然后再判断x为false
if ((x = false) || (++z == 45)) z++; //x = false,z = 46
System.out.println("z =" + z); //46
}
}
位运算符

- 位运算是直接对整数的二进制进行的运算
- << :在一定范围内,每向左移1位,相当于 * 2
- .>> :在一定范围内,每向右移1位,相当于 / 2

面试题
你能写出最高效的2 * 8的实现方式?
2 << 3
8 << 1
三元运算符
格式:

- 表达式1和表达式2为同种类型
- 如何表达式一是int型,表达式二是double型,那么表达式一的值也会自动类型提升为double型,以保证为同种类型
- 三元运算符与if-else的联系与区别:
- 三元运算符可简化if-else语句
- 三元运算符要求必须返回一个结果。
- if后的代码块可有多个语句
- 条件表达式的结果为boolean类型
运算符的优先级

程序流程控制
-
顺序结构
- 程序从上到下逐行地执行,中间没有任何判断和跳转。
-
分支结构
-
根据条件,选择性地执行某段代码
-
if…else和switch-case两种分支语句
-
-
循环结构
- 根据循环条件,重复性的执行某段代码
- 有while、do…while、for三种循环语句
- 注:JDK1.5提供了foreach循环,方便的遍历集合、数组元素。
if-else结构
使用说明:
- 条件表达式必须是布尔表达式(关系表达式或逻辑表达式)、布尔变量
- 语句块只有一条执行语句时,一对{}可以省略,但建议保留
- if-else语句结构,根据需要可以嵌套使用
- 当if-else结构是“多选一”时,最后的else是可选的,根据需要可以省略
- 当多个条件是“互斥”关系时,条件判断语句及执行语句间顺序无所谓;当多个条件是“包含”关系时,“小上大下 / 子上父下”
switch-case结构
规程:
- switch(表达式)中表达式的值必须是下述几种类型之一:byte,short, char,int,枚举 (jdk 5.0),String (jdk 7.0)
- case子句中的值必须是常量,不能是变量名或不确定的表达式值
- 同一个switch语句,所有case子句中的常量值互不相同
- break语句用来在执行完一个case分支后使程序跳出switch语句块;如果没有break,程序会顺序执行到switch结尾
- default子句是可任选的。同时,位置也是灵活的。当没有匹配的case时, 执行default
switch和if语句的对比
- 使用switch-case的,都可以改写为if-else。反之不成立。
- 如果判断的具体数值不多,而且符合byte、short 、char、int、String、枚举等几 种类型。虽然两个语句都可以使用,建议使用swtich语句。因为效率稍高。
for循环
-
语法格式
-
for (①初始化部分; ②循环条件部分; ④迭代部分){ ③循环体部分; }
-
-
执行过程
- ①-②-③-④-②-③-④-②-③-④-…-②
-
说明
- ②循环条件部分为boolean类型表达式,当值为false时,退出循环
- ①初始化部分可以声明多个变量,但必须是同一个类型,用逗号分隔
- ④可以有多个变量更新,用逗号分隔
while循环
-
语法格式
-
①初始化部分 while(②循环条件部分){ ③循环体部分; ④迭代部分; }
-
-
执行过程:
- ①-②-③-④-②-③-④-②-③-④-…-②
-
说明:
- 注意不要忘记声明④迭代部分。 否则,循环将不能结束,变成死循环。
- for循环和while循环可以相互转换
for循环与while循环的区别:
for循环和while循环的初始化条件部分的作用范围不同。for循环的初始化条件只作用于循环体,while循环的初始化条件是属于局部变量
do-while循环
-
语法格式
-
①初始化部分; do{ ③循环体部分 ④迭代部分 }while(②循环条件部分);
-
-
执行过程:
- ①-③-④-②-③-④-②-③-④-…②
-
说明:
- do-while循环至少执行一次循环体。
无限循环
最简单“无限” 循环格式:while(true) , for(;;),无限循环存在的原因是并不知道循环多少次,需要根据循环体内部某些条件,来控制循环的结束。
嵌套循环
- 将一个循环放在另一个循环体内,就形成了嵌套循环。其中, for ,while ,do…while均可以作为外层循环或内层循环。
- 实质上,嵌套循环就是把内层循环当成外层循环的循环体。当只有内层循环的循环条件为false时,才会完全跳出内层循环,才可结束外层的当次循环,开始下一次的循环。
- 设外层循环次数为m次,内层为n次,则内层循环体实际上需要执行m*n次。
- 技巧
- 外层循环控制行数,内层循环控制列数
例:
/*
*
**
***
****
*****
*/
for (int i = 0;i < 5 ;i ++ ) //控制行数
{
for (int j = 0;j <= i ;j++ ) //控制列数
{
System.out.print('*');
}
System.out.println();
}
/* i(行数) j(- 的个数) k(* 的个数) j = 5 - i k = i
* 1 4 1
* * 2 3 2
* * * 3 2 3
* * * * 4 1 4
* * * * * 5 0 5
* * * * 1 1 4
* * * 2 2 3
* * 3 3 2
* 4 4 1 j = i k = 5 - i
*/
//上半部分
for (int i = 1;i <= 5 ;i++ )
{
for (int j = 1 ;j <= 5 - i ;j++ )
{
System.out.print(" ");
}
for (int k = 1 ;k <= i ;k++ )
{
System.out.print('*');
System.out.print(" ");
}
System.out.println();
}
//下半部分
for (int i = 1;i <= 4 ;i++ )
{
for (int j = 1;j <= i ;j++ )
{
System.out.print(" ");
}
for (int k = 1;k <= 5 - i ;k++ )
{
System.out.print("* ");
}
System.out.println();
}
break、continue关键字的使用
break 语句
-
break语句用于终止某个语句块的执行
-
break语句出现在多层嵌套的语句块中时,可以通过标签指明要终止的是哪一层语句块
-
label:for(int i = 1;i <= 4;i++){ for(int j = 1;j <= 10;j++){ if(j % 4 == 0){ //break;//默认跳出包裹此关键字最近的一层循环。 //continue; //break label;//结束指定标识的一层循环结构 continue label;//结束指定标识的一层循环结构当次循环 } System.out.print(j); } System.out.println(); }
-
continue 语句
- continue只能使用在循环结构中
- continue语句用于跳过其所在循环语句块的一次执行,继续下一次循环
- continue语句出现在多层嵌套的循环语句体中时,可以通过标签指明要跳过的是哪一层循环
说明
- break只能用于switch语句和循环语句中。
- continue只能用于循环语句中。
- 二者功能类似,但continue是终止本次循环,break是终止本层循环
- break、continue之后不能有其他的语句,因为程序永远不会执行其后的语句。
- 标号语句必须紧接在循环的头部。标号语句不能用在非循环语句的前面
return的使用
- return:并非专门用于结束循环的,它的功能是结束一个方法。 当一个方法执行到一个return语句时,这个方法将被结束。
- 与break和continue不同的是,return直接结束整个方法,不管这个return处于多少层循环之内















 7035
7035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









