







一、mysql中sql_model中的ONLY_FULL_GROUP_BY问题处理
1、背景
在处理一个sql语句要求选择分组中最新的一条数据时,发现网上有一些mysql语句查询字段不在group by中,sql依然可以运行,在我本地运行后日志报错:
Caused by: org.b3log.latke.repository.RepositoryException: java.sql.SQLSyntaxErrorException: Expression #20 of
SELECT list is not in GROUP BY clause and contains nonaggregated column 'solo.aa.oId' which is not functionally
dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
sql_mode=ONLY_FULL_GROUP_BY问题出现在mysql5.7之后版本,默认的sql_mode为:
ONLY_FULL_GROUP_BY, STRICT_TRANS_TABLES, NO_ZERO_IN_DATE, NO_ZERO_DATE, ERROR_FOR_DIVISION_BY_ZERO, NO_AUTO_CREATE_USER, NO_ENGINE_SUBSTITUTION
2、sql_mode配置解析
- ONLY_FULL_GROUP_BY
这个设置要求查询的字段都要在group by子句(clause),否则这个sql是不合法的。这个配置会导致group by语句环境变的狭隘,所以一般不加这个配置 - NO_ZERO_IN_DATE
在严格模式下,不允许日期和月份为零 - ERROR_FOR_DIVISION_BY_ZERO
在insert或者update过程中,如过数据被零除,则会产生错误而非报错。如果未给出模式,那么数据被零出mysql会返回NULL - PIPES_AS_CONCAT
将‘||’视为字符串的连接符而非或运算符,这和oracle数据库是一样的,也和字符串的的拼接函数concat类似 - ANSI_QUOTES
启用ANSI_QUOTES后,不能使用双引号来引用字符串,因为它被解释为识别符。 - 其他参数请查看
3、sql命令查看sql_mode
- 临时修改sql_mode
一种是当前会话连接session级别,另一种是global级别的;重启mysql后,会回复默认设置
select @@session.sql_mode
select @@golbal.sql_mode
# 设置sql_mode,语法相同全局替换即可
set session sql_mode='ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
set @session.sql_mode='ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
- 永久修改
在mysql启动配置文件中配置默认设置
一般在/etc/my.cnf中的[mysqld]增加
sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
二、mysql分组排序后取第一个值
1. 新建测试数据表aaaa,录入部分数据
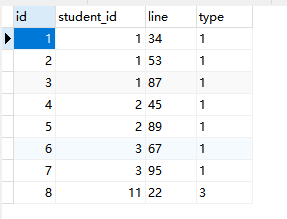
2. 测试sql语句分析
- 1 group by的过滤条件
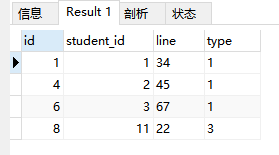
SELECT * FROM aaaa GROUP BY student_id;
结果(只会选一条语句):
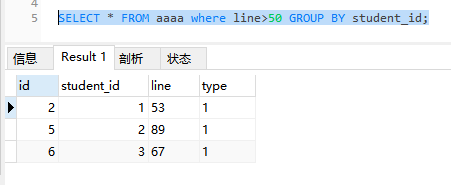
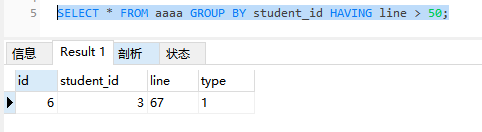
增加过滤条件>50,可以看到where子句在group by排序之前执行,having在分组后执行,其结果如下所示:
- 2 找出分组排序后最大的值
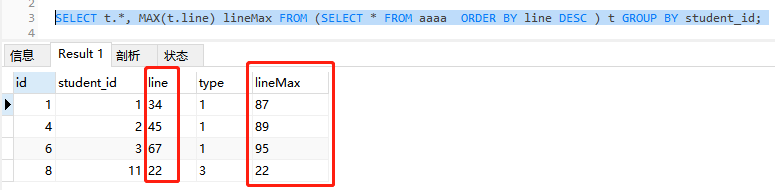
SELECT t.*, MAX(t.line) lineMax FROM (SELECT * FROM aaaa ORDER BY line DESC ) t GROUP BY student_id;
结果中返回line值与最大值不一致,也就是值取到了最大值,但是并没有将最大值那条记录查询出来。
修改括号中的子句增加limit
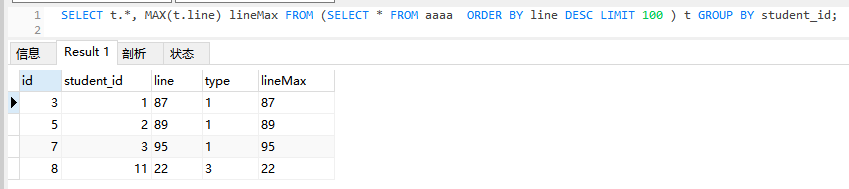
SELECT t.*, MAX(t.line) lineMax FROM (SELECT * FROM aaaa ORDER BY line DESC LIMIT 100 ) t GROUP BY student_id;
此次返回结果,通过查看id以及line值可以看到获取到了我们想要最大值记录。
注意:
limit 是必须要加的,如果不加的话,数据不会先进行排序,通过 explain 查看执行计划,可以看到没有 limit 的时候,少了一个 DERIVED 操作。
三、explain函数
在日常工作中,我们会有时会开慢查询去记录一些执行时间比较久的SQL语句,找出这些SQL语句并不意味着完事了,些时我们常常用到explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。所以我们深入了解MySQL的基于开销的优化器,还可以获得很多可能被优化器考虑到的访问策略的细节,以及当运行SQL语句时哪种策略预计会被优化器采用。
-- 对比一下以下语句的差异
EXPLAIN select * from aaaa ;
EXPLAIN select * from aaaa where id = '1';
EXPLAIN select * from aaaa where type = '1';



- type 对表访问方式,表示MySQL在表中找到所需行的方式,又称“访问类型”。
常用的类型有: ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
ALL 全表查询
const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system - possible_keys 指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用(该查询可以利用的索引,如果没有任何索引显示 null)
该列完全独立于EXPLAIN输出所示的表的次序。这意味着在possible_keys中的某些键实际上不能按生成的表次序使用。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查WHERE子句看是否它引用某些列或适合索引的列来提高你的查询性能。如果是这样,创造一个适当的索引并且再次用EXPLAIN检查查询 - Key key列显示MySQL实际决定使用的键(索引),必然包含在possible_keys中
如果没有选择索引,键是NULL。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX。
我们在这里通过EXPLAIN 查看一下上述sql语句,发现增加limit后多了一个记录。

















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









