






1、我们使用chrome浏览器搜索:北京,我们看到他的地址中"?"后面拼接了很多的参数。
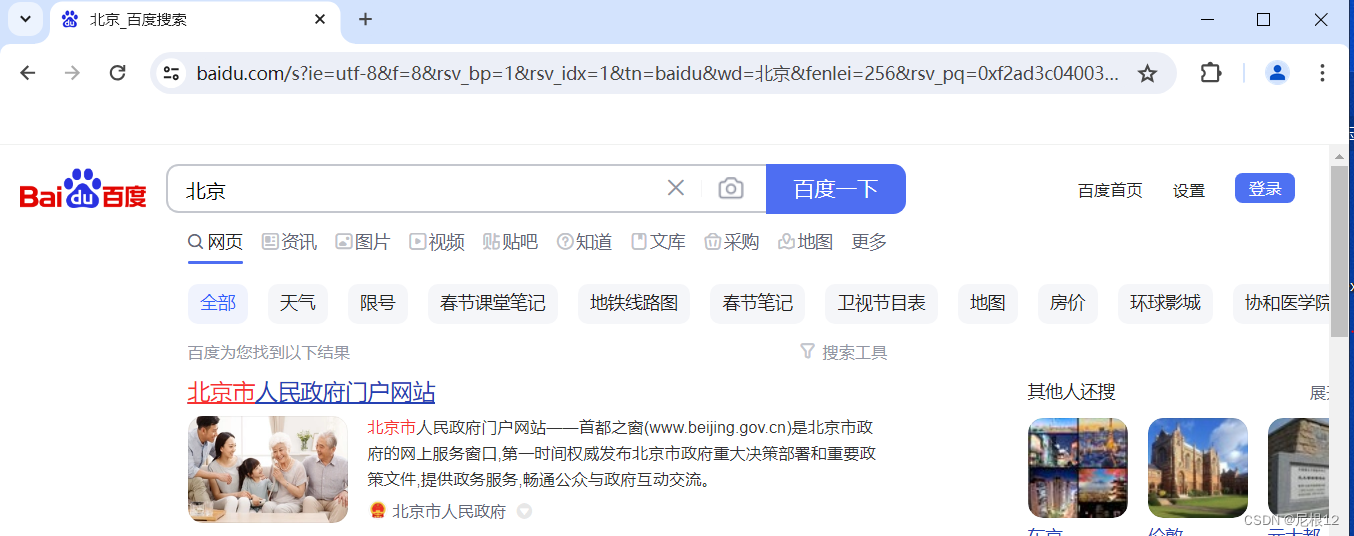
2、然后我们按F12,刷新页面,调到netwok页面,找到数据包,查看payload。在这里面我们看得到了很多参数,这些参数经过编码后就被拼接到上面的url的“?”后面。

3、这些参数我们往往用一个字典来存储,通过调用urllib.parse库中的urlendode来进行转换。
注意:如何使用转换后的参数,get请求和post请求有所不同。
get的参数直接拼接在url的后面,安全性较差,以?分割URL和传输的数据,参数之间用&相连接
post的参数时隐藏起来的,使用时要作为参数传入urllib.request.Request()中
4、接下来通过两个案例来举例:
爬取豆瓣(get):
# 爬取豆瓣前n页的信息,并以json形式保存
# 这里用到urllib库,直接在所用的python解释器的scripts的目录中,通过终端命令pip install urllib来下载该库
import urllib.request
import urllib.parse
def create_request(page): # 生成请求头的函数
base_url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&"
data = {
"start": (page-1)*20,
"limit": 20
}
new_data = urllib.parse.urlencode(data) # 注意get请求不需要encode,只需要拼接就行
url = base_url + new_data # 把经过编码的数据直接拼接url的后面即可
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'}
request = urllib.request.Request(url=url, headers=headers) # 定制请求头,传入url和headers两个参数
return request
def get_content(request):
response = urllib.request.urlopen(request) # 获取网页源码
content = response.read().decode("utf-8") # 对源码进行读取获得数据
return content
def down_load(page,content):
with open('douban_'+str(page)+'.json',"w",encoding="utf-8") as fp: # 注意和字符串拼接必须都是字符串,
fp.write(content) # 打开json文件,分别写入每页的数据。
if __name__== "__main__":
start_page = int(input("请输入起始页码:")) # 输入爬取起始页码
end_page = int(input("请输入结束页码:")) # 输入爬取的结束页码
for page in range(start_page,end_page+1): # 对每一页进行循环
request = create_request(page) # 调用生成请求头的函数
content = get_content(request) # 调用获取数据的函数
down_load(page,content) # 调用下载数据的函数爬取肯德基(post):
# 爬取肯德基门店n页的信息,并以json形式保存
# 这里用到urllib库,直接在所用的python解释器的scripts的目录中,通过终端命令pip install urllib来下载该库
import urllib.request
import urllib.parse
def create_request(page):
base_url = "https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname"
data={
"cname":"北京",
"pid":"",
"pageIndex":page,
"pageSize":10
}
data = urllib.parse.urlencode(data).encode("utf-8")
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
}
# 注意两种方法的区别,post方法不能把data编码后拼接到url后面,而是将其作为一个参数传入请求头。
request = urllib.request.Request(url=base_url,headers=headers,data=data) # 定制请求头
return request
def get_content(request):
response = urllib.request.urlopen(request) # 获取网页源码
content = response.read().decode("utf-8") # 读取源码获得数据
return content
def down_load(page,content):
with open("KFC"+str(page)+".json","w",encoding="utf-8") as fp:
fp.write(content) # 下载json数据
if __name__=="__main__":
start_page = int(input("请输入起始页码")) # 输入爬取起始页码
end_page = int(input("请输入结束页码")) # 输入爬取的结束页码
for page in range(start_page,end_page+1): # 对每一页进行循环
request = create_request(page) # 调用生成请求头的函数
content = get_content(request) # 调用获取数据的函数
down_load(page, content) # 调用下载数据的函数
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









