






一、事务
1、事务:也称工作单元,是由一个或者多个sql语句所组成的操作序列,这些sql语句作为一个完整的工作单元,要么全部执行成功,要么全部执行失败。通过事务来保持数据的一致性。适合处理数据量大,复杂的操作。通过事务能防止数据库中出现数据不一致的现象。比如两个银行账户涉及到转账,涉及到两条更新操作,这两条更新操作只允许全部成功或失败,否则数据会出现不一致的现象。
2、事务处理语言:(Transaction Process Language)TPL语言 主要用来对组成事务的DML语句的操作结果进行确认或取消。
确认:就是使DMl操作生效,使用提交COMMIT命令实现;
取消:也就是使DML操作失效,使用回滚ROLLBACK命令实现。
3、MYSQL是支持事务的,跟使用的引擎有关。mysql支持多种引擎,默认使用innodb引擎支持事务。
MySAM 不支持事务,用于只读程序提高性能
innoDB 支持ACID事务、支持行级锁
Berkeley DB 支持事务
4、事务的特性:ACID
原子性、一致性、隔离性(一个事务执行不会被另一个事务干扰)、持久性(事务一旦提交,对数据的改变是永久的)
5、事务处理-手动提交事务
用begin、rollback、commit来实现。用begin开启事务后在没有commit提交之前执行修改命令,变更会维护到本地缓存中,而不维护到务理表中,只有在commit提交后才会更新到务理表中。如果中间执行错误,那么rollback回滚事务,恢复到执行事务之前的状态。
6、事务处理自动提交模式
mysql默认是自动提交的,也就是你提交一个sql,就直接执行。可以通过set autocommit = 0禁止自动提交。set autocommit=1开启自动提交,来实现事务的处理。
但要注意当用 set autocommit = 0的时候,以后所有的sql都将作为事务处理,直到用commit确认或rollback结束,注意当结束这个事务的同时也开启了新的事务。按第一种方法只将当前的做为一个事务。
7、事务处理-隐式处理
隐式提交:当下面任意一种情况发生的时候就会发生隐式提交
执行一个DDL(create,alter,drop,truncate,rename);
执行一个DCL(GRANT、REVOKE)语句;
8、隐式回滚:下面任意种发生
客户端强行退出
客户端连接到服务器端异常中断
系统崩溃
use studb
show tables;
select * from students;
begin;
delete from students where id=4;
commit;举例来理解事务,此时还没commit提交我们重新打开一个终端,看看students表有无变化。
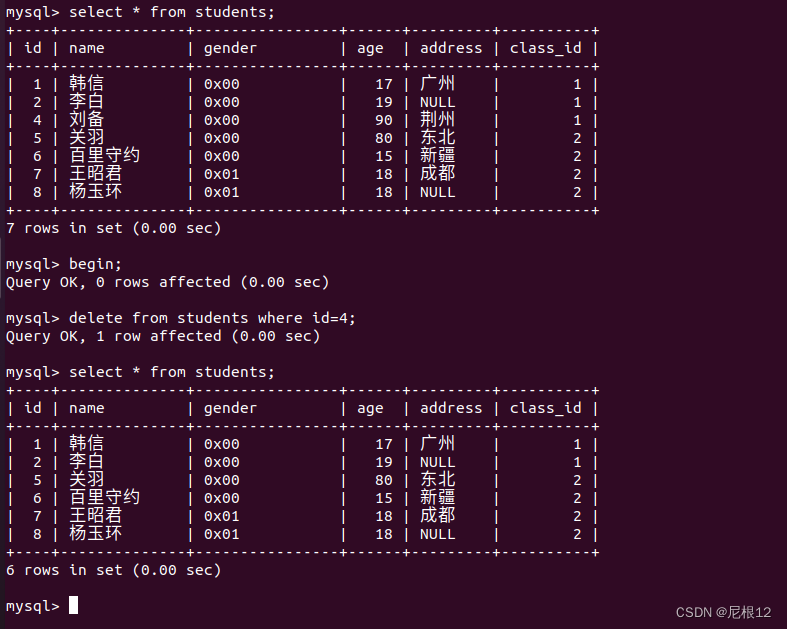
在我们新开的终端中,表的数据并没有改变因为此时没有commit提交,事务还没有结束。

我们commit提交结束事务,然后再次查看。此时students中的数据才发生改变
![]()

二、视图
1、视图:就是对查询语句的封装。就是查询,是一个虚拟的表。常用于频繁使用的查询语句,或者出于保密性考虑,过滤敏感数据。
2、创建视图:create view 视图名称 as select语句;
create view test_view as
select s.id,s.name,c.name as class_name,age from
students as s inner join class as c on s.class_id=c.id;3、查看视图,查看所有表会将视图也列出来
show tables;
show table status;
4、调用视图
select * from test_view; 
5、删除视图:drop view 视图名称;
drop view test_ciew;三、索引
先创建一个表
create table myindex(
id int not null auto_increment,
test varchar(10),
PRIMARY KEY(id)
)ENGINE=INNODB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;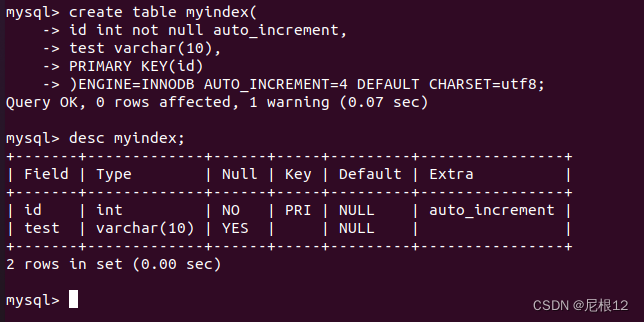
1、建立索引一种有效的优化查询的方案,索引类似于目录,也是占据磁盘空间的,选择越小的数据类型越好。mysql常见的索引有主键索引、唯一索引、普通索引、全文索引、组合索引。
2、创建索引以及mysql不同索引区别
# 主键索引:唯一性、特殊的、不能有空值
alter table 表名 add primary key 列名;
# 唯一索引:唯一约束、与普通索引类似、可以有空值
alter table 表名 add unique 列名;
# 普通索引:基本的,无限制
alter table 表名 add index 索引名称 列名;
#全文索引:仅可用于引擎myisam,针对较大的数据。,varchar,text,生成全文索引耗时
alter table add fulltext 列名;
# 组合索引:为了更好的mysql效率,遵循最左前缀原则。
alter table 表名 add index 索引名(列1,列2,列3);
alter table myindex add index index_my_test(test);
3、查看索引
show index from 表名;
show index from myindex;

4、删除索引
drop index 索引名 on 表名;
四、存储过程
1、存储过程,也翻译为存储程序,是一条或者多条sql语句的集合,可以视为批处理,但是其作用不仅仅局限于批处理。
创建存储过程、调用、查看、修改、删除存储过程。存储过程也可以调用其他存储过程。
2、语法 delimiter用于设置sql语句分隔符,默认为分号。这里指定了//作为分割符。
语法:
delimiter//
create procedure 存储过程名称(参数列表)
begin
sql语句
end
//
delimiter;
举例:
delimiter //
create procedure test_pro ()
begin
select * from students where gender='1';
end
//
delimiter;
3、查看创建的存储过程
所有存储过程和函数都存储在mysql数据库下的proc表中
proc表中字段说明
(1)name 表示名称
(2)type 表示类型、为存储过程、函数
(3)body 表示正文脚本
(4)db 表示属于的数据库
查询刚才创建的存储过程
select name,type,body from mysql.proc where db='studb';
4、调用存储过程,语法:call 存储过程 (参数列表)
call test_pro()
5、删除存储过程,语法:drop procedure 存储过程名称;
drop procedure test_pro;
6、存储过程中的变量
要在存储过程中声明一个变量,可以使用declare语句。
语法:declare 变量名 数据类型大小 默认值(初始值为空)
declare variable_name datatype default default_value;
举例:声明一个名为total_count的变量,数据类型为int,默认值0
#设置变量值
declare total_count int default 0;
# set
set total_count = 10;
# select into将查询结果分配给一个变量
select count(*) into total_count from students;
#示例
delimiter //
drop procedure if exists test_pro //
create procedure test_pro ()
begin
declare total_count int default 0;
select count(*) into total_count from students;
print(total_count)
end
//
delimiter;
# 条件语句
if expression then
statements;
end if;
如果表达式expression计算结果为true,那么就执行statements语句,否则控制流将传递到end if之后的下个语句。
if...else...else
如果要基于多个表达式有条件的执行语句,则使用if elseif else 语句执行
if expression then
statements
elseif elseif-expression then
elseif-statements;
else
else-statements;
end if;
# while循环
while expression do
statements
end while
# concat()拼接字符串
# convert()数据类型转换
# 创建插入数据的存储过程
delimiter $$
drop procedure if exists auto_insertdata_proc $$
create procedure auto_insertdata_proc()
begin
declare num int;
set num=1;
set autocommit = 0;
start transaction;
while num<=500000 do
insert into myindex values(0,concat('TEST',convert(num,char)));
set num = num+1;
end while;
commit;
end
$$
delimiter;
delimiter //
drop procedure if exists auto_insertdata_proc //
create procedure auto_insertdata_proc()
begin
declare num int;
set num=1;
set autocommit = 0;
start transaction;
while num<=500000 do
insert into myindex values(0,concat('TEST',convert(num,char)));
set num = num+1;
end while;
commit;
end
//
delimiter;
# 查看有无刚才的过程
show procedure status
# 调用这个存储过程
call auto_insertdata_proc();
#显示表的索引show INDEX FROM myindex;
#profiling参数,mysql的query profiler是一个非常方便的query诊断分析工具
set profiling=1;
# 没有给test字段创建索引的时候,查找第400000条数据
select * from myindex where test='test400000';
# 查看执行时间
show profiles;
# 0.1s 500119 0.1005275 select * from myindex where test='test400000'
#建立索引
alter table myindex add index index_my_test(test);
show index from myindex;
#再次查询
set profiling=1;
select * from myindex where test='test400000';
show profiles;
#0.0006s 500137 0.0006585 select * from myindex where test='test400000'五、函数
# 内置函数
# 查看字符的asciii码值
select ascii(str)
select ascii('a');
# 数字转换字符
select char(数字)
select char (67);
# concat(str1,str2)字符串拼接
select concat(12,34,'ab');
# 包含字符个数length(str)
select length('abc');
# 截取字符串
left(str,len)返回字符串str的左端的len个字符
right(str,len)
substring(str,pos,len) 返回字符串str的位置pos起len个字符
select substring('abc123',2,3);
# 去除空格
ltrim(str) 返回删除了左空格的字符串str
rtrim(str) 返回删除了右空格字符串str
trim([方向,remstr from str]) 返回从某侧删除remstr后的字符串str
both两侧,leading左侧,trailing右侧
select trim('bar ');
select trim(leading 'x' from 'xxxbarxxx');
select trim(both 'x' from 'xxxbarxxx');
select trim(trailing 'x' from 'xxxbarxxx');
# 返回由你个空格字符组成的一个字符串
select space(10);
# 替换字符串函数 replace(str,fromstr,tostr);
select replace('abc123','123','def');把字符串abc123中的123替换为def
# 大小写替换
lower(str);
upper(str);
select upper('hhh');
# 自定义函数
# 创建自定义函数
# 语法
delimiter //
create function 函数名称(参数列表) return 返回类型
begin
sql语句
end
//
delimiter;
#实例
delimiter //
create function py_trim(str varchar(100)) returns varchar(100)
begin
declare x varchar(100);
set x=ltrim(rtrim(str));
return x;
end;
//
delimiter;
在创建函数的同时为函数指定一个参数,明确指出函数的类型。因为数据库启用bin-log后,在进行主从复制必须要知道这个函数的类型才能同步数据,因此在声明函数时我们必须指定我们的函数的类型,MySQL支持的参数类型有以下五种:
1. DETERMINISTIC 不确定的
2. NO SQL 没有SQl语句,当然也不会修改数据
3. READS SQL DATA 只是读取数据,当然也不会修改数据
4. MODIFIES SQL DATA 要修改数据
5. CONTAINS SQL 包含了SQL语句
#创函数
create FUNCTION hello_fun() returns VARCHAR(20)
DETERMINISTIC
BEGIN
RETURN 'hello sqlk';
end;
#查询
show FUNCTION STATUS;
#调用
select hello_fun()
# 函数带参数
delimiter $$
drop function if exists hello_say$$
create function hello_say(uname varchar(10)) returns varchar(20)
DETERMINISTIC
begin
return CONCAT('hello--',uname);
end
$$
delimiter ;
#调用
SELECT hello_say('杜甫')
select hello_say(name) from students;
#函数使用变量
delimiter $$
drop function if exists total_record$$
create function total_record() returns varchar(20)
DETERMINISTIC
begin
declare total_count int default 0;
select count(1) from students into total_count;
return CONCAT('学生表中的数据记录是',total_count);
end
$$
delimiter ;
#查询
show FUNCTION STATUS;
#调用
select total_record()
# 不用提前声明使用临时变量 @变量
delimiter $$
drop function if exists total_drecord$$
create function total_drecord() returns varchar(200)
DETERMINISTIC
begin
select count(1) from students into @total_count_student;
select count(1) from students into @total_count_course;
return CONCAT('学生表中的数据记录是',@total_count_student,'课程表中的数据记录是',@total_count_course);
end
$$
delimiter;
#查询
show FUNCTION STATUS;
#调用
select total_drecord()
# 使用if语句等各种
delimiter $$
drop function if exists fun_if$$
create function fun_if(age int) returns varchar(200)
DETERMINISTIC
begin
if age<=20 then set @msg='很好你还不到20';
else set @msg='你已经20拉';
end if;
return @msg;
end
$$
delimiter ;
#查询
show FUNCTION STATUS;
#调用
select fun_if(19)
#存储过程和存储函数的区别
#1、函数的限制多,不能使用临时表,只能使用表变量。然而存储过程限制少一些
#2、存储过程实现的功能逻辑相对来说要复杂一些,而函数的实现功能针对性强一些。
#3、函数必须有返回值,且只有一个结果集。然而存储过程可以没有返回值,可以返回一个集合,表,几个表,逻辑数据等
#4、调用语法不同,函数经常会嵌入到sql中使用,通过select 函数名()。存储过程通过call语句去调用。














 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









