







原文链接:http://blog.csdn.net/ashic/article/details/47073885
分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群。机架内的机器之间的网络速度通常都会高于跨机架机器之间的网络速度,并且机架之间机器的网络通信通常受到上层交换机间网络带宽的限制。
具体到Hadoop集群,由于hadoop的HDFS对数据文件的分布式存放是按照分块block存储,每个block会有多个副本(默认为3),并且为了数据的安全和高效,所以hadoop默认对3个副本的存放策略为:
第一个block副本放在和client所在的node里(如果client不在集群范围内,则这第一个node是随机选取的)。
第二个副本放置在与第一个节点不同的机架中的node中(随机选择)。
第三个副本似乎放置在与第一个副本所在节点同一机架的另一个节点上
如果还有更多的副本就随机放在集群的node里。这样的策略可以保证对该block所属文件的访问能够优先在本rack下找到,如果整个rack发生了异常,也可以在另外的rack上找到该block的副本。这样足够的高效,并且同时做到了数据的容错。
但是,hadoop对机架的感知并非是自适应的,亦即,hadoop集群分辨某台slave机器是属于哪个rack并非是只能的感知的,而是需要hadoop的管理者人为的告知hadoop哪台机器属于哪个rack,这样在hadoop的namenode启动初始化时,会将这些机器与rack的对应信息保存在内存中,用来作为对接下来所有的HDFS的写块操作分配datanode列表时(比如3个block对应三台datanode)的选择datanode策略,做到hadoop allocate block的策略:尽量将三个副本分布到不同的rack。
接下来的问题就是:通过什么方式能够告知hadoop namenode哪些slaves机器属于哪个rack?以下是配置步骤。
简单来说,就是当我们的集群中包含很多的datanode时,他们必然不会放在同一个机柜中,甚至不再一个机房
那么与namenode相距越近,网络速度必然越好,越有利于存取block。但是hadoop自己不知道谁离得谁离得远,只能我们认为去配置
步骤:
1.点击主机,选择你要分配机架的主机。默认所有主机得机架都是/default
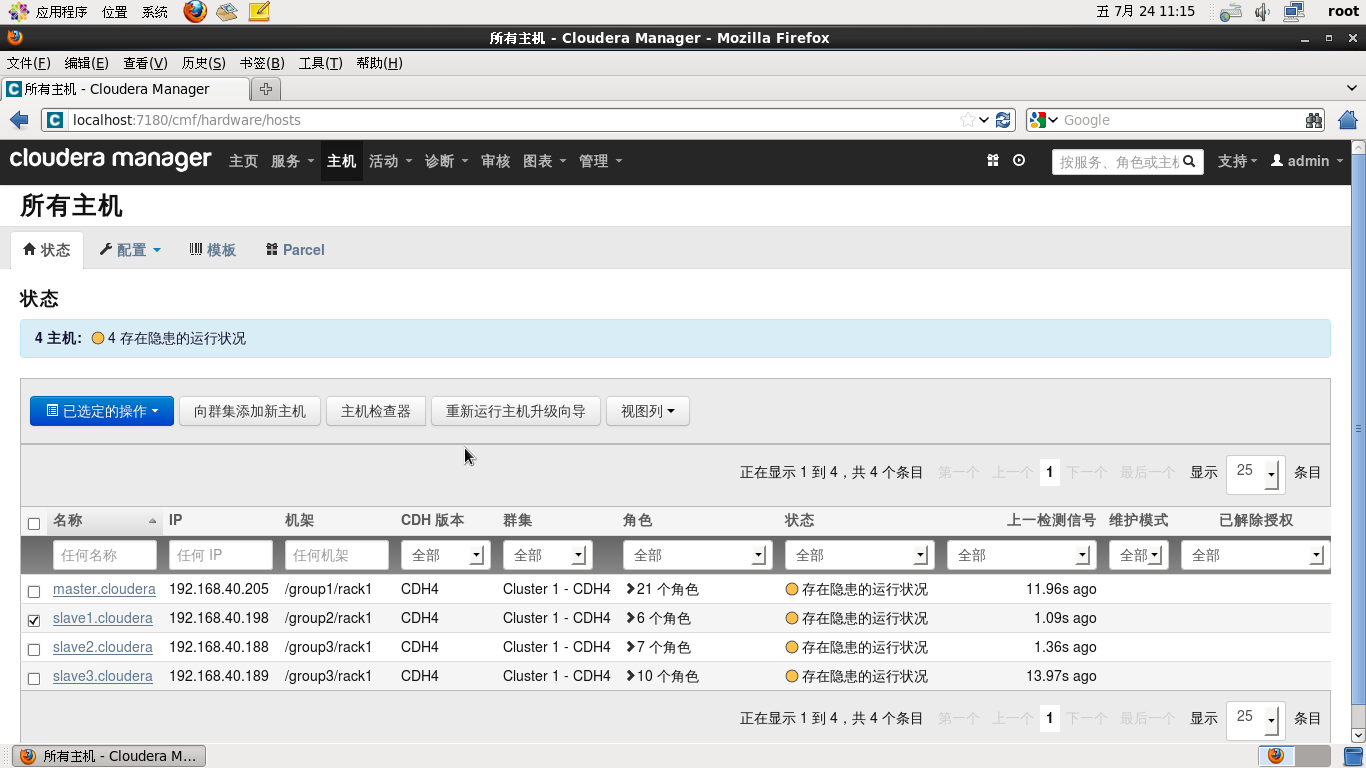
2.点击已选定得操作-分配机架
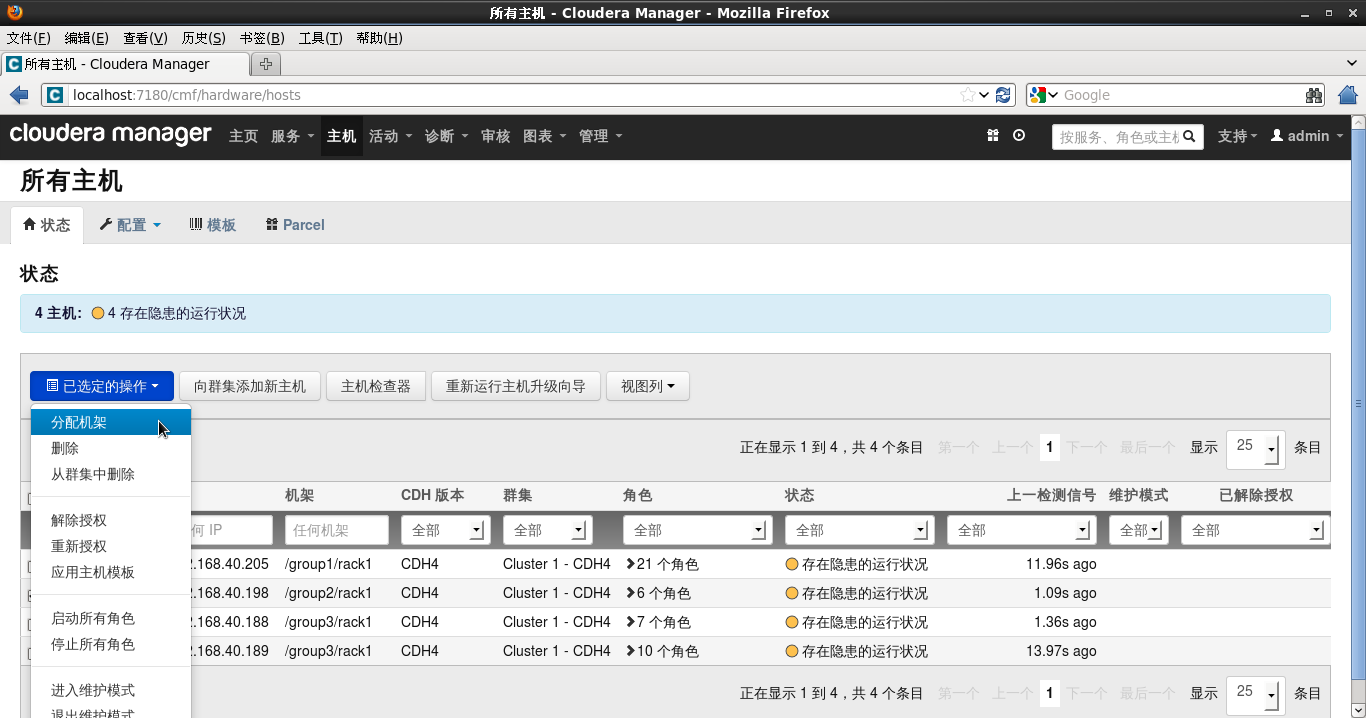
3.填写机架
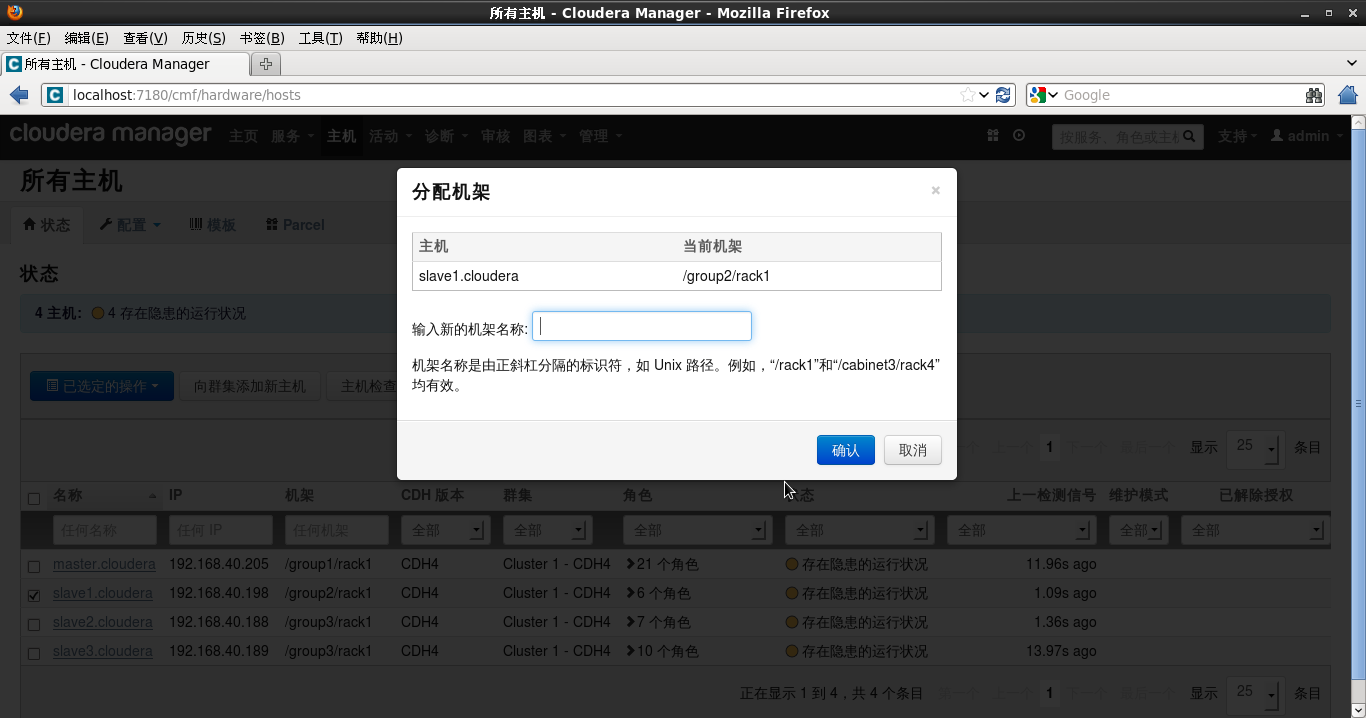
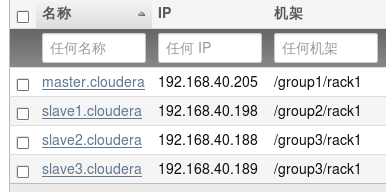
4.更改结束















 1383
1383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









