







python2.7在使用urllib2爬取"https://www.block123.com/"页面时报这个编码错误,解决办法是在原来的decode('utf-8')中再增加一个ignore参数,代码如下:
原代码:html = response.read().decode('utf-8')
修改后:html = response.read().decode('utf-8','ignore').replace(u'\xa9', u'')
replace()方法是python中用于将旧字符串替换成新字符串的方法。其参数一般有两个,如replace("a","b"),意思是将原字符串中的“a”全部替换为“b”。另一种情况是有三个参数,如replace("a","b",3),这个3的意思是最多替换3次。
如果有多个需要替换的,就接着在replace()后加replace(),例如:
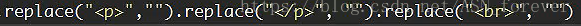
报这个错的原因是gbk无法对u'\xa9'代表的字符进行编码,在Unicode中u'\xa9'代表的是©。因此直接忽略掉。
参考:https://blog.csdn.net/github_35160620/article/details/53512967














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









