






支持向量机SVM:原理与实现
一.逻辑回归遗留的问题
在二分类问题中,下图的红绿蓝三条线都有可能是逻辑回归的决策边界,但是站在我们的角度上来看,红蓝色或许并不是很好的决策边界,因为它们极有可能受到噪音影响,泛化能力很差。至少我们会认为绿色的决策边界更好。
在上图中,数据点是二维的,决策边界是一维的。对于支持向量机来说,数据点若是P维向量,我们则用P-1维的超平面来作为决策边界分开这些点。而最优决策边界恰恰是离超平面最近的点到超平面的距离最远的超平面。
二.支持向量机的起步
1.支持向量机能解决的问题
- 线性可分SVM
当训练数据线性可分时,通过硬间隔(hard margin),最大化可以学习得到一个线性分类器,即硬间隔SVM。
- 线性SVM
当训练数据不能线性可分但是可以近似线性可分时,通过软间隔(soft margin)最大化也可以学习到一个线性分类器,即软间隔SVM。
- 非线性SVM
当训练数据线性不可分时,通过使用核技巧(kernel trick)和软间隔最大化,可以学习到一个非线性SVM。
2.数据集的线性可分性
给定一个数据集
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
⋯
,
(
x
N
,
y
N
)
}
T=\{(\boldsymbol{x}_1,y_1),(\boldsymbol{x}_2,y_2),\cdots,(\boldsymbol{x}_N,y_N)\}
T={(x1,y1),(x2,y2),⋯,(xN,yN)}
其中,
x
i
∈
X
=
R
n
,
y
i
∈
Y
=
{
+
1
,
−
1
}
,
i
=
1
,
2
,
⋯
,
N
\boldsymbol{x}_{i} \in \mathcal{X}=\mathbf{R}^{n}, \quad y_{i} \in \mathcal{Y}=\{+1,-1\}, \quad i=1,2, \cdots, N
xi∈X=Rn,yi∈Y={+1,−1},i=1,2,⋯,N
如果存在某个超平面
S
S
S:
w
T
x
+
b
=
0
\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+b=0
wTx+b=0
能够将数据集的正样本(+1)和负样本(-1)完全正确地划分到超平面的两侧,即:
- 对所有 y i = + 1 y_i=+1 yi=+1的样本 i i i,有 w T x + b > 0 \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+b>0 wTx+b>0
- 对所有 y i = − 1 y_i=-1 yi=−1的样本 i i i,有 w T x + b < 0 \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+b<0 wTx+b<0
则称数据集 T T T为线性可分数据集(linearly separable data set);否则,称数据集 T T T线性不可分。
3.函数间隔和几何间隔
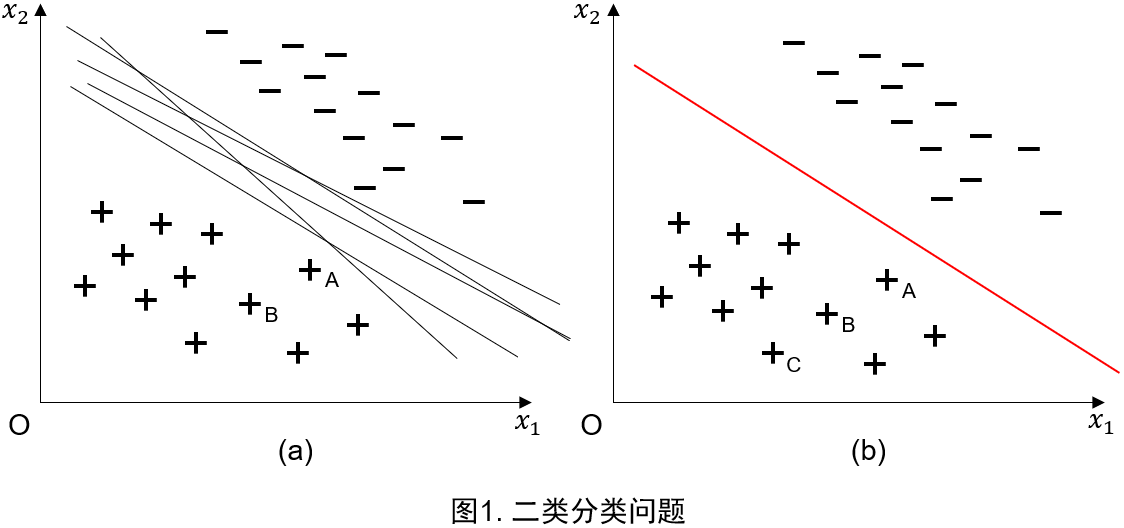
给定线性可分训练数据集,存在无穷个超平面可将两类样本正确分离开,如图1(a)所示;
若利用间隔最大化求最优分离超平面,此时的解是唯一的,如图1(b)所示。
3.1函数间隔
图1(b)中包括正类的 A , B , C A,B,C A,B,C三个样本。
- C C C点和超平面的距离较远,若预测该点为正类,则确信度较高
- A A A点和超平面的距离较近,若预测该点为正类,则确信度相对较低
- B B B点介于 A A A点和 C C C点之间,相应地,确信度也在 A A A和 C C C之间
∣ w T x + b ∣ ∥ w ∥ \Large{\frac{{\left| {{w^T}x + b} \right|}}{{\left\| w \right\|}}} ∥w∥∣∣wTx+b∣∣能够表示点 x x x距离超平面的远近,而 w T x + b \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+b wTx+b的符号与类标记 y y y的符号是否一致可表示分类是否正确。
因此,舍去 ∥ w ∥ \left\| {\bf{w}} \right\| ∥w∥节省运算成本的同时,可用 y ( w T x + b ) y(\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+b) y(wTx+b)来表示分类的正确性及确信度,这就是函数间隔(functional margin)的概念
-
对于给定的训练数据集 T T T和超平面 ( w , b ) (\boldsymbol{w},b) (w,b),定义超平面 ( w , b ) (\boldsymbol{w},b) (w,b)关于样本点 ( x i , y i ) (\boldsymbol{x}_i,y_i) (xi,yi)的函数间隔为
γ ^ i = y i ( w T x i + b ) \hat{\gamma}_{i}=y_{i}\left(\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_{i}+b\right) γ^i=yi(wTxi+b) -
定义超平面 ( w , b ) (\boldsymbol{w},b) (w,b)关于训练数据集 T T T的函数间隔为超平面 ( w , b ) (\boldsymbol{w},b) (w,b)关于 T T T中所有样本点 ( x i , y i ) (\boldsymbol{x}_i,y_i) (xi,yi)的函数间隔的最小值,即
γ ^ = min i = 1 , ⋯ , N γ ^ i \hat{\gamma}=\min _{i=1, \cdots, N} \hat{\gamma}_{i} γ^=i=1,⋯,Nminγ^i
3.2几何间隔
函数间隔可以表示分类预测的正确性和确信度。但在选择分离超平面时,仅用函数间隔还不够。
因为只要成比例的改变 w \boldsymbol{w} w和 b b b,例如 2 w 2\boldsymbol{w} 2w和 2 b 2b 2b,超平面并没有改变,但函数间隔却成为原来的2倍。
我们可以对分离超平面的法向量 w \boldsymbol{w} w加某些约束,如规范化, ∥ w ∥ = 1 \|\boldsymbol{w}\|=1 ∥w∥=1,使间隔是确定的。
此时,函数间隔便成为几何间隔(geometric margin),如图2所示。
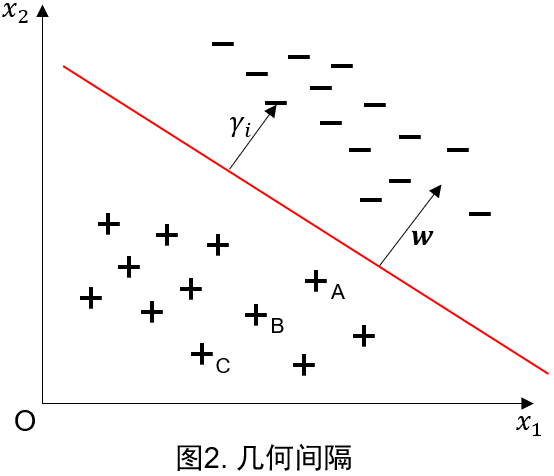
令 ∥ w ∥ \|\boldsymbol{w}\| ∥w∥表示 w \boldsymbol{w} w的 L 2 L_2 L2范数,对于给定的训练数据集 T T T和超平面 ( w , b ) (\boldsymbol{w},b) (w,b),定义超平面 ( w , b ) (\boldsymbol{w},b) (w,b)关于样本点 ( x i , y i ) (\boldsymbol{x}_i,y_i) (xi,yi)的几何间隔为
γ
i
=
y
i
(
w
∥
w
∥
⋅
x
i
+
b
∥
w
∥
)
=
y
i
∣
w
T
x
i
+
b
∣
∥
w
∥
\gamma_{i}=y_{i}\left(\frac{\boldsymbol{w}}{\|\boldsymbol{w}\|} \cdot x_{i}+\frac{b}{\|\boldsymbol{w}\|}\right)={y_i}\frac{{\left| {{{\bf{w}}^{\rm{T}}}{{\bf{x}}_i} + b} \right|}}{{\left\| {\rm{w}} \right\|}}
γi=yi(∥w∥w⋅xi+∥w∥b)=yi∥w∥∣∣wTxi+b∣∣
定义超平面
(
w
,
b
)
(\boldsymbol{w},b)
(w,b)关于训练数据集
T
T
T的几何间隔为超平面
(
w
,
b
)
(\boldsymbol{w},b)
(w,b)关于
T
T
T中所有样本点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)的几何间隔的最小值,即
γ
=
min
i
=
1
,
⋯
,
N
γ
i
\gamma=\min _{i=1, \cdots, N} \gamma_{i}
γ=i=1,⋯,Nminγi
超平面
(
w
,
b
)
(\boldsymbol{w},b)
(w,b)关于样本点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)的几何间隔表示样本点到超平面的带符号的距离(signed distance)。
当样本点被正确分类时,几何间隔成为实例点到超平面的距离。
由函数间隔和几何间隔的定义可推出如下关系
γ
i
=
γ
^
i
∥
w
∥
和
γ
=
γ
^
∥
w
∥
\gamma_{i}=\frac{\hat{\gamma}_{i}}{\|\boldsymbol{w}\|}和\gamma=\frac{\hat{\gamma}}{\|\boldsymbol{w}\|}
γi=∥w∥γ^i和γ=∥w∥γ^
若
∥
w
∥
=
1
\|\boldsymbol{w}\|=1
∥w∥=1,那么函数间隔和几何间隔相等。
此时,成比例的改变超平面参数 w \boldsymbol{w} w和 b b b(超平面不变),函数间隔将按此比例改变,而几何间隔不变。
4.支持向量
在样本空间中,分离超平面可由法向量 w \boldsymbol{w} w和位移 b b b表述 w T x + b = 0 \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+b=0 wTx+b=0
由几何间隔可得样本空间中任意点
x
\boldsymbol{x}
x到超平面
(
w
,
b
)
(\boldsymbol{w},b)
(w,b)距离的绝对值为
r
=
∣
w
T
x
+
b
∣
∥
w
∥
r=\frac{\left|\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b\right|}{\|\boldsymbol{w}\|}
r=∥w∥∣∣wTx+b∣∣
若超平面
(
w
,
b
)
(\boldsymbol{w},b)
(w,b)能将所有训练样本正确分类,即
{
w
T
x
i
+
b
⩾
+
1
,
y
i
=
+
1
w
T
x
i
+
b
⩽
−
1
,
y
i
=
−
1
\left\{\begin{array}{ll} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b \geqslant+1, & y_{i}=+1 \\ \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b \leqslant-1, & y_{i}=-1 \end{array}\right.
{wTxi+b⩾+1,wTxi+b⩽−1,yi=+1yi=−1
距离超平面最近的几个点使上式**等号**成立,将之称为支持向量(support vector),如图3。
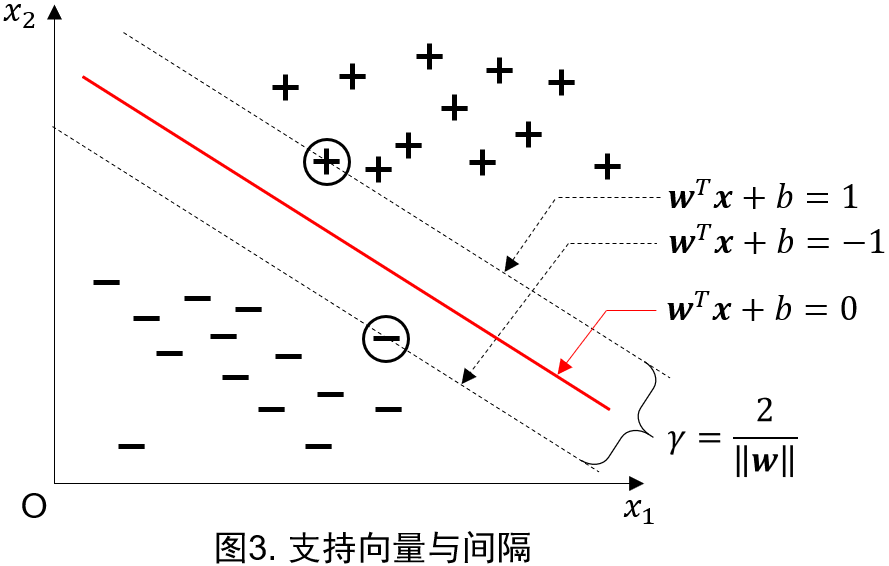
在决定最佳超平面时只有支持向量起作用,而其他数据点并不起作用。如果移动非支持向量,甚至删除非支持向量都不会对最优超平面产生任何影响。也即支持向量对模型起着决定性的作用,这也是“支持向量机”名称的由来。
5.间隔最大化
两个异类支持向量到超平面的距离之和为
γ
=
2
∥
w
∥
\gamma = \frac{2}{\|\boldsymbol{w}\|}
γ=∥w∥2
它被称为间隔(margin)。
我们希望找到一个具有最大间隔(maximum margin)的分离超平面,即
max
w
,
b
2
∥
w
∥
s.t.
y
i
(
w
T
x
i
+
b
)
⩾
1
,
i
=
1
,
2
,
…
,
N
\large{\begin{array}{l} \max\limits _{\boldsymbol{w}, b} \frac{2}{\|\boldsymbol{w}\|} \\ \text { s.t. } y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1, \quad i=1,2, \ldots, N \end{array}}
w,bmax∥w∥2 s.t. yi(wTxi+b)⩾1,i=1,2,…,N
由上式可知最大化间隔相当于最大化
∥
w
∥
−
1
\|\boldsymbol{w}\|^{-1}
∥w∥−1,等价于最小化
∥
w
∥
2
\|\boldsymbol{w}\|^{2}
∥w∥2,即
min
w
,
b
1
2
∥
w
∥
2
s.t.
y
i
(
w
T
x
i
+
b
)
⩾
1
,
i
=
1
,
2
,
…
,
N
\large{\begin{array}{l} \min\limits_{\boldsymbol{w}, b} \frac{1}{2}\|\boldsymbol{w}\|^{2} \\ \text { s.t. } y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1, \quad i=1,2, \ldots, N \end{array}}
w,bmin21∥w∥2 s.t. yi(wTxi+b)⩾1,i=1,2,…,N
这就是支持向量机(Support Vector Machine, SVM)的基本型。
这里的 1 2 ∥ w ∥ 2 \frac{1}{2}\|\boldsymbol{w}\|^{2} 21∥w∥2是为了方便求导后运算,求导后2和 1 2 \frac{1}{2} 21相抵消。
三.对偶问题&拉格朗日数乘法
1.硬间隔和软间隔
如果所有样本满足约束 y i ( w T x i + b ) ≥ 1 y_i(\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b)\geq 1 yi(wTxi+b)≥1,即所有样本必须划分正确,称为硬间隔(hard margin)。s
然而,这样便可能导致如图1所示的过拟合现象:
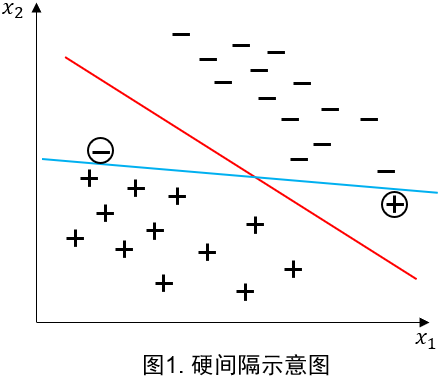
我们希望得到的分离超平面应更接近于图1的红线,但由于圆圈标记的两个样本的存在,硬间隔将产生如图1蓝线所示的分离超平面。
为了缓解如上过拟合现象,引出了软间隔(soft margin)的概念。
软间隔允许某些样本不满足约束 y i ( w T x i + b ) ≥ 1 y_i(\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b)\geq 1 yi(wTxi+b)≥1,如图2所示。
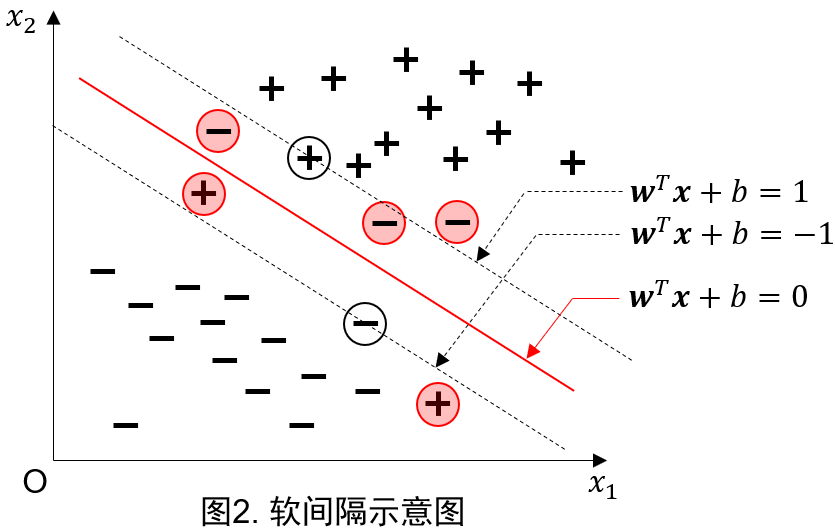
其中红色圈表示不满足约束条件的样本。
2.硬间隔SVM对偶问题
SVM基本型本身是一个凸二次规划(convex quadratic programming)问题。
对SVM基本型使用拉格朗日乘子法可得到其对偶问题(dual problem)。
具体地说,对SVM基本型的每项约束添加拉格朗日乘子
α
i
≥
0
\alpha_i \geq 0
αi≥0,该问题的拉格朗日函数可写为
L
(
w
,
b
,
α
)
=
1
2
∥
w
∥
2
−
∑
i
=
1
N
α
i
[
y
i
(
w
T
x
i
+
b
)
−
1
]
=
1
2
∥
w
∥
2
+
∑
i
=
1
N
−
α
i
y
i
(
w
T
x
i
+
b
)
+
∑
i
=
1
N
α
i
\large\begin{array}{l} L({\bf{w}},b,{\bf{\alpha }}) = \frac{1}{2}{\left\| {\bf{w}} \right\|^2} - \sum\limits_{i = 1}^N {{\alpha _i}\left[ {{y_i}\left( {{{\bf{w}}^{\rm{T}}}{{\bf{x}}_i} + b} \right) - 1} \right]} \\ = \frac{1}{2}{\left\| {\bf{w}} \right\|^2} + \sum\limits_{i = 1}^N - {\alpha _i}{y_i}\left( {{{\bf{w}}^{\rm{T}}}{{\bf{x}}_i} + b} \right) + \sum\limits_{i = 1}^N {{\alpha _i}} \end{array}
L(w,b,α)=21∥w∥2−i=1∑Nαi[yi(wTxi+b)−1]=21∥w∥2+i=1∑N−αiyi(wTxi+b)+i=1∑Nαi
其中
α
=
(
α
1
;
α
2
;
⋯
;
α
N
)
\boldsymbol{\alpha}=(\alpha_1;\alpha_2;\cdots;\alpha_N)
α=(α1;α2;⋯;αN)。
根据拉格朗日对偶性,原始问题的对偶问题是极大极小问题
max
α
min
w
,
b
L
(
w
,
b
,
α
)
\large\max _{\boldsymbol{\alpha}} \min _{\boldsymbol{w}, b}L(\boldsymbol{w}, b, \boldsymbol{\alpha})
αmaxw,bminL(w,b,α)
为了得到对偶问题的解,需要先求
L
(
w
,
b
,
α
)
L(\boldsymbol{w}, b, \boldsymbol{\alpha})
L(w,b,α)对
w
,
b
\boldsymbol{w}, b
w,b的极小,再求对
α
\boldsymbol{\alpha}
α的极大。
Ⅰ.求 min w , b L ( w , b , α ) \min\limits _{\boldsymbol{w}, b}L(\boldsymbol{w}, b, \boldsymbol{\alpha}) w,bminL(w,b,α)
令
L
(
w
,
b
,
α
)
L(\boldsymbol{w}, b, \boldsymbol{\alpha})
L(w,b,α)对
w
w
w和
b
b
b的偏导为零可得
w
−
∑
i
=
1
N
α
i
y
i
x
i
=
0
−
∑
i
=
1
N
α
i
y
i
=
0
\large{\begin{aligned} \boldsymbol{w} - \sum_{i=1}^{N} \alpha_{i} y_{i} \boldsymbol{x}_{i} = 0 \\ -\sum_{i=1}^{N} \alpha_{i} y_{i} = 0 \end{aligned}}
w−i=1∑Nαiyixi=0−i=1∑Nαiyi=0
将上式代入拉格朗日函数,可得
L
(
w
,
b
,
α
)
=
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
T
x
j
)
−
∑
i
=
1
N
α
i
y
i
(
(
∑
j
=
1
N
α
j
y
j
x
j
)
⋅
x
i
+
b
)
+
∑
i
=
1
N
α
i
=
−
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
T
x
j
)
+
∑
i
=
1
N
α
i
\begin{aligned} L(\boldsymbol{w}, b, \boldsymbol{\alpha}) &=\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(\boldsymbol{x}_i^{\mathrm{T}} \boldsymbol{x}_{j}\right)-\sum_{i=1}^{N} \alpha_{i} y_{i}\left(\left(\sum_{j=1}^{N} \alpha_{j} y_{j} \boldsymbol{x}_j\right) \cdot \boldsymbol{x}_i+b\right)+\sum_{i=1}^{N} \alpha_{i} \\ &=-\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(\boldsymbol{x}_i^{\mathrm{T}} \boldsymbol{x}_{j}\right)+\sum_{i=1}^{N} \alpha_{i} \end{aligned}
L(w,b,α)=21i=1∑Nj=1∑Nαiαjyiyj(xiTxj)−i=1∑Nαiyi((j=1∑Nαjyjxj)⋅xi+b)+i=1∑Nαi=−21i=1∑Nj=1∑Nαiαjyiyj(xiTxj)+i=1∑Nαi
$$
\min {\boldsymbol{w}, b}L(\boldsymbol{w}, b, \boldsymbol{\alpha})=-\frac{1}{2} \sum{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(\boldsymbol{x}i^{\mathrm{T}} \boldsymbol{x}{j}\right)+\sum_{i=1}^{N} \alpha_{i}
$$
Ⅱ.求
min
w
,
b
L
(
w
,
b
,
α
)
\min\limits _{\boldsymbol{w}, b}L(\boldsymbol{w}, b, \boldsymbol{\alpha})
w,bminL(w,b,α)对
α
\boldsymbol{\alpha}
α的极大,即是对偶问题
max
α
−
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
T
x
j
)
+
∑
i
=
1
N
α
i
\max _{\boldsymbol{\alpha}} -\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(\boldsymbol{x}_i^{\mathrm{T}} \boldsymbol{x}_{j}\right)+\sum_{i=1}^{N} \alpha_{i}
αmax−21i=1∑Nj=1∑Nαiαjyiyj(xiTxj)+i=1∑Nαi
KaTeX parse error: Undefined control sequence: \ at position 2: \̲ ̲\text { s.t. } …
解出
α
\boldsymbol{\alpha}
α后,求出
w
\boldsymbol{w}
w和
b
b
b即可得到模型
f
(
x
)
=
w
T
x
+
b
=
∑
i
=
1
N
α
i
y
i
x
i
T
x
+
b
\begin{aligned} f(\boldsymbol{x}) &=\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b \\ &=\sum_{i=1}^{N} \alpha_{i} y_{i} \boldsymbol{x}_{i}^{\mathrm{T}} \boldsymbol{x}+b \end{aligned}
f(x)=wTx+b=i=1∑NαiyixiTx+b
α
\boldsymbol{\alpha}
α中的任一
α
i
\alpha_i
αi是拉格朗日乘子,恰对应着训练样本
(
x
i
,
y
i
)
(\boldsymbol{x}_i,y_i)
(xi,yi)。
SVM基本型中的不等式约束要求上述过程满足KKT(Karush-Kuhn-Tucker)条件,即
{
α
i
⩾
0
y
i
f
(
x
i
)
−
1
⩾
0
α
i
(
y
i
f
(
x
i
)
−
1
)
=
0
\left\{\begin{array}{l} \alpha_{i} \geqslant 0 \\ y_{i} f\left(\boldsymbol{x}_{i}\right)-1 \geqslant 0 \\ \alpha_{i}\left(y_{i} f\left(\boldsymbol{x}_{i}\right)-1\right)=0 \end{array}\right.
⎩⎨⎧αi⩾0yif(xi)−1⩾0αi(yif(xi)−1)=0
由
α
i
(
y
i
f
(
x
i
)
−
1
+
ξ
i
)
=
0
\alpha_{i}\left(y_{i} f\left(\boldsymbol{x}_{i}\right)-1+\xi_{i}\right)=0
αi(yif(xi)−1+ξi)=0可得,对于任意训练样本
(
x
i
,
y
i
)
(\boldsymbol{x}_i,y_i)
(xi,yi),总有
α
i
=
0
\alpha_{i}=0
αi=0或
y
i
f
(
x
i
)
=
1
y_{i} f\left(\boldsymbol{x}_{i}\right)=1
yif(xi)=1。
- 若 α i = 0 \alpha_{i}=0 αi=0,则该样本不会出现在 f ( x ) f(\boldsymbol{x}) f(x)的求和项中,也就不会对模型 f ( x ) f(\boldsymbol{x}) f(x)产生影响
- 若 α i > 0 \alpha_{i}>0 αi>0,则必有 y i f ( x i ) = 1 y_{i} f\left(\boldsymbol{x}_{i}\right)=1 yif(xi)=1,对应的样本点是一个支持向量
依此可推出SVM的一个重要性质:最终模型仅与支持向量有关,大部分训练样本无需保留。
3.软间隔SVM对偶问题
四.核函数&核方法
1.非线性分类问题
非线性分类问题是指通过利用非线性模型才能很好地进行分类的问题。
在前面的讨论中,我们假设训练数据集是线性可分的,即存在一个划分超平面能将训练样本正确分类。
但在现实任务中,原始样本空间不一定存在一个能正确划分两类样本的超平面。
我们无法用直线(线性模型)正确划分两类,但我们可以用一条椭圆曲线(非线性模型)将它们正确分开。
非线性问题往往不好求解,所以希望能用解线性分类问题的方法解决这个问题。
我们可以进行一个非线性变换,将非线性问题转化为线性问题,通过解变换后的线性问题的方法求解原来的非线性问题。















 7350
7350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









