







HASH
该结构可以认为是 Java语言中的Map嵌套,在底层结构中他在数据量多的情况下也的确是采用dict(字典)嵌套实现的
常用命令
-
存储一个哈希表key的键值
HSET [key] [field] [value] -
存储一个不存在的哈希表key的键值
HSETNX key field value -
在一个哈希表key中存储多个键值对
HMSET key field value [field value ...] -
获取哈希表key对应的field键值
HGET key field -
批量获取哈希表key中多个field键值
HMGET key field [field ...] -
删除哈希表key中的field键值
HDEL key field [field ...] -
返回哈希表key中field的数量
HLEN key -
返回哈希表key中所有的键值
HGETALL key -
不常用
HKEYS key //获取所有key HVALS key //获取所有的avlue HEXISTS key field //是否存在key field的value HSCAN key cursor [MATCH pattern] [COUNT count] //分页遍历 HSTRLEN key field //value长度
原子操作
-
为哈希表key中field键的值加上增量increment
HINCRBY key field incrementHINCRBYFLOAT key field increment
底层结构
Hash 数据结构底层实现为一个字典( dict ),也是RedisBb用来存储K-V的数据结构,当数据量比较小,或者单个元素比较小时,底层用ziplist存储

- 采用ziplist存储时,存储field与value、len、prerawlen,进行查找时遍历即可,
数据量小时该方式查询速度退化小,空间利用率高 - 采用hashtable时,则嵌套了一层dict,采用field进行hash算法O(1)速度查找,
查找速度快,,由于需要存储dictEntry、redisObjecct等结构与指针,空间利用率没有ziplist高
限制阈值设置,转换为hashtable(ht)编码,实际上就是dict(字典)
- hash-max-ziplist-entries 512 // ziplist 元素个数超过 512 ,将改为hashtable编码
- hash-max-ziplist-value 64 // 单个元素大小超过 64 byte时,将改为hashtable编码
应用场景
- 对象缓存
- HMSET user 1:name zhuge 1:balance 1888 //存储对象数据
HMGET user 1:name 1:balance //获取对象数据 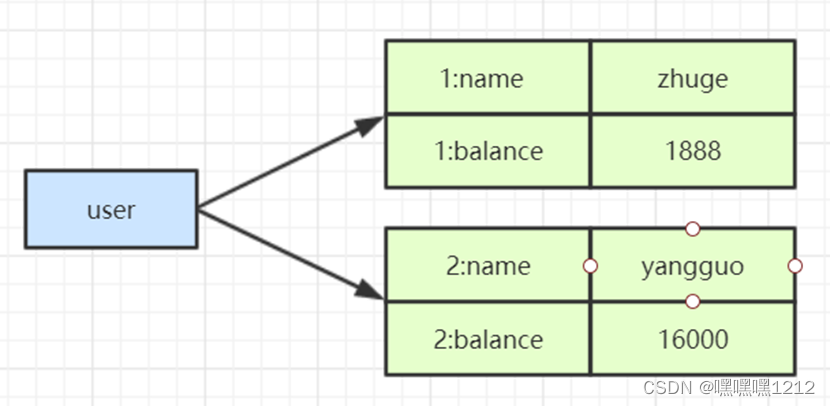
- 与String存储对象比较
- string 在存储方面诺在同一对象数据存储多string数据,会造成redis内部rehash(扩容),不存储同一string是为了避免大value
- hash 在占用上可刻意存储对象字段数据,不会造成外部dict频繁rehash
- string存在过期时间
- hash无法为内部字段设置过期时间
- HMSET user 1:name zhuge 1:balance 1888 //存储对象数据
- 电商购物车
- 以用户id为key,商品id为field,商品数量为value
- 添加商品 hset cart:1001 10088 1
增加数量 hincrby cart:1001 10088 1
商品总数 hlen cart:1001
删除商品 hdel cart:1001 10088
获取购物车所有商品hgetall cart:1001
总结
优点
- 同类数据可进行归类存储,方便了数据的管理
- 相比string操作消耗内存与cpu更小(在需要存储和获取同类数据)
- 相比string存储更节约空间(在需要存储和获取同类数据)
缺点
- field无法使用过期时间功能,只能够使用在key
- 在 Redis集群架构下不适合大规模使用

















 911
911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











