







原文阅读:【巨人肩膀社区·博客·分享】Bigtop 从0开始
bigtop 使用示例:
这里使用 官方的bigtop 3.2.0 作为示例,使用centos7 为编译操作系统,其他的系统和其他版本也是一样的操作。
1.创建一个开发目录
mkdir /home/jialiang/dev/2.克隆bigtop 到本地
cd /home/jialiang/dev/
git clone https://github.com/apache/bigtop.git3.切换到3.2.0
git checkout release-3.2.0#这里假设你的Linux 宿主机已经安装好了docker
4.拉取bigtop 的centos7 编译环境镜像
#如果你要编译其他操作系统或者其他架构比如arm
#可以去这个bigtop 的镜像仓库,搜索对应的bigtop 版本,然后在其中找你需要的操作系统的镜像包
#https://hub.docker.com/r/bigtop/slaves/tags
docker pull bigtop/slaves:3.2.0-centos-75.1启动镜像
情况1:
如果你之前在本地编译过大数据组件,本地有 maven的仓库的缓存,最好把这个maven仓库目录映射到容器的maven的默认下载目录下去,这样就不需要重复下载包.
比如你本地的maven仓库目录是 /data/sdv1/repository,可以这样启动
cd /home/jialiang/dev/bigtop
docker run -d -it --network host -v `pwd`:/ws -v /data/sdv1/repository:/root/.m2/repository --workdir /ws --name bigtopr bigtop/slaves:3.2.0-centos-7情况2:
如果你本地之前没maven 缓存,或者你不懂这个,那么我们也要映射一个目录到bigtop 镜像中,方便反复编译时,可以使用下载好的maven缓存,否则镜像删除后,你下的maven缓存就没了,而我们重复编译时,最耗时的阶段就是依赖下载,因此需要避免这种情况发生。
mkdir -p /root/.m2/repository
cd /home/jialiang/dev/bigtop
docker run -d -it --network host -v `pwd`:/ws -v /root/.m2/repository:/root/.m2/repository --workdir /ws --name bigtopr bigtop/slaves:3.2.0-centos-75.2 修改镜像中的 maven 源为阿里云的源
由于镜像中默认的maven 中使用的yum 源是国外的,即使能科学上网,下载也很慢,这里需要把这个配置文件替换为国内阿里云源。
1.进入镜像
docker exec -it bigtop /bin/bash2.修改镜像地址
vi /usr/local/maven/conf/settings.xml把里面的内容替换如下:
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
http://maven.apache.org/xsd/settings-1.0.0.xsd">
<localRepository/>
<interactiveMode/>
<usePluginRegistry/>
<offline/>
<pluginGroups/>
<servers/>
<mirrors>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>central</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/central</url>
</mirror>
<mirror>
<id>repo1</id>
<mirrorOf>central</mirrorOf>
<name>central repo</name>
<url>http://repo1.maven.org/maven2/</url>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>apache snapshots</mirrorOf>
<name>阿里云阿帕奇仓库</name>
<url>https://maven.aliyun.com/repository/apache-snapshots</url>
</mirror>
</mirrors>
<proxies/>
<activeProfiles/>
<profiles>
<profile>
<repositories>
<repository>
<id>aliyunmaven</id>
<name>aliyunmaven</name>
<url>https://maven.aliyun.com/repository/public</url>
<layout>default</layout>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>MavenCentral</id>
<url>http://repo1.maven.org/maven2/</url>
</repository>
<repository>
<id>aliyunmavenApache</id>
<url>https://maven.aliyun.com/repository/apache-snapshots</url>
</repository>
</repositories>
</profile>
</profiles>
</settings>5.3 修改 bigtop 中的仓库地址为 阿里云地址
在宿主机上执行
cd /home/jialiang/dev/bigtop
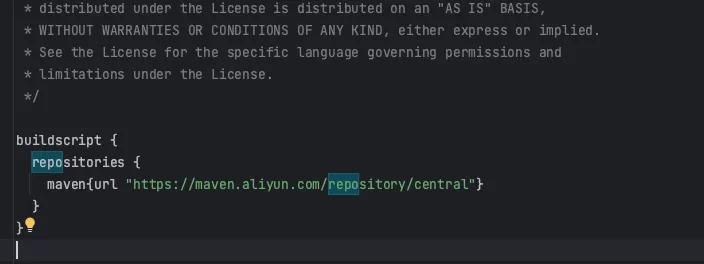
vi build.gradle把 build.gradle 中 buildscript 中的 mavenCentral() 替换为
maven{url "https://maven.aliyun.com/repository/central"}
如下图所示
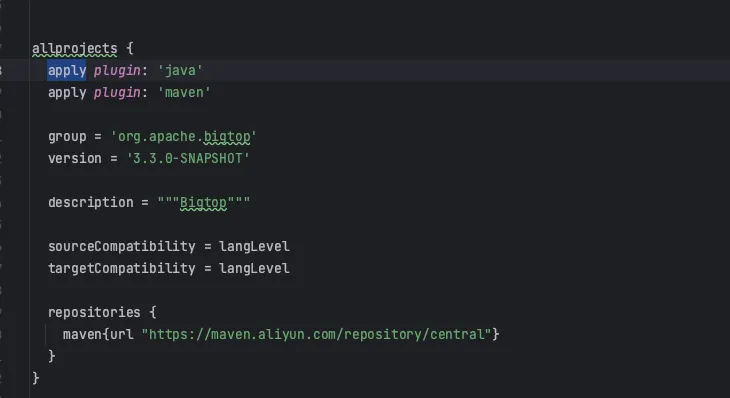
然后把 allprojects { 中的 mavenCentral() 也替换为阿里云源
maven{url "https://maven.aliyun.com/repository/central"}
如下图所示
5.4 可选(这一步主要解决部分组件编译 maven 仍然不走国内源,下载maven 依赖慢的问题)
这一步其实也可以忽略,顶多让依赖下载比较慢
即使修改了 maven 仓库和阿里云的源,仍然会有不少组件下载 maven 依赖时用的国外的源,
因为这些组件的pom 文件中指定了repository
所以需要下载对应组件的源码,然后修改 pom 中的repo, 做成patch,然后把patch 添加到bigtop 指定目录即可
6 编译大数据组件
进入你启动的镜像
docker exec -it bigtop /bin/bash编译组件
. /etc/profile.d/bigtop.sh;./gradlew flink-clean flink-pkg -PparentDir=/usr/bigtop -PpkgSuffix -PbuildThreads=2C repo这里解释下编译参数
如果要编译ambari 下使用的大数据组件需要加这两个参数:
-PparentDir=/usr/bigtop -PpkgSuffix
第一个参数 -PparentDir=/usr/bigtop 作用是 改名包的默认安装路径,使bigtop 打出来的包符合ambari 的安装规范
第二个参数是打出来的包带了bigtop 版本号 类似 hadoop_3_2_0 符合 ambari bigtop service 的规范
等待编译完成。
对于apache bigtop 的并行编译,加快编译速度,相关PR已经提到社区,正在review 合并,进度是目前所有 bigtop 中的java组件都可以并行编译,预计在bigtop3.2.1 之后的版本发布
使用并行编译在打包时的耗时对比,这里是在所有依赖下载完成的情况下,重复编译的性能对比,平均有2-3倍的编译速度提升,在初次编译时,效果尤其明显,比如hadoop 初次编译耗时3H,并发编译耗时1H:
centos7 x86_64 16C maven3.8.8
docker run -d -it --network host -v `pwd`:/ws -v /data/sdv1/repository:/data/sdv1/repository --workdir /ws --name bigtop bigtop/slaves:trunk-centos-7 --cpus 16
source /etc/profile.d/bigtop.sh
./gradlew alluxio-clean alluxio-pkg -PcompileThreads=2C| Component | Time Before | Time After |
| Alluxio | 21min | 07:43min |
| Hive | 05:33min | 03:04min |
| HBase | 06:18min | 02:55min |
| Zookeeper | 01:25min | 35s |
| Livy | 03:29min | 03:12min |
| Phoenix | 11:23min | 05:32min |
| Zeppelin | 14:15min | 13:19min |
| Flink | 36:27min | 14:16min |
| Hadoop | 50min | 16min |
















 2981
2981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









