







1. 数组名的理解
数组名就是首元素地址,当然,有两个例外
1. sizeof() 中的数组名指的是整个数组,计算的是整个数组的大小,单位是字节
2. &数组名 ,这里的数组名表示整个数组,取出的是整个数组的地址
除此之外,任何地方使用数组名,数组名都表示数组首元素地址 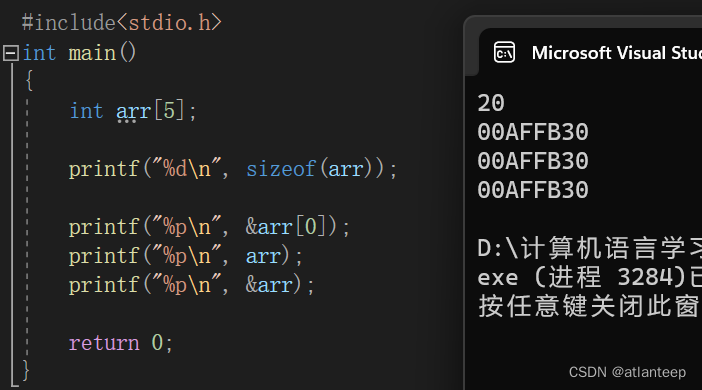
经过观察上面一段代码打印出来的结果显示,3个地址打印出来是相同的,那 arr 和 &arr 的区别是怎么体现的?
事实上,当我们将 地址+1 后就会发现 arr+1跳过了4个字节 而 &arr+1跳过了20个字节,也就是跳过了整个数组
2. 使用指针访问数组
使用指针输入和输出数组
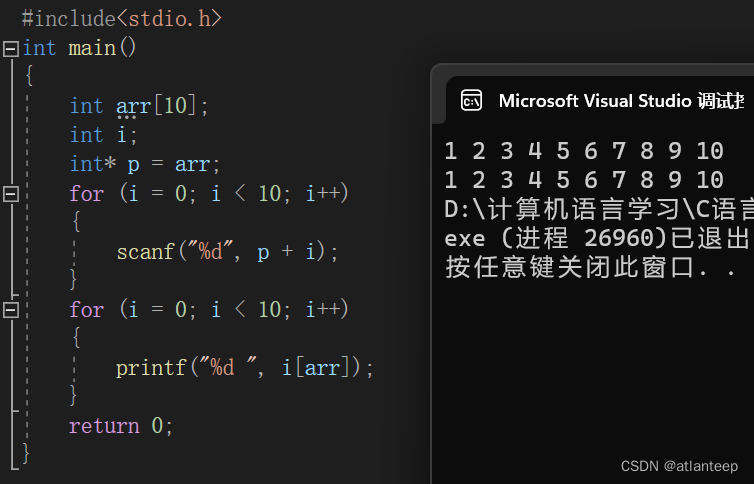
当然你会注意到一个奇怪的表达式 i[arr] 这是怎么回事
arr[i] 等价于 *(arr+i)
*(arr+i) 等价于 *(p+i) 等价于 p[i]
因为加法的交换率
*(arr+i) 等价于 *(i+arr)
最后根据第一个等式
*(i+arr) 等价于 i[arr]
为什么会这样
因为编译器在计算的时候会将譬如 arr[i]的下标引用操作符,转化成 *(arr+i) 的指针形式操作
3. 一维数组传参的本质
数组在传参的时候,传的并非是数组,而是数组首元素的地址
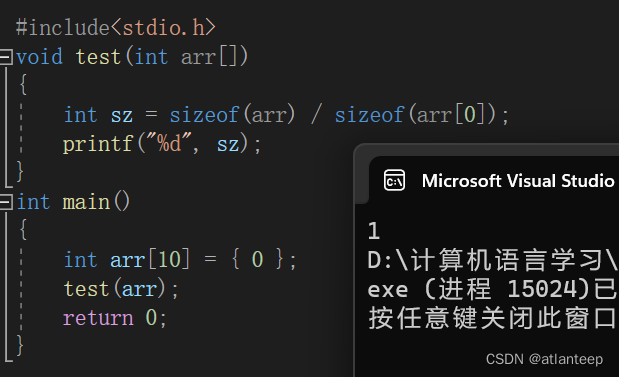
这段代码中在函数中计算数组的大小,发现并不是我们想要的结果,这时因为数组传参只是将数组首元素的地址传过去了,也就是说 sizeof(arr) 只能看见4个字节 4/4 自然等于1
可以说 int arr[] 完全可以写成 int* arr
4. 冒泡排序
思想:相邻的两个元素比较,如果不满足顺序就交换,一趟冒泡排序会将最大或最小值沉底,当沉底结束之后( n-1 趟)就完成了排序 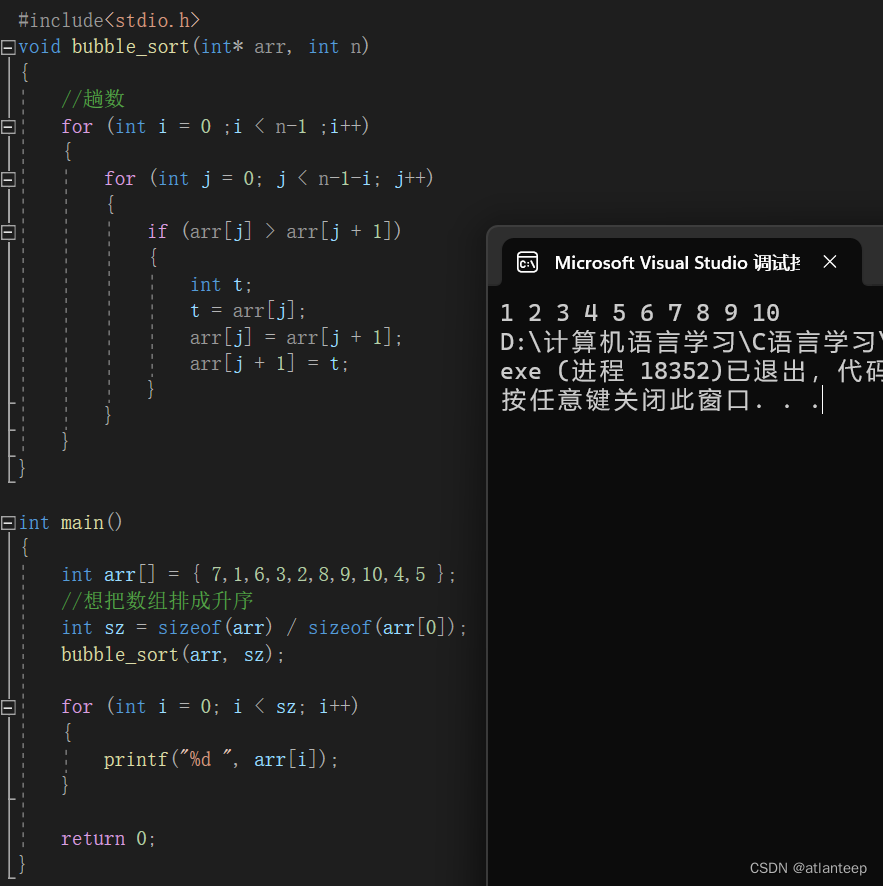
当然这么排序有它的缺点,就是当需要排序的数列并不是很无序的情况下,冒泡会将本来不用交换位置的值再重复的检测
冒泡排序是所有排序方法中效率最低的,更多排序方法我会之后专门写一期博客,敬请大家指正。
5. 二级指针
对于指针我们可以这么理解:
变量紧前面的 * 代表这个变量是指针变量,而该 * 前面的部分是在说明这个指针变量指向的对象的类型
事实上语法上是支持三级指针、四级指针、五级指针,但是实际应用中一般用到二级指针就够了
6. 指针数组
指针数组是存放指针的数组,就如同整形数组是存放整形的数组,字符数组是存放字符的数组
int arr[10]; 整形数组:每个元素都是整形
char ch[10]; 字符数组:每个元素都是字符
int* p_arr[10]; 指针数组:每个元素都是整形指针
7. 指针数组模拟二维数组
思路:二维数组就是将一维数组的整合
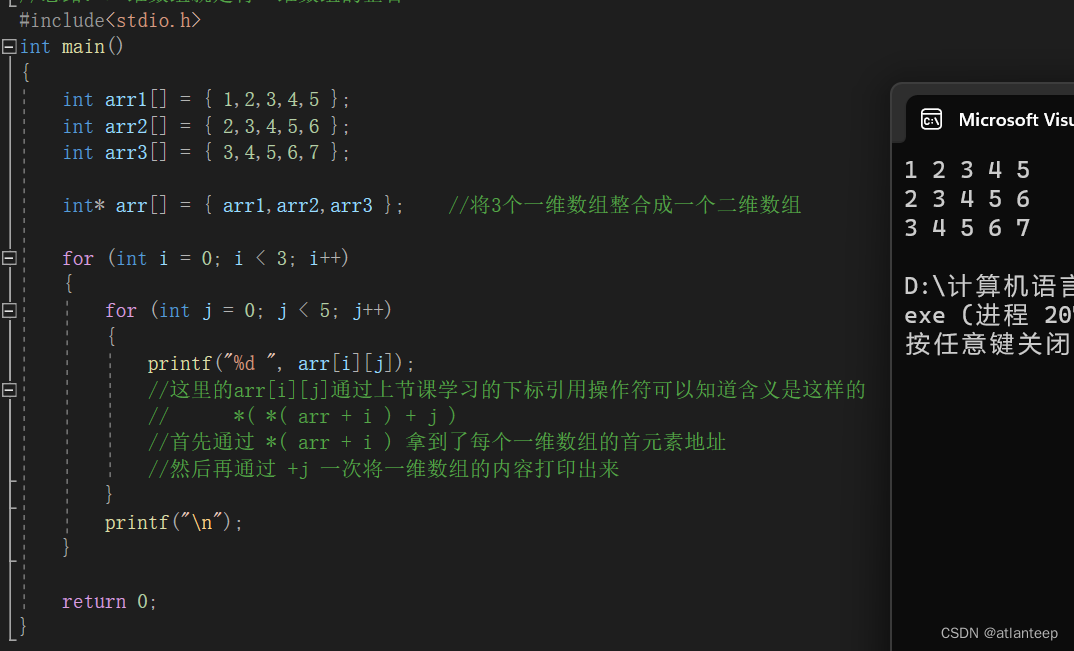
这里只是单纯的模拟二维数组,并不是真正建立二维数组的过程,因为真正的二维数组是要连续存放在一块内存中的















 227
227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









