







主成分分析 PCA
1.主成分分析Principal Component Analysis
是一个非监督的机器学习算法,主要用于数据的降维
通过降维,可以发现更便于人类理解的特征
其他应用:可视化,去噪
2.主成分分析的推导过程
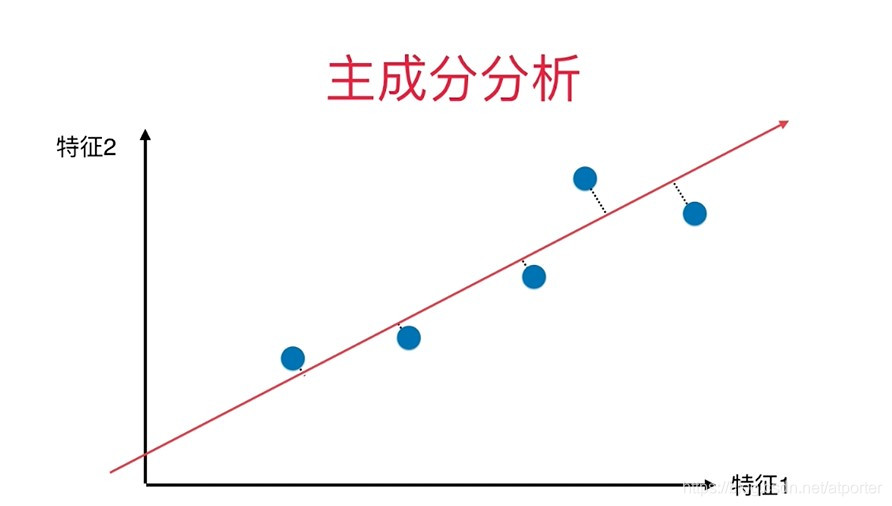
考虑这样一个过程:将二维数据降维到一维
最好的方案为:找到一个轴,使得样本空间的所有点映射到这个轴后,间距最大
样本间间距——方差
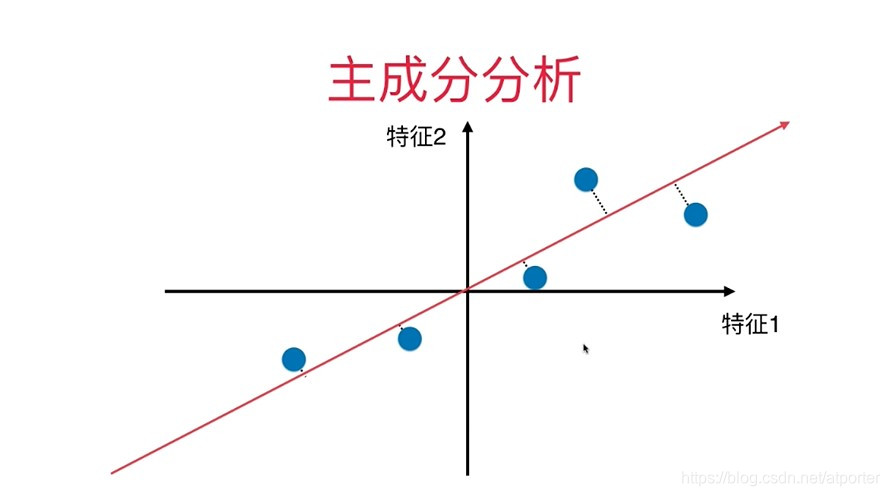
首先,将样例的均值归为0(demean),方差公式变为: V a r ( x ) = 1 m ∑ i = 1 m ( x i − x ‾ ) 2 = 1 m ∑ i = 1 m x i 2 Var(x) = \frac{1}{m}\sum_{i=1}^{m}(x_i - \overline{x})^2 = \frac{1}{m}\sum_{i=1}^{m}x_i^2 Var(x)=m1∑i=1m(xi−x)2=m1∑i=1mxi2
目标为:求一个轴的方向 w = ( w 1 , w 2 ) w = (w_1, w_2) w=(w1,w2),使得所有的样本映射到 w w w以后,有 V a r ( X p r o j e c t ) = 1 m ∑ i = 1 m ∣ ∣ X p r o j e c t ( i ) ∣ ∣ 2 Var(X_{project}) = \frac{1}{m}\sum_{i=1}^m||X_{project}^{(i)}||^2 Var(Xproject)=m1∑i=1m∣∣Xproject(i)∣∣2 最大
进一步考虑, w w w为单位向量,则 ∣ ∣ X p r o j e c t ( i ) ∣ ∣ ||X_{project}^{(i)}|| ∣∣Xproject(i)∣∣可以写成 X ( i ) X^{(i)} X(i)和 w w w的点积 X ( i ) ⋅ w X^{(i)}\cdot w X(i)⋅w
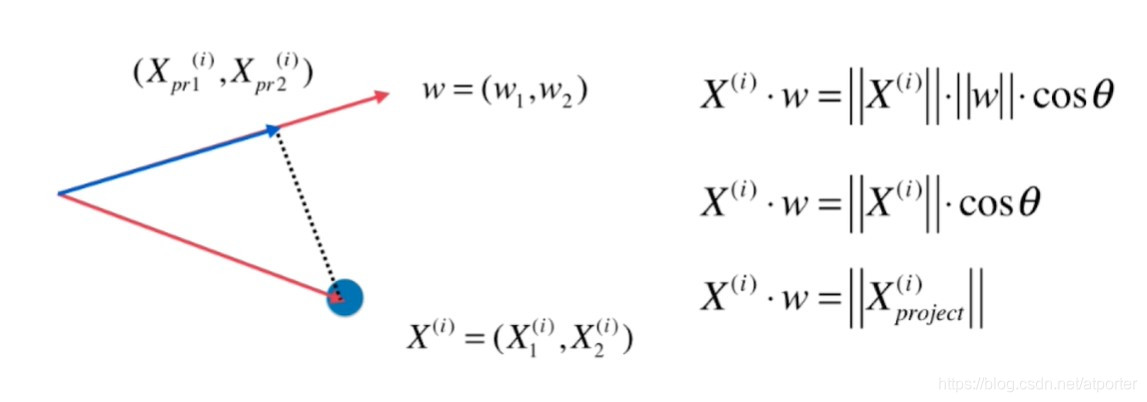
目标变为:求 w w w,使得 V a r ( X p r o j e c t ) = 1 m ∑ i = 1 m ( X ( i ) ⋅ w ) 2 = 1 m ∑ i = 1 m ( X 1 ( i ) w 1 + X 2 ( i ) w 2 + . . . + X n ( i ) w n ) 2 Var(X_{project}) = \frac{1}{m}\sum_{i=1}^{m}(X^{(i)}\cdot w)^2 = \frac{1}{m}\sum_{i=1}^{m}(X_1^{(i)}w_1 + X_2^{(i)}w_2+...+X_n^{(i)}w_n)^2 Var(Xproject)=m1∑i=1m(X(i)⋅w)2=m1∑i=1m(X1(i)w1+X2(i)w2+...+Xn(i)wn)2 最大
这是一个目标函数的最优化问题,可以使用梯度上升法来解决
3.使用梯度上升法求解PCA问题
目标:求 w w w,使得 f ( X ) = 1 m ∑ i = 1 m ( X ( i ) ⋅ w ) 2 = 1 m ∑ i = 1 m ( X 1 ( i ) w 1 + X 2 ( i ) w 2 + . . . + X n ( i ) w n ) 2 f(X) = \frac{1}{m}\sum_{i=1}^m (X^{(i)}\cdot w)^2 = \frac{1}{m}\sum_{i=1}^{m}(X_1^{(i)}w_1 + X_2^{(i)}w_2+...+X_n^{(i)}w_n)^2 f(X)=m1∑i=1m(X(i)⋅w)2=m1∑i=1m(X1(i)w1+X2(i)w2+...+Xn(i)wn)2 最大
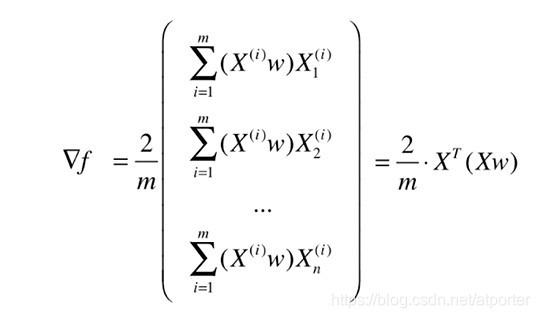
编程实现
def demean(X):
return X - np.mean(X, axis=0)
def f(w, X):
return np.sum((X.dot(w)) ** 2) / len(X)
def df(w, X):
return X.T.dot(X.dot(w)) * 2. / len(X)
def direction(w): # w单位化
return w / np.linalg.norm(w)
def gradient_ascent(X, initial_w, eta, n_iters=1e4, epsilon=1e-8):
w = direction(initial_w)
cur_iter = 0
while cur_iter < n_iters:
gradient = df(w, X)
last_w = w
w = w + eta * gradient
w = direction(w)
if abs(f(w, X) - f(last_w, X)) < epsilon:
break
cur_iter += 1
return w
initial_w = np.random.random(X.shape[1]) # w不能初始化为0向量,因为这样梯度也为0
eta = 0.001
X_demean = demean(X)
w = gradient_ascent(X_demean, initial_w, eta)
4.求数据的前n个主成分
求出第一主成分后,如何求出下一个主成分?
答:将数据在第一个主成分上的分量去掉,再在新的数据上求第一主成分
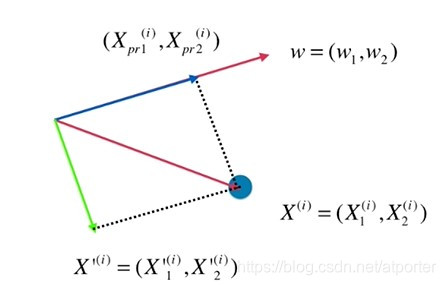
X ( i ) X^{(i)} X(i)去掉第一个主成分上的分量 X p r o j e c t ( i ) X_{project}^{(i)} Xproject(i),得到 X ′ ( i ) X'^{(i)} X′(i), X ′ ( i ) = X ( i ) − X p r o j e c t ( i ) X'^{(i)} = X^{(i)} - X_{project}^{(i)} X′(i)=X(i)−Xproject(i)
编程实现——求数据的前n个主成分
def first_n_components(n, X, eta=0.01, n_iters=1e4, epsilon=1e-8):
X_pca = X.copy()
X_pca = demean(X_pca)
res = []
for i in range(n):
initial_w = np.random.random(X_pca.shape[1])
w = first_component(X_pca, initial_w, eta) # 求出第一分量,参考上文梯度上升
res.append(w)
X_pca = X_pca - X_pca.dot(w).reshape(-1, 1) * w # 去掉第一分量
return res
5.高维数据向低维数据映射
将n维数据映射到k维空间上:
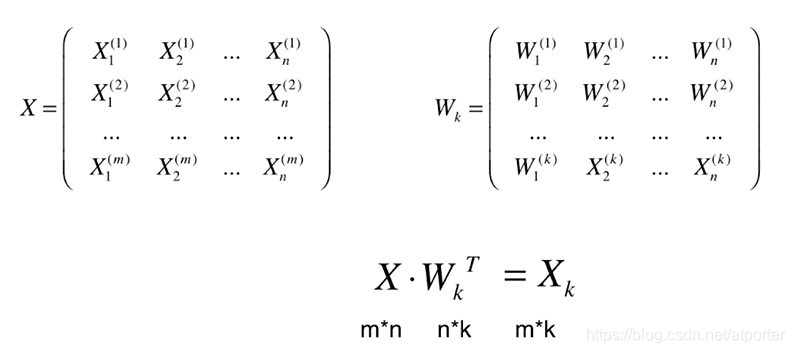
恢复:只是在高维空间内表达低位数据而已
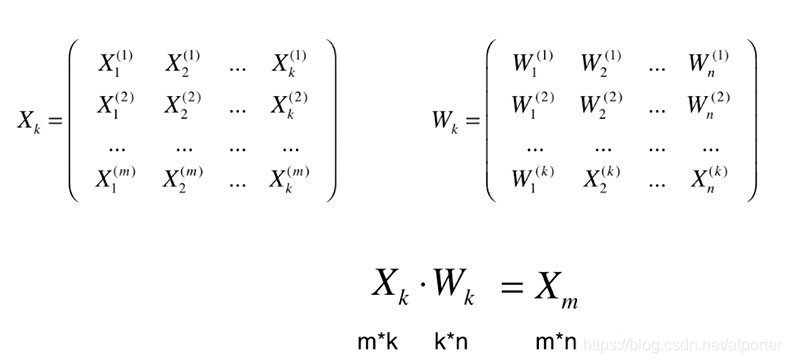
PCA降维过程中,存在信息丢失,且无法恢复。
如下图,我们将蓝点用PCA降维,恢复后只能得到红点
6.scikit-learn中的PCA
from sklearn import datasets
from sklearn.model_selection import train_test_split
digits = datasets.load_digits()
X = digits.data
y = digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
首先,使用KNN进行分类
%%time
# 使用KNN进行分类
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_train)
knn_clf.score(X_test, y_test)
Wall time: 13.9 ms
0.9866666666666667
使用PCA进行数据的降维
# 使用PCA进行数据的降维
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(X_train) # 计算各主成分的方向w
X_train_reduction = pca.transform(X_train)
X_test_reduction = pca.transform(X_test) # 必须将训练集和测试集降维到同样的低维空间
再使用KNN进行分类
%%time
# 再用KNN进行分类
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train_reduction, y_train)
knn_clf.score(X_test_reduction, y_test)
Wall time: 3 ms
0.6066666666666667
可以观察到,运行时间有明显的缩短,但是同样的,精度也在下降
这里,我们是将一个64维的数据降维到2维,那么2维是否是最合适的维数呢?
7.寻找最合适的维数
PCA有一个成员变量explained_variance_ratio_,可解释各主成分的方差占总方差的比率,占比越大,主成分越重要
计算上一个例子中的explained_variance_ratio_
pca.explained_variance_ratio_
# array([0.14566817, 0.13735469])
可以看出使用PCA降维到2维,只能解释28%的方差,会丢失70%以上的信息
下图为保留的信息与维数的关系
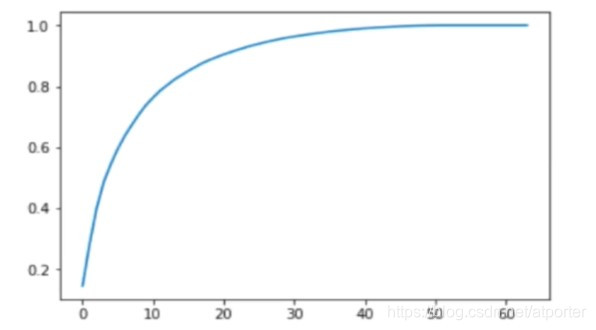
PCA可以自动选取合适的降维维数,只需提供欲保留的信息比例
pca = PCA(0.95) # 至少保持95%的信息
pca.fit(X_train)
pca.n_components_
# 28
X_train_reduction = pca.transform(X_train)
X_test_reduction = pca.transform(X_test)
%%time
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train_reduction, y_train)
knn_clf.score(X_test_reduction, y_test)
Wall time: 5.53 ms
0.98
在至少保持95%的信息的前提下,PCA将数据降维到28维,运行时间和精度都有很好的保证
8.使用PCA进行降噪
使用PCA降维会丢失一部分信息,但如果其中含有相当一部分噪声,降维后分类任务的精度反而会提升
PCA降噪前

PCA降噪后(降维再恢复)

9.特征脸(Eigenface)
我们求出的 W k W_k Wk矩阵,每一行都是一个 n n n维向量,代表一个主成分,而每一行数据同样是一个n维向量,所以我们可以将一个主成分 w w w看作一行数据
在人脸识别中,对人脸数据集做PCA,得到全部主成分。将每一个主成分当作一个图像,绘制出来,就得到了特征脸















 702
702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









