







概述
Imala是基于Hive并使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点。因为直接使用的Hive的metadata,也就是impala的元数据都存储在Hive中的metadata之中,并且Impala兼容大部分Hive语法。
优点
1、Impala特别快,因为所有的计算都可以放入内存当中进行完成,只要你内存足够大
2、摈弃了MR的计算,改用C++来实现,有针对性的硬件优化
3、具有数据仓库的特性,对hive的原有数据做数据分析
4、支持ODBC,jdbc远程访问
缺点
1、基于内存计算,对内存依赖性较大
2、改用C++编写,意味着维护难度增大
3、基于hive,与hive共存亡,紧耦合
4、稳定性不如hive,不存在数据丢失的情况
架构
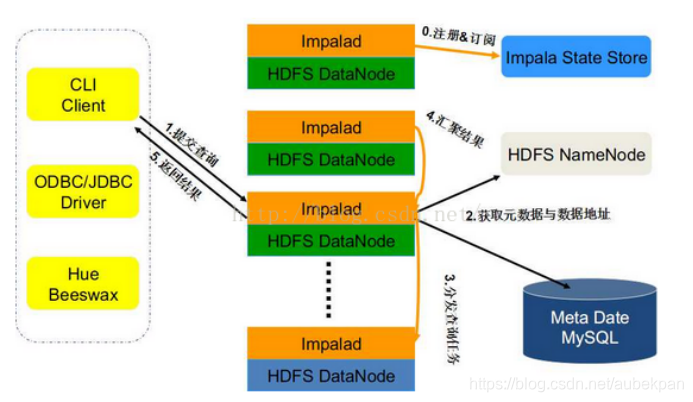
impala-server ==>启动的守护进程,执行我们的查询计划 从节点,官方建议与所有的datanode装在一起,可以通过hadoop的短路读取特性实现数据的快速查询
impal
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3666
3666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









