







一、LLVM的周边项目:
1.clang、llvm、clang-tools-extra、compiler-rt:
clang+LLVM:clang是LLVM的前端,把各种源码编译处理;
clang-tools-extra:clang默认以外的认为不是很重要的工具;
Compiler-RT 项⽬为硬件不⽀持的低级功能提供特定的⽀持。例如,32位
⽬标通常缺少⽀持64位除法的指令, Compiler-RT 通过提供特定⽬标的优
化函数来解决此问题,使⽤这样的函数可以在32位指令处理器上实现64位
除法。为LLVM IR;
eg:clang -S -m32 test.c -o test-32bit.S
clang -S test.c -o test-64bit.S

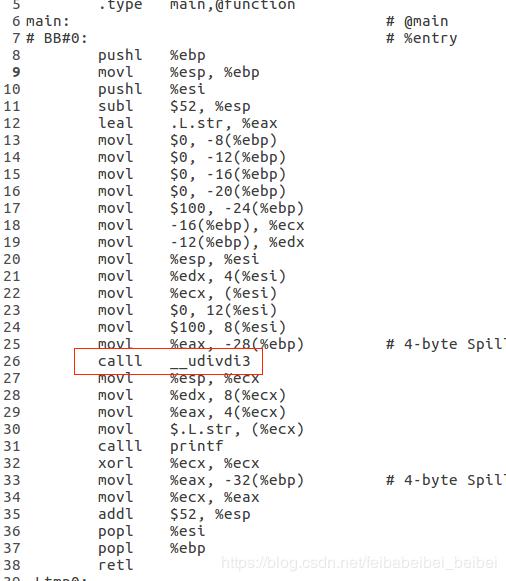
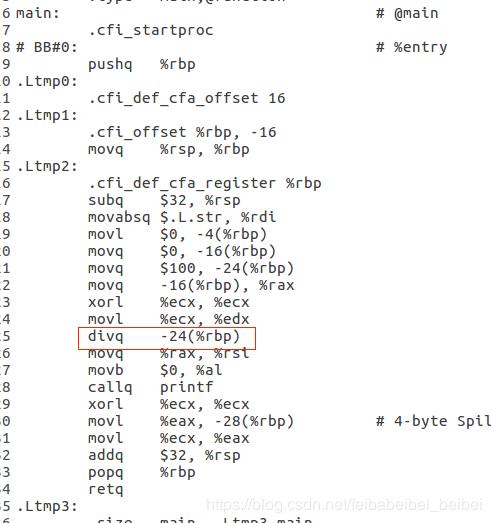
其中—udivdi3就是在Compiler-Rt中实现;
2.lldb、libc++:
lldb 项⽬属于全新的基础架构,该架构⽀持现代的多线程程序,并且以更加⾼效的⽅式处理调试符号,模块化的组件为功能的扩展打下良好的基础。另外,由于 lldb 更加开放的特性(其licsence并不是GPL。GPL要求使⽤GPL授权的产品都必须开源), lldb ⼏乎可以集成到任何想要集成的产品中去,⽽不⽤担⼼法律问题。lldb 会将调试信息转换为 clang 类型,以便它可以利⽤ clang 编译器的基础架构。这使得 lldb 可以在表达式中⽀持最新的 c 、 c++ 、 Objective-C 和 Objective-C++ 语⾔的所有功能和运⾏时,⽽⽆需重新实现这些功能。此外它还利⽤编译器来处理函数调⽤表达式时的所有ABI接⼝,反汇编指令和提取指令细节等流程,把 llvm 和 clang 的基础架构运⽤到了极致。libc++ 库是 llvm 项⽬对 C++ 标准库的重写,它⽀持包括 C++11 和 C++1y 在内的最新的 C++ 标准;
3.LLD
LLD 是 GNU 链接器的直接替代品,它接受与 GNU 相同的命令⾏参数和脚本⽂件。 lld 团队在与 FreeBSD 紧密合作的过程中,⾮常重视解决兼容性问题,因为希望能在未来版本的操作系统中,希望能选择LLD 作为系统的默认链接器。因此,截⾄2017年2⽉, LLD 已经能够链接整个 FreeBSD / amd64 基础系统,包括内核。
2. LLD 运⾏速度⾮常快,在多核计算机上链接⼤型程序时, LLD 的运⾏速度可以达到 GNU gold 链接器的两倍多。
3. LLD ⽀持各种 CPU / ABI ,包括 x86-64 , x86 , x32 , AArch64 , ARM , MIPS 32/64⼤/⼩端, PowerPC , PowerPC 64 和 AMDGPU 。其中, x86-64 的⽀持最为完美,完全可以⽤在⽣产环境, AArch64 和 MIPS 也不错。x86 只能说应该没问题,但尚未经过完美的测试,还有对 ARM 的⽀持,正在积极开发中。
4. 不管 lld 被如何编译出来,它始终是⼀个交叉链接器,始终⽀持上述所有⽬标架构。 lld 甚⾄都不提供编译时的选项来启⽤/禁⽤任何⼀个⽬标架构,所以,把 lld 集成到你的编译⼯具⾥应该可以很放⼼。
5. 可以将 LLD 嵌⼊到程序中去,以消除程序对外部链接器的依赖性。只需要构造⽬标⽂件和命令⾏参数,就像调⽤外部链接器⼀样,然后从代码中调⽤链接器的主函数 lld :: elf :: link 。
6. LLD 很⼩。使⽤ LLVM libObject 库来读取⽬标⽂件,虽然这样⽐较显得不是很公平,但截⾄2017年2⽉, LLD / ELF 仅包含 21k ⾏ C ++ 代码,⽽ GNU gold 包含 198k ⾏ C ++ 代码。这数据也⾜以说明 LLD 真的很⼩。
7. LLD 默认⽀持链接时优化( LTO )。想要使⽤ LTO 的话只需要将 -flto 选项传递给 clang ,然后 clang 则不会创建的本机的 native 对象格式,⽽是 LLVM bitcode 格式。然后 LLD 读取 bitcode ⽬标⽂件,使⽤ LLVM 编译并产⽣输出⽂件。在开启 LTO 时, LLD 参与编译的全部过程,对整个程序进⾏优化。
8. 古⽼的 Unix 系统(90年代之前甚⾄之前)的⼀些⾮常古⽼的功能已被删除。⼀些默认设置也已经进⾏了调整。例如,默认情况下,堆栈被标记为不可执⾏,来加强安全性。
用处:提高编译链接的速度
4.OpenMP
OpenMP 是由 OpenMP Architecture Review Board 牵头提出的,并已被⼴泛接受,⽤于共享内存并⾏系统的多处理器程序设计的⼀套指导性编译处理⽅案(Compiler Directive) 。OpenMP⽀持的编程语⾔包括 C 、 C++ 和Fortran ;⽽⽀持 OpenMp 的编译器包括 Sun Compiler , GNU Compiler 和 Intel Compiler 等。
OpenMp 提供了对并⾏算法的⾼层的抽象描述,程序员通过在源代码中加⼊专⽤的 pragma 来指明⾃⼰的意图,由此编译器可以⾃动将程序进⾏并⾏化,并在必要之处加⼊同步互斥以及通信。当选择忽略这些 pragma ,或者编译器不⽀持 OpenMp 时,程序⼜可退化为通常的程序(⼀般为串⾏),代码仍然可以正常运作,只是不能利⽤多线程来加速程序执⾏。
eg:提高clang++的版本增加编译速度:
5.Polly
Polly 的原理是从 LLVM-IR 开始,检测并提取有效的循环内核,然后对于每个内核,导出数学模型,并精确地描述内核中的各个计算和存储器访问,对这些数学模型执⾏各种分析和代码转换。 在派⽣并应⽤所有优化之后,将重新⽣成优化的 LLVM-IR 并将其插⼊ LLVM-IR 模块。
二、学习llvm源码目录:
那么这里面有一个宏观的概念,那就是一个编译单元(即一个.c文件),在LLVM IR中代表着一个Module,而一个Module里面含有Global Value,主要包括Global Variable 和 Function,而至于Global Alias接触比较少,而一个Function里面包含着Basic Block,而一个 Basic Block里面包含着指令,如add。那么关系你可以认为是Module -> Function -> Basic Block -> Instructions. 这是一个宏观的认识:

http://llvm.org/doxygen/classllvm_1_1GlobalValue.html

1.llvm/include:
从llvm库⾥导出来的头⽂件主要包含以下三个⼦⽂件夹:
llvm/include/llvm :所有LLVM特定的头⽂件,以及LLVM不同部分的⼦⽬录:Analysis,CodeGen,Target,Transforms等...
llvm/include/llvm/Support :为LLVM(不⼀定特定于LLVM)提供的通⽤⽀持库。例如,某些C ++ STL实⽤程序和命令⾏选项处理库也在此存储头⽂件。
llvm/include/llvm/Config :配置脚本配置的头⽂件。 它们包装“标准”UNIX和C头⽂件。 源代码可以包
含这些头⽂件,头⽂件⾃动处理配置脚本⽣成的条件
2.llvm/lib:
llvm/lib/IR/ :实现核⼼类(如Instruction和BasicBlock)的核⼼LLVM源⽂件。
llvm/lib/AsmParser/ :LLVM汇编语⾔解析器库的源代码。
llvm/lib/Bitcode/ :读写bitcode的代码。
llvm/lib/Analysis/ :各种程序分析,如调⽤图,感应变量,⾃然循环识别等。
llvm/lib/Transforms/ :IR到IR程序转换,例如积极死代码消除,稀疏条件常数传播,内联,循环不变代码,死全局消除等等。
llvm/lib/Target/ :描述代码⽣成的⽬标体系结构的⽂件。例如, llvm/lib/Target/X86 保存X86机器描述。
llvm/lib/CodeGen/ :代码⽣成器的主要部分:指令选择器,指令调度和寄存器分配。
llvm/lib/ExecutionEngine/ :⽤于在解释和JIT编译的场景中在运⾏时直接执⾏bitcode的库。
3.LLVM/tools:

llvm-ar :归档程序⽣成包含给定LLVM bitcode⽂件的归档⽂件,可选择使⽤索引以便更快地查找。
llvm-as :汇编:将⼈类可读的LLVM程序集转换为LLVM bitcode。
llvm-dis : 反汇编:将LLVM bitcode转换为⼈类可读的LLVM程序集。
llvm-link :链接器:将多个LLVM模块链接到⼀个程序中。
lli :LLVM解释器,它可以直接执⾏LLVMbitcode(虽然⾮常慢...)。对于⽀持它的架构(⽬前是x86,Sparc和PowerPC),默认情况下,lli将作为Just-In-Time编译器(如果编译了功能),并且将⽐解释器更快地执⾏代码。
llc :llc是LLVM后端编译器,它将LLVM bitcode转换为本机机器代码⽂件。当然也可以生成cpp(llvm3.8以下):



opt :opt读取LLVM bitcode, 负责将bitcode进⾏打乱、重组等等(在命令⾏中指定),并输出结果bitcode。 opt -help 命令获取更多细节。opt还可以对输⼊LLVM bitcode⽂件运⾏特定分析并打印结果,可以⽤于调试分析,可是从中找到很多运⾏的细节。这个⽂件夹⾥包含了,⽤于处理LLVM源代码的实⽤程序; 有些也是是构建过程的⼀部分,因为它们是部分基础结构的代码⽣成器。
问题:是不是通过重写lli就可以写出对于bc的解释器来?
调用的是JIT的引擎代码,比较脱离主题!
简单看一下lli的源码:
初始化:
https://github.com/llvm-mirror/llvm/blob/master/tools/lli/lli.cpp
三、定制编译系统
cmake配置详解
编译llvm源代码之前必须要使⽤CMake⼯具来进⾏配置。跟常规的 config
ure 配置脚本不同的是,CMake会⽣成各种各样的配置⽂件,包括各种 *.
inc ⽂件和 llvm/include/Config/config.h 。
传递给 cmake 命令的参数的格式为 -D<variable name>=<value> ,⼀般
会有以下⼏种参数和选项。
参数⽬的
CMAKE_C_COMPILER
告诉cmake使⽤哪个C编译器。 默认情况下,这将是 /usr/bin/cc 。
CMAKE_CXX_COMPILER
告诉cmake使⽤哪个C ++编译器。 默认情况下,这将是 / usr / bin / c ++ 。
CMAKE_BUILD_TYPE
告诉cmake您尝试为其⽣成⽂件的构建类型。 有效选项包括Debug,Release,
RelWithDebInfo和MinSizeRel。 默认为Debug。
CMAKE_INSTALL_PREFIX
指定运⾏构建⽂件的安装操作时的安装⽬录。
LLVM_TARGETS_TO_BUILD
以分号分隔的列表,⽤于控制将构建哪些⽬标并链接到llc。 这相当于configure脚本中
的--enable-targets选项。 默认列表定义为LLVM_ALL_TARGETS , 默认值包括:
AArch64,AMDGPU,ARM,BPF,Hexagon,Mips,MSP430,NVPTX,
PowerPC,Sparc,SystemZ,X86,XCore。LLVM_ENABLE_DOXYGEN
从源代码构建基于doxygen的⽂档。默认情况下禁⽤它,因为它很慢并且会产⽣⼤量输
出。
LLVM_ENABLE_SPHINX
从源代码构建基于sphinx的⽂档。 默认情况下禁⽤此选项,因为它很慢并产⽣⼤量输
出。 建议使⽤Sphinx 1.5或更⾼版本。
LLVM_BUILD_LLVM_DYLIB
⽣成libLLVM.so,这个库包含⼀组默认的LLVM组件,可以使⽤
LLVM_DYLIB_COMPONENTS覆盖这些组件。 默认值包含⼤部分LLVM的功能,并在
tools/llvm-shlib/CMakelists.txt义。
LLVM_OPTIMIZED_TABLEGEN
编译⼀个在LLVM编译期间使⽤的release版的 tablegen 。这可以⼤⼤加快调试版本的
运⾏速度。
LLVM IR
传统的静态编译器分为三个阶段:前端、中端(优化)、后端。
而大名鼎鼎的GCC编译器在设计的时候没有做好层次划分,导致很多数据在前端和后端耦合在了一起,所以GCC支持一种新的编程语言或新的目标架构特别困难。
有了GCC的前车之鉴,LLVM进行了如下图所示的三阶段设计

这样支持一种新的编程语言只需重新实现一个前端,支持一种新的目标架构只需重新实现一个后端,前端和后端连接枢纽就是LLVM IR。
LLVM IR本质上一种与源编程语言和目标机器架构无关的通用中间表示,是LLVM项目的核心设计和最大的优势。
LLVM IR是一种类似于RISC的低级虚拟指令集
LLVM IR使用静态单赋值(SSA)策略,具有以下两个特征:
- 以三地址码形式组织指令
- 假设有无数的寄存器可用
假设已经写好一个名为main.c的C程序代码,使用以下命令可以得到其LLVM IR
# 二进制代码形式
clang -emit-llvm -c main.c -o main.bc
# 可读文本代码形式
clang -S -emit-llvm -c main.c -o main.ll除了上面两种形式之外,LLVM IR还有一种形式是在内存中的编译中间语言
下图是一段add函数对应的LLVM IR示例

LLVM的含义
在不同的语义环境下,LLVM具有以下几种不同的含义:
- LLVM基础架构:即一个完整编译器项目的集合,包括但不限于前端、后端、优化器、汇编器、链接器、libc++标准库、Compiler-RT和JIT引擎
- 基于LLVM构建的编译器:部分或完全使用LLVM构建的编译器
- LLVM库:LLVM基础架构可重用代码部分
- LLVM核心:在LLVM IR上进行的优化和后端算法
- LLVM IR:LLVM中间表示
LLVM基础架构的组成部分
- 前端:将程序源代码转换为LLVM IR的编译器步骤,包括词法分析器、语法分析器、语义分析器、LLVM IR生成器。Clang执行了所有与前端相关的步骤,并提供了一个插件接口和一个单独的静态分析工具来进行更深入的分析
- 中间表示:LLVM IR可以以可读文本代码和二进制代码两种形式呈现。LLVM库中提供了对IR进行构造、组装和拆卸的接口。LLVM优化器也在IR上进行操作,并在IR上进行了大部分优化。
- 后端:负责汇编码或机器码生成的步骤,将LLVM IR转换为特定机器架构的汇编代码或而二进制代码,包括寄存器分配、循环转换、窥视孔优化器、特定机器架构的优化和转换等步骤
下面这张图展示了使用LLVM基础架构时各个组件之间的关系
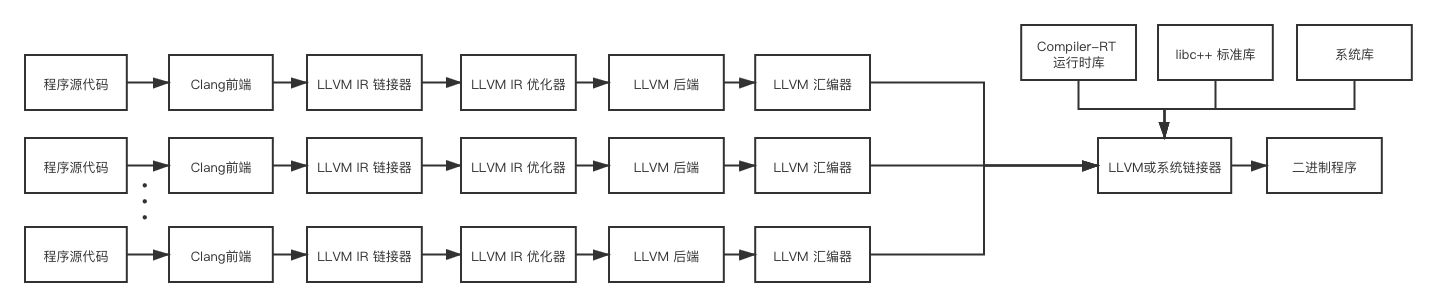
除此之外,各个组件之间的协作关系也可以以下面这种方式组织

两种方式的主要区别是程序源代码内部的链接是由LLVM或系统链接器完成的还是由LLVM IR链接器完成的,前者是默认方式,后者一般在开启链接优化(Link-Time Optimization)时采用
LLVM中间数据结构
在LLVM中并不只存在LLVM IR一种中间表现形式,LLVM在不同编译阶段采用以下不同的中间数据结构:
- LLVM IR:见文章开头
- 抽象语法树(AST):将源代码转换为LLVM IR时,Clang前端语法分析器和语义分析器的产出数据结构
- 有向无环图(DAG):将LLVM IR转换为特定机器架构的汇编代码时,LLVM首先将其转换为有向无环图(DAG)的形式,以方便进行指令选择,然后将其转换回三地址码的形式以进行指令调度
- MCModule类:为了实现汇编器和链接器,LLVM使用MCModule类将程序表示保存在对象文件(可重定向文件的一种,通常文件名以.o结尾)的上下文中
不同编译阶段的中间数据结构有以下两种存在方式:
- 内存中:需要编译驱动程序的帮助,将一个阶段的输出数据结构作为下一个阶段的输入数据结构
- 文件中:独立命令之间多数以文件为媒介进行交互,比如汇编器与链接器通过可重定向的`.o`对象文件进行交互














 2569
2569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









