






前言:
该笔记是谷粒商城笔记的扩充版~师从c老师
102 -
计划15天完成谷粒商城的学习,希望自己可以坚持下来
今天学了一个知识,说是主动学习可以建立更大的神经突触的链接,
2-2日更新
2-5日
本文面向小白
第1天到第2?天
第22天

调取服务(写在member中,调取coupon中的东西)


feign是一个桥梁啊,把他们连接起来了(@中要写coupon在nacon注册的名字,下面的requestmapping要写全coupon的路径,这样调服务就可以通过实例化一个couponfeignservice来实现了,总体来说就是实现了一个从一个服务调取另一个服务的功能,是死的)
(我感觉这一段虽然看起来简单,但是对于我这种小白来说还是有点绕的)
(关于R的讲解和使用,在后文有提到)

coupon中的内容
Autowired的作用
假设我们有一个简单的Web应用,其中有一个服务类
BookService用于处理与书籍相关的逻辑,还有一个控制器BookController用于处理与书籍相关的Web请求。服务类(Service Class)
首先,我们定义一个服务类
BookService,它提供了一个方法来获取书籍的名称。package com.example.demo.service; import org.springframework.stereotype.Service; @Service public class BookService { public String getBookName() { return "Spring in Action"; } }控制器类(Controller Class)
然后,我们定义一个控制器
BookController,它使用BookService来获取书名,并返回给客户端。package com.example.demo.controller; import com.example.demo.service.BookService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; @RestController public class BookController { @Autowired private BookService bookService; @GetMapping("/book/name") public String getBookName() { return bookService.getBookName(); } }在这个例子中,
BookController需要使用BookService的getBookName方法来获取书名。我们通过在BookService字段上使用@Autowired注解,告诉Spring自动注入BookService的实例。这样,当BookController的实例被创建时,Spring会自动查找类型为BookService的bean,并将其注入到bookService字段中。这意味着,当有请求到达
/book/name时,BookController的getBookName方法会被调用,它又会调用BookService的getBookName方法,最终返回书名“Spring in Action”给客户端。通过这个简单的例子,你可以看到
@Autowired注解如何使得依赖注入变得简单和自动化,从而减少了配置和手动管理对象之间依赖关系的需要。
在Spring框架中,使用@Autowired注解注入的bean默认是单实例的,这是因为Spring的bean默认的作用域是单例(Singleton)。这意味着,无论你在应用中的多少个地方注入了同一个类型的bean,Spring容器都会提供同一个实例。
单例作用域(Singleton Scope)
单例作用域意味着Spring容器在启动时会创建一个单一的bean实例,然后每次注入或者通过Spring容器的getBean()方法获取时,都是同一个实例。这种方式很适合那些无状态的服务,其中不保存任何调用者的状态信息。示例解析
继续上面的例子,无论系统中有多少个控制器、服务或者其他组件注入了BookService,所有地方注入的都将是同一个BookService实例。这样做的好处是减少了内存的使用,因为不需要为每个请求或每个使用该服务的类创建新的实例,同时也保证了应用中某些全局资源的一致性和唯一性。
2.R的作用
package com.atguigu.common.utils;
import org.apache.http.HttpStatus;
import java.util.HashMap;
import java.util.Map;
/**
* 返回数据
*
* @author Mark sunlightcs@gmail.com
*/
public class R extends HashMap<String, Object> {
private static final long serialVersionUID = 1L;
public R() {
put("code", 0);
put("msg", "success");
}
public static R error() {
return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, "未知异常,请联系管理员");
}
public static R error(String msg) {
return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, msg);
}
public static R error(int code, String msg) {
R r = new R();
r.put("code", code);
r.put("msg", msg);
return r;
}
public static R ok(String msg) {
R r = new R();
r.put("msg", msg);
return r;
}
public static R ok(Map<String, Object> map) {
R r = new R();
r.putAll(map);
return r;
}
public static R ok() {
return new R();
}
public R put(String key, Object value) {
super.put(key, value);
return this;
}
}
直接使用
HashMap实例化对象确实是可以的,但是通过扩展HashMap来创建一个自定义的R类有几个独特的优点,这些优点在于提高代码的可读性、易用性以及维护性:
增加语义性:
R类作为一个特定用途的类,比直接使用HashMap具有更强的语义性。当你看到返回类型是R时,可以很明确地知道这是用于返回响应数据的结构,而不是一个普通的键值对集合。这增加了代码的可读性和意图的明确性。封装默认行为:
R类在构造函数中预设了一些默认值,比如成功的状态码和消息。这意味着你在创建响应时,不需要每次都手动设置这些值。此外,R类还提供了如ok和error这样的静态方法,使得创建标准化响应更为便捷。便于扩展:如果将来需要为响应结构添加新的通用字段或方法,通过继承
HashMap的R类可以很容易地做到这一点。相比之下,如果直接使用HashMap,则需要修改使用HashMap的每个地方,这会增加维护成本。提高易用性:
R类可以定义一些辅助方法,比如链式调用的put方法,以及特定场景下的快捷方法(如error或ok),这样使用起来更加方便快捷。直接使用HashMap则无法享受到这些定制化的便利。减少错误:通过限制
R类的使用方式(例如,只能使用预定义的方法来设置状态码和消息),可以减少在构建响应时可能出现的错误。直接使用HashMap可能会导致键名的不一致或遗漏必要的字段。示例
假设你需要返回一个错误响应,如果使用
R类,可以简单地调用:return R.error("用户不存在");这行代码清晰明了,立即可知它的意图。相比之下,如果直接使用
HashMap,则需要编写更多的代码来实现同样的效果:Map<String, Object> response = new HashMap<>(); response.put("code", 400); response.put("msg", "用户不存在"); return response;这不仅仅增加了代码量,也降低了代码的可读性和一致性。因此,
R类作为HashMap的子类,提供了一种更高效、更易维护和更语义化的方式来构建和管理响应数据。
为什么
R可以是HashMap的子类?
HashMap是Java中的一个标准类,用于存储键值对集合。一个HashMap允许使用任何类型的对象作为键和值,这使得它成为实现灵活、动态数据结构的理想选择。在Web开发中,服务端经常需要向客户端返回复杂的数据结构,这些数据结构通常包括了操作结果的状态码、消息、数据内容等。
HashMap提供了一种方便的方式来组织这些信息,并且可以很容易地被转换为JSON格式,这是现代Web开发中常用的数据交换格式。这样做有什么好处?
灵活性:继承
HashMap让R类可以非常灵活地添加或删除数据。你可以随时向R对象中添加新的键值对,以传递更多的信息给客户端。简便的数据操作:
R类可以直接利用HashMap的所有方法和特性,例如,使用put方法添加额外的返回信息,或使用get方法读取信息。这减少了需要从头构建这些功能的必要性。易于转换为JSON:由于
HashMap可以直接被许多JSON库转换为JSON字符串,这使得R类非常适合用作Spring Boot等框架的控制器方法的返回类型,便于前后端数据交换。示例说明
考虑一个简单的场景:你需要返回一个操作成功的消息给客户端,并附带一些额外的数据。
使用
R类,你可以这样做:public R getUser() { User user = findUserById(1); // 假设这个方法返回一个用户对象 return R.ok().put("user", user); }这里,
R.ok()创建了一个预设为成功状态的R对象,然后通过put方法添加了一个名为"user"的键,值为user对象。这个R对象在返回给客户端之前,通常会被自动转换为JSON格式,类似于:{ "code": 0, "msg": "success", "user": { "id": 1, "name": "John Doe", // 其他用户属性 } }这种设计使得创建复杂的、结构化的返回信息变得非常简单和直观,同时保持了代码的清晰和易于维护。
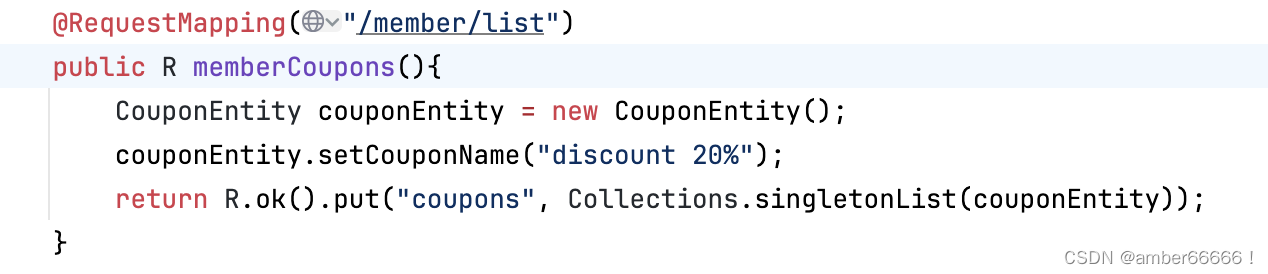
这个代码的含义
@RequestMapping("/member/list")
public R memberCoupons(){
CouponEntity couponEntity = new CouponEntity();
couponEntity.setCouponName("discount 20%");
return R.ok().put("coupons", Collections.singletonList(couponEntity));
}在你提供的代码片段中,
R类的使用之所以不需要显式实例化(即不需要使用new R()来创建对象),是因为R类中定义了若干静态方法(如ok和error),这些方法内部自己创建了R类的实例并返回。静态方法
静态方法属于类本身,而不是类的某个特定对象实例。因此,你可以直接通过类名来调用这些方法,而不需要创建类的实例。这就是为什么在
R.ok()调用中不需要实例化R类的原因。方法内部的实例化
当你调用
R.ok()时,这个方法内部实际上是这样实现的:public static R ok() { return new R(); }这个
ok方法创建了R的一个新实例,并返回这个实例。因此,即使外部调用时没有直接实例化R,实际上在ok方法内部已经完成了实例化。链式调用
返回的
R实例上还可以链式调用put方法来添加数据,如R.ok().put("coupons", Collections.singletonList(couponEntity))。这是因为put方法被设计为返回R实例本身(this),这样就可以继续在这个实例上调用其他方法。代码解释
@RequestMapping("/member/list") public R memberCoupons(){ CouponEntity couponEntity = new CouponEntity(); couponEntity.setCouponName("discount 20%"); return R.ok().put("coupons", Collections.singletonList(couponEntity)); }这段代码中,
R.ok()首先调用了R类的ok静态方法,创建并返回了一个成功状态的R实例。然后,调用put方法在这个实例上添加了一个键为"coupons"的数据,值是一个包含couponEntity的列表。最后,这个装载了数据的R实例被返回作为响应体。这种设计模式使得构建和返回自定义响应非常方便和高效,无需在每次返回响应时都显式创建
R的实例。
静态方法
非静态方法(实例方法)
非静态方法是指那些属于类的实例的方法。你需要创建一个类的对象,然后使用这个对象来调用这些方法。
public class Calculator { // 非静态方法:需要通过类的实例来调用 public int add(int a, int b) { return a + b; } }使用非静态方法的示例:
Calculator calculator = new Calculator(); // 创建Calculator类的一个实例 int sum = calculator.add(5, 3); // 使用实例调用非静态方法 System.out.println(sum); // 输出结果8静态方法
静态方法是属于类本身的方法,而不是类的某个对象的方法。你可以直接使用类名来调用静态方法,而不需要创建类的实例。
public class Calculator { // 静态方法:可以直接通过类名调用 public static int multiply(int a, int b) { return a * b; } }使用静态方法的示例:
int product = Calculator.multiply(5, 3); // 直接使用类名调用静态方法 System.out.println(product); // 输出结果15对比
**实例方法(非静态方法)**要求你必须先有一个类的对象,然后通过这个对象来调用方法。这些方法可以访问类的实例变量(非静态变量)和其他实例方法。
静态方法不需要类的对象就可以调用。它们不能直接访问类的实例变量或实例方法,因为它们属于类本身,而不是任何特定的对象实例。静态方法通常用于执行不依赖于对象状态的操作,或者提供一些通用的功能,如工具方法或辅助方法。
总结来说,静态方法与非静态方法的主要区别在于是否需要类的实例来调用它们,以及它们能否直接访问类的实例变量和其他实例方法。
一些静态方法的例子
当然可以。静态方法通常用于实现不依赖于对象状态的功能,下面是一些常见的静态方法示例:
1. 工具类方法
Java标准库中的
Math类是一个典型的包含静态方法的工具类,提供了广泛的数学函数和常量。double result = Math.sqrt(16); // 调用Math类的静态方法sqrt计算16的平方根 System.out.println(result); // 输出结果4.02. 工厂方法
工厂方法是一种创建对象的设计模式,这些方法会返回一个类的新实例。它们通常是静态的,因为工厂方法的目的是创建对象,而不依赖于任何已存在的对象实例。
public class CalendarFactory { // 静态工厂方法:根据给定的类型创建并返回不同的日历对象 public static Calendar getCalendar(String type) { if ("Gregorian".equals(type)) { return new GregorianCalendar(); } else if ("Buddhist".equals(type)) { return new BuddhistCalendar(); } return null; } }使用工厂方法的示例:
Calendar calendar = CalendarFactory.getCalendar("Gregorian");3. 辅助方法
静态方法常用于实现辅助功能,比如验证输入、转换数据格式等。
public class StringUtils { // 静态方法:检查一个字符串是否为空或null public static boolean isEmpty(String str) { return str == null || str.isEmpty(); } }使用辅助方法的示例:
boolean isEmpty = StringUtils.isEmpty(""); // true4. 单例获取方法
在实现单例模式(类设计为只能有一个实例的设计模式)时,获取这个唯一实例的方法通常定义为静态的。
public class Singleton { private static Singleton instance = new Singleton(); private Singleton() {} // 私有构造函数 // 静态方法:返回Singleton的唯一实例 public static Singleton getInstance() { return instance; } }获取单例对象的示例:
Singleton singleton = Singleton.getInstance();这些例子展示了静态方法的多种用途,包括提供数学计算、创建对象、实现辅助功能以及实现设计模式等。静态方法由于其独立于任何对象实例的特性,非常适合执行这些不需要对象状态的操作。
第23天
nacos作为配置中心,统一管理配置
1.引入依赖
2.创建一个boorstrap.properties(中心名字和地址)
3.配置中心默认添加(当前应用名.properties),给这些(在网页上)添加所有配置
4.在想在网页上获得请求的上面加@RefreshScope,以及@Value的值
如果配置中心和本地文件中的都有该配置,优先使用配置中心的配置

第24、25天
第26天 网关
网关帮我们路由到各个服务



路由 : ID url 断言的集合 过滤器 - 只要匹配了断言为真 就可以路由过去
predicat - 断言 - 判断 - 去匹配当次请求的任何消息
filter - 请求过来与过去都要过滤
请求到网关 - 断言- 判断是不是符合一个路由规则 - 路由到指定位置 - 如果符合 - 就过filter - 过去

跳到qq的hello地址。

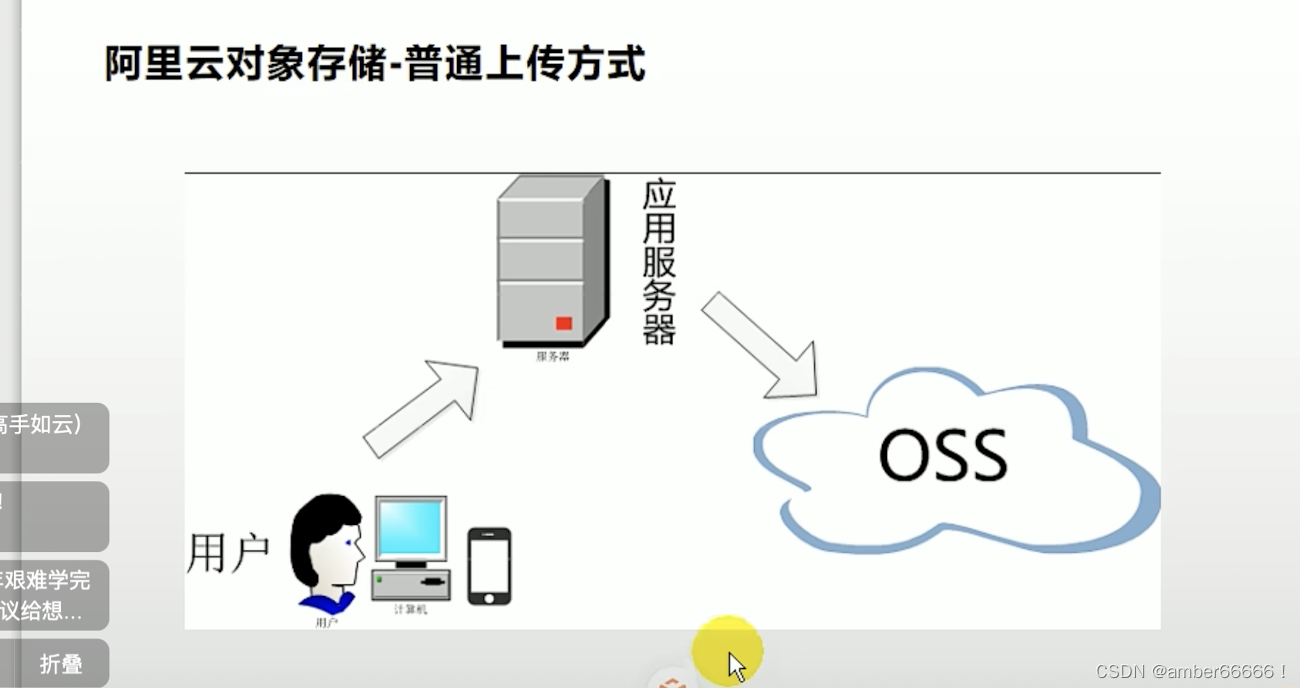
61、62、63 文件上传功能
在分布式的情况下,系统会把文件分发到各个服务下面(因为负载均衡),因此有的服务下面仅有一些文件,为了让所有服务都可以访问到文件,出现了该文件上传功能。统一存储在文件存储服务器内,统一读写。云存储是比较优惠的一种方式。



可以上传一些文件的话,就需要秘钥
bucket - 存储空间
在阿里云上创建

是否需要账号密码


复制改地址即可
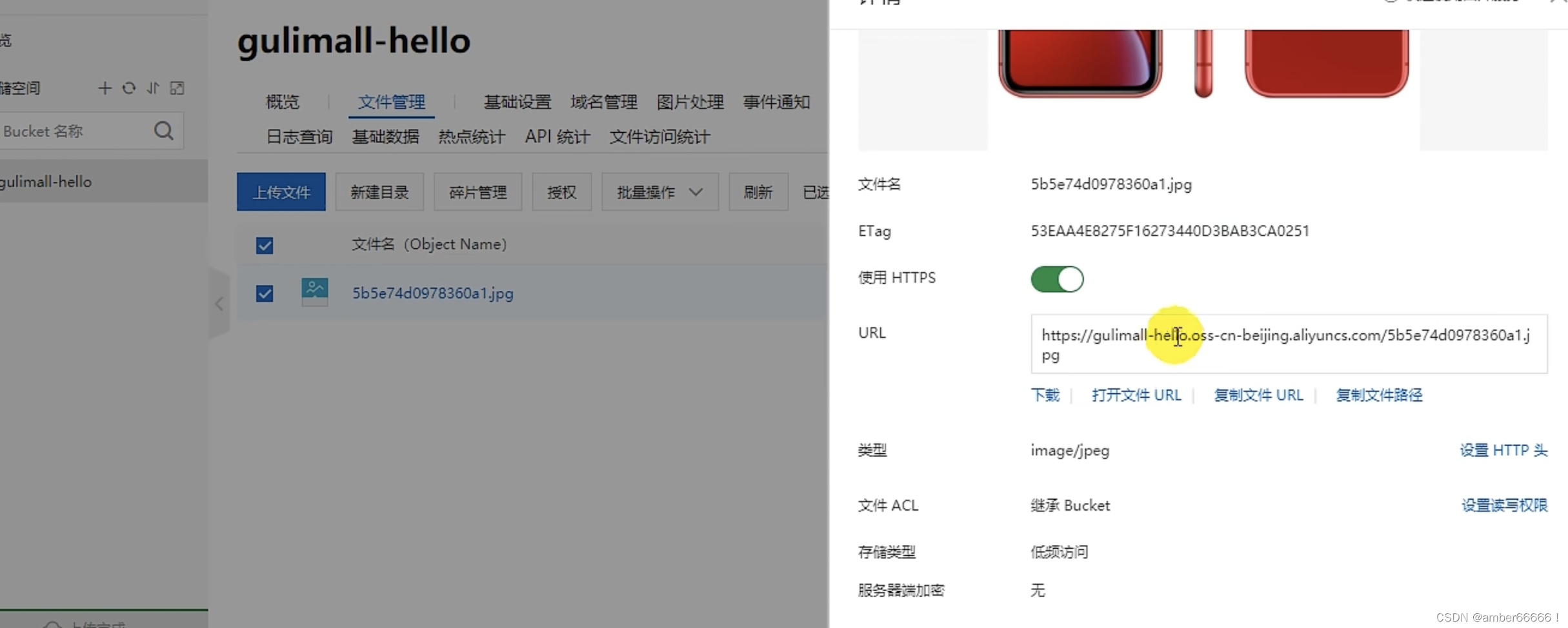
相较于OSS直接验证账号密码,反而验证阿里云的签名可能是更有效的一种方式
先找服务器要防伪的签名
上传文件的代码(简谱版)

引入starter后,只需要在文件里配置一下就可以了

实例化一个实例就可以了

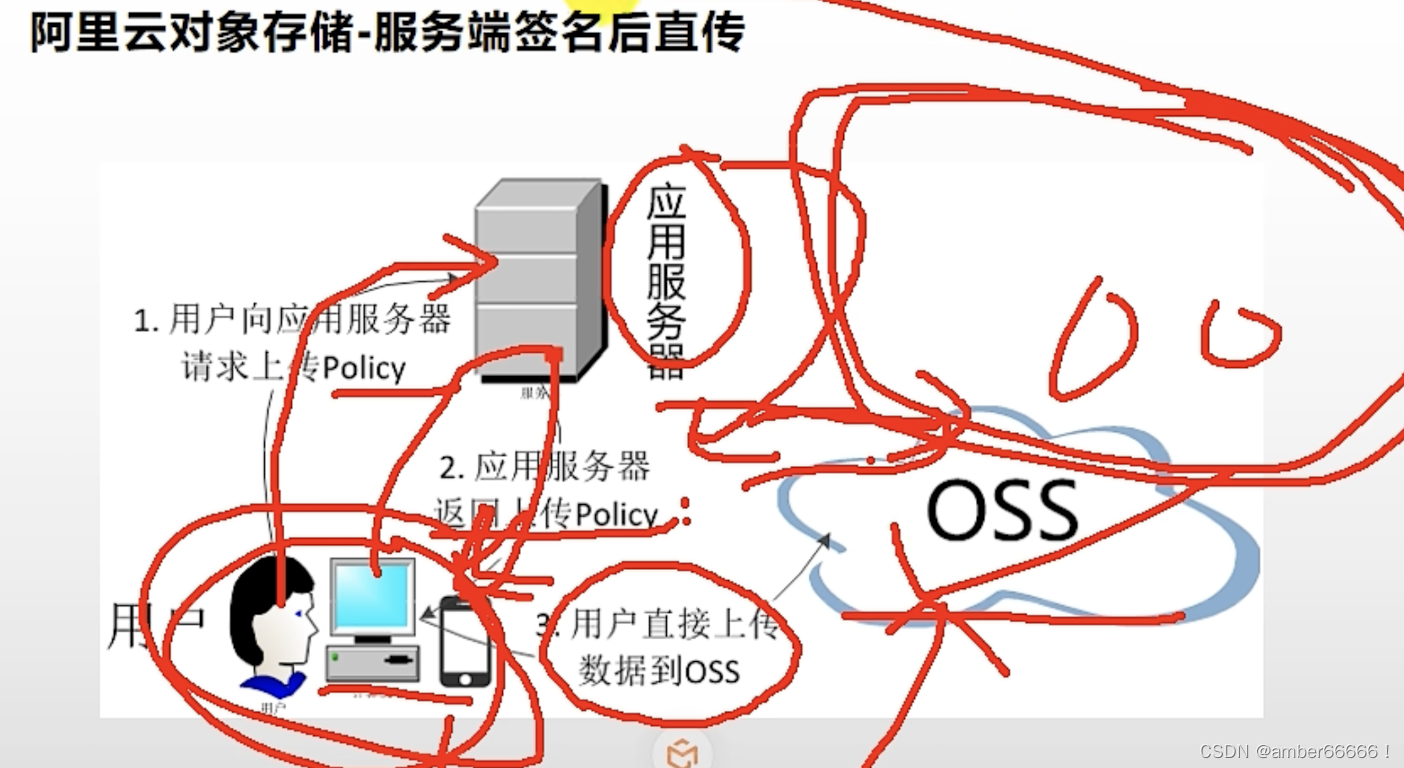
服务端签名后直传
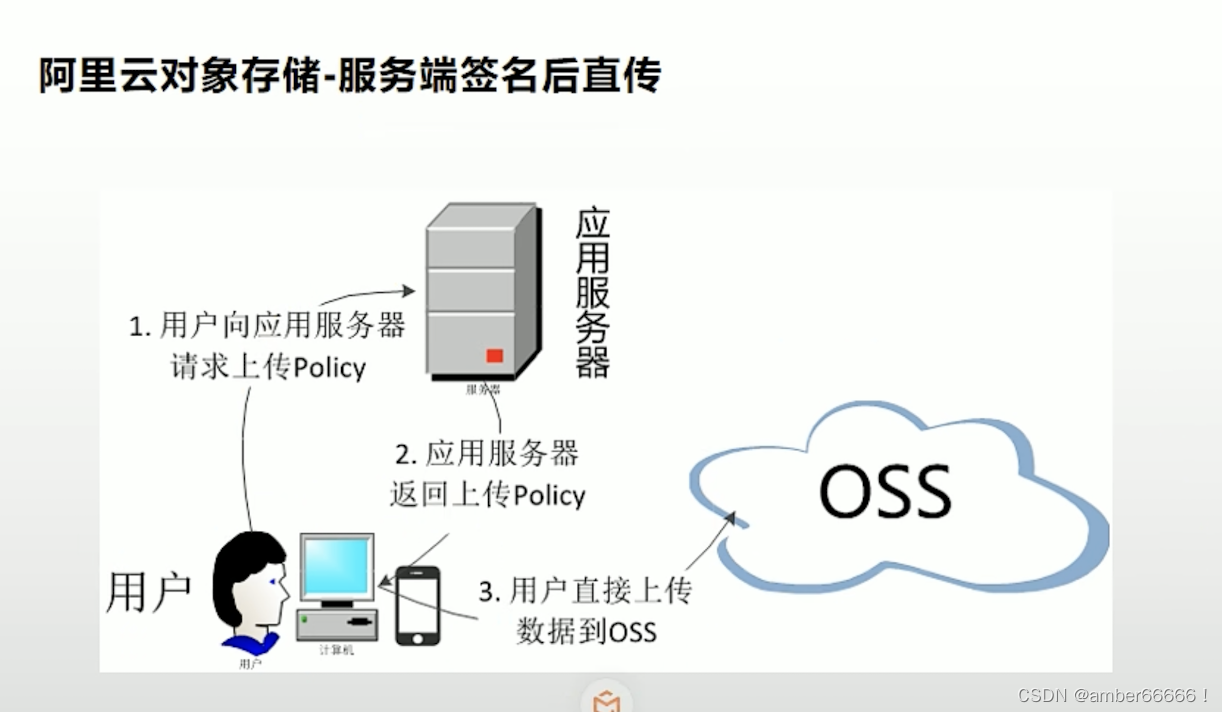
66 校验 - 出了什么错误
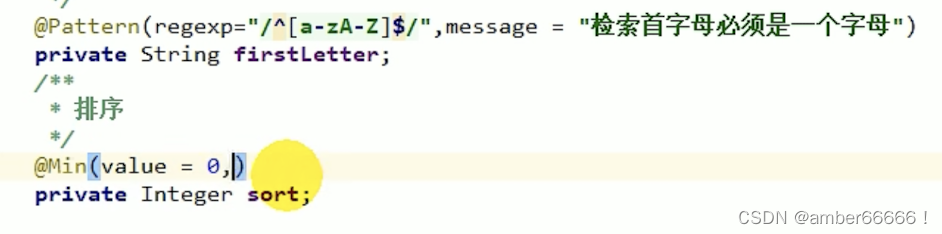
校验注解 - JSR303 - 是一个校验规范
control和entity下面的包都要有notblank和valid


默认的message是这个内容

在后面紧跟result

这个代码的含义

当然,我来用一个简单的例子来解释
@ExceptionHandler注解的用途和工作方式。假设你正在开发一个Spring Boot Web应用程序,并且你有一个控制器类用于处理用户请求。在处理请求的过程中,可能会遇到各种异常。比如,一个常见的场景是用户请求的数据找不到。在这种情况下,你可能想返回一个“404 Not Found”错误给用户。这就是
@ExceptionHandler注解可以帮助你的地方。@Controller public class MyController { @GetMapping("/user/{id}") public String getUserById(@PathVariable String id) { // 假设这个方法可能会抛出一个UserNotFoundException // 你的逻辑代码... throw new UserNotFoundException("用户找不到"); } @ExceptionHandler(UserNotFoundException.class) public ResponseEntity<String> handleUserNotFound(UserNotFoundException e) { // 当getUserById方法抛出UserNotFoundException异常时,这个方法会被调用 // 这里你可以定义返回给用户的错误信息和HTTP状态码 return new ResponseEntity<>(e.getMessage(), HttpStatus.NOT_FOUND); } }在这个例子中,
getUserById方法是用来根据ID获取用户信息的。我们假设如果用户找不到,这个方法会抛出一个自定义的异常UserNotFoundException。通过在同一个控制器类中添加一个用@ExceptionHandler(UserNotFoundException.class)注解的方法,我们告诉Spring,如果getUserById方法抛出UserNotFoundException异常,就调用handleUserNotFound方法来处理这个异常。
handleUserNotFound方法接收一个UserNotFoundException实例作为参数,这样它就可以访问异常中的详细信息(比如一个错误消息)。然后,它返回一个ResponseEntity对象,这个对象包含了错误消息和HTTP状态码(在这个例子中是404 Not Found)。这样,你就可以在遇到特定异常时提供更加友好和详细的错误信息给用户,同时保持你的控制器代码整洁和易于管理。
统一的异常处理类

docker是什么
Docker 是一个开源的平台,用于自动化软件的部署、扩展和管理。它通过使用容器来允许应用程序与系统基础架构分离,从而实现快速、一致和可靠的软件交付。
容器是轻量级的、可执行的软件包,包含软件运行所需的一切:代码、运行时、系统工具、系统库等。由于容器与基础设施和操作系统解耦,它们在不同的环境中都能以相同的方式运行。这意味着您可以在开发环境中构建容器,然后将其无缝迁移到测试和生产环境,无论后者的设置如何。
Docker 提供了一个统一的接口来管理这些容器,包括构建、分发和运行容器。这简化了开发流程,因为开发者可以专注于应用程序本身,而不是底层基础设施。
Docker 还提供了 Docker Hub,一个用于分享和管理容器镜像的平台。镜像是创建 Docker 容器的模板。用户可以从 Docker Hub 下载镜像来部署和运行应用程序,也可以上传自己创建的镜像供他人使用。
总之,Docker 通过其容器技术和服务,极大地简化了软件的开发、测试、部署和运维过程。
老师的方法是在linux上的,但是我的电脑是mac,所以不太适用
mac安装elasticSearch 和 kibana
参考指南,基本上是全的,补充
Elasticsearch基于Mac的安装指南-腾讯云开发者社区-腾讯云
这个是下载elasticsearch
Install Elasticsearch from archive on Linux or MacOS | Elasticsearch Guide [8.12] | Elastic
这个是 kibana,自己下载下来就好
Download Kibana Free | Get Started Now | Elastic

最后安装成功

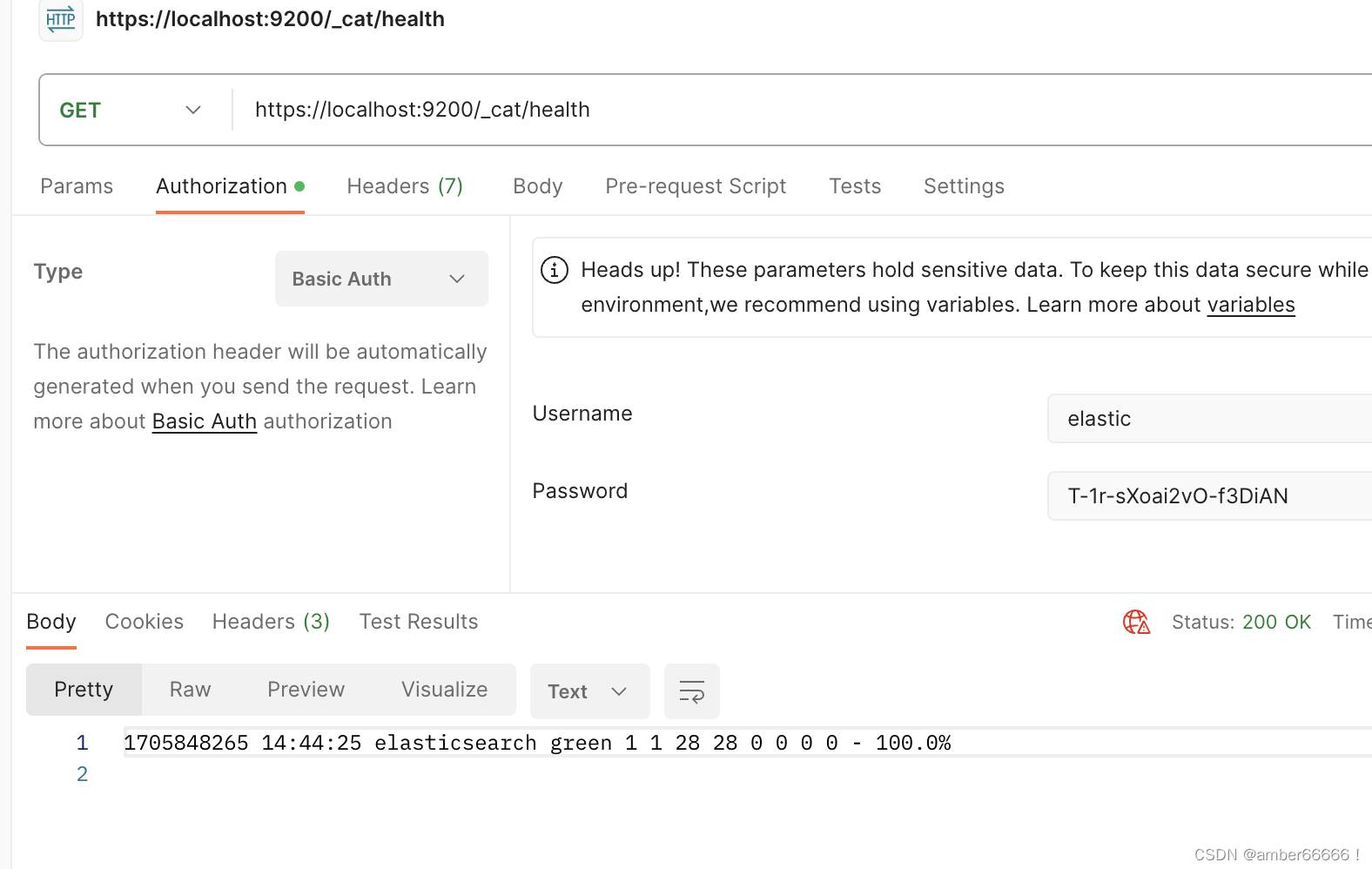
查看elasticserch的信息命令

使用postman发送请求
除了老师说的内容,我一开始的发送被拒绝了,需要加上这里的信息才可以
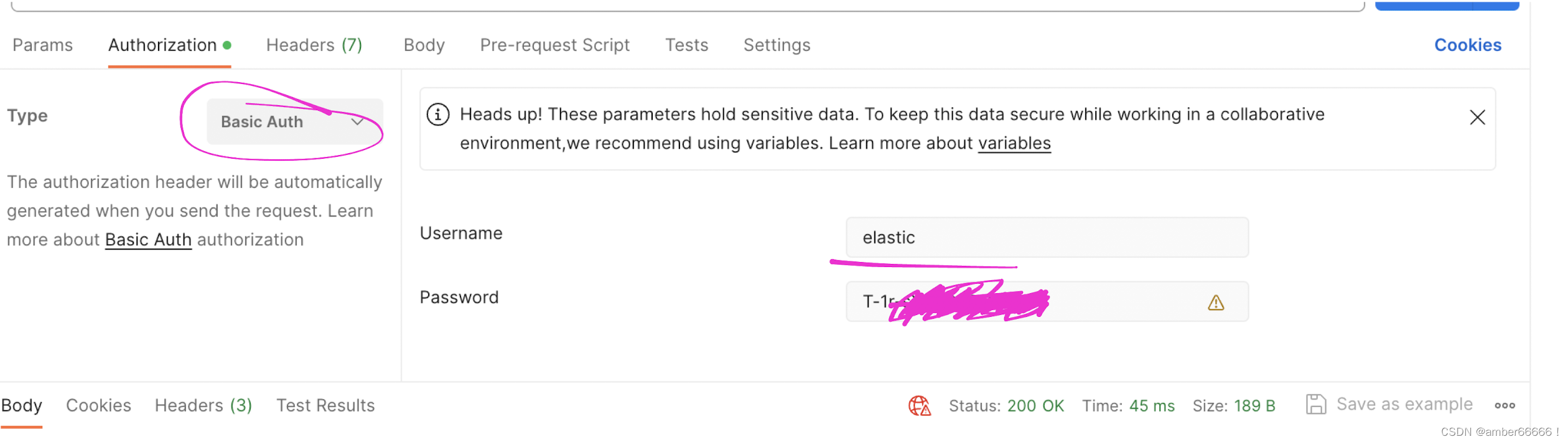
而后成功启动
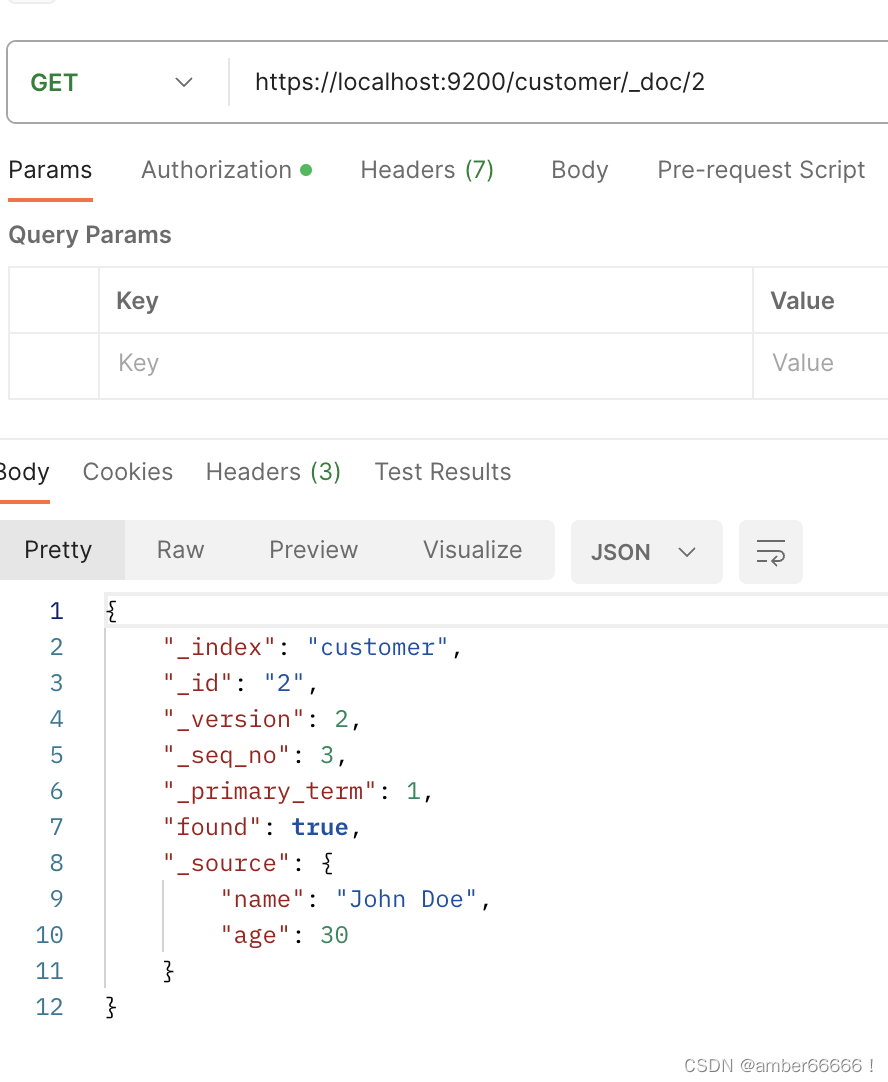
要加_doc,put和post的区别是,前者必须带id,后者是带不带都可以,如果id重复,则状态会变为update

这里一定要有一个_doc,不知道是为什么


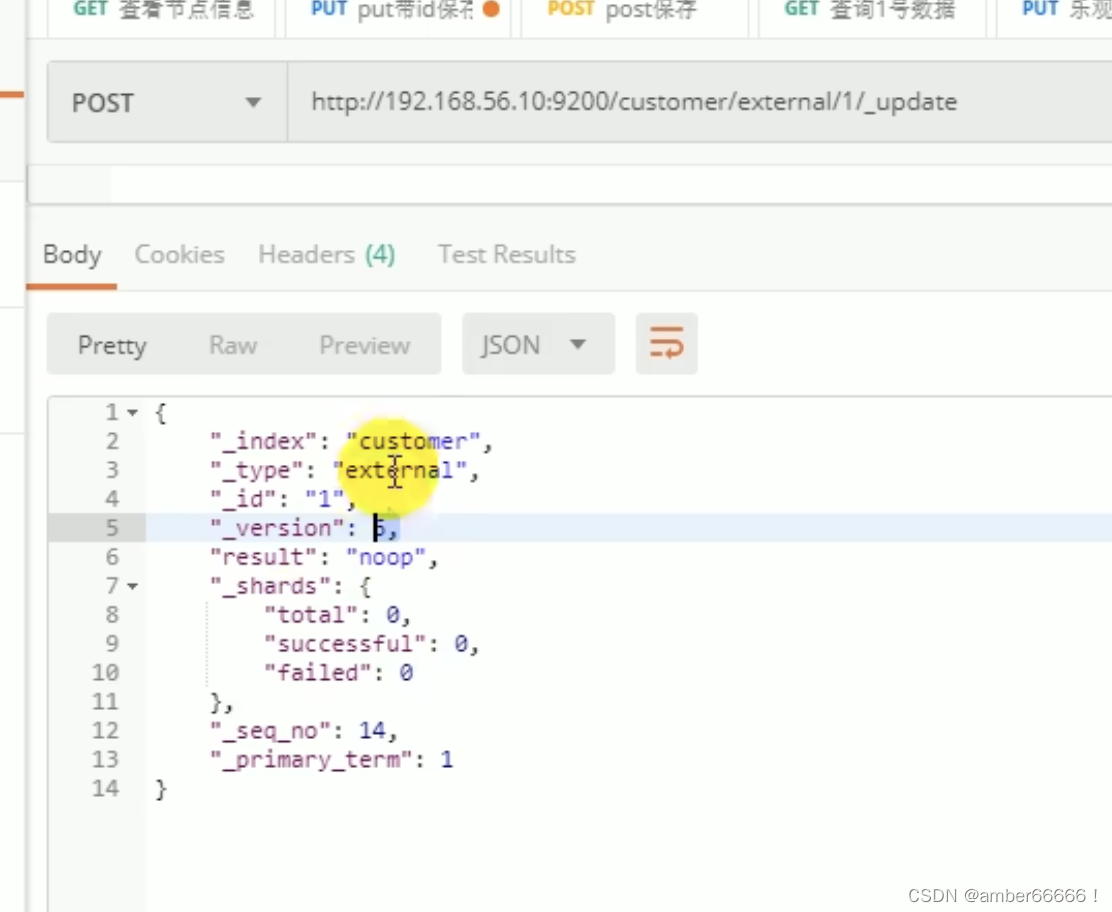
更新
- noop - 没有任何操作,如果两次update的数据没有改变 ,seq_no也不会变。(会对比原来数据)
- doc 要与 update绑定到一起
- 如果不带update,就不会比较前数据。
- 只有post带update请求,才会检查与原来是否一样。
- post+ update 或者 put/post ➕不带update 可以增加原来没有的属性

删除
- 也可以直接删除索引(数据库),但是不可以直接删除类型

在较新的 Elasticsearch 版本(7.x 及更高版本)中,类型已经被废弃了,文档都存储在索引中而不再有类型。因此,不再需要指定类型。如果您仍然在使用 Elasticsearch 6.x 或更早的版本,以下是如何为索引添加类型的步骤:
前者不对,后者才对。。。。
在新版本中,文档直接存储在索引中的 _doc 类型下。
因此,根据您所使用的 Elasticsearch 版本,可以确定是否需要指定类型,并按照上述相应版本的示例操作。如果您使用的是较新的版本(7.x 或更高版本),则不再需要指定类型,只需关注索引名称和文档内容。

bulk api以此按顺序执行所有的action(动作)。如果一个单个的动作因任何原因失败,它将继续处理它后面剩余的动作。当bulk api返回时,它将提供每个动作的状态(与发送的顺序相同),所以您可以检查是否一个指定的动作是否失败了。

记得改branch,否则找不到
match
match_phrase
使用match的keyword
"match": {
"address": "kings"
}
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill road"
}
}
}
GET bank/_search
{
"query": {
"match": {
"address.keyword": "990 Mill"
}
}
}
文本字段的匹配,使用keyword,匹配的条件就是要显示字段的全部值,要进行精确匹配的。
match_phrase是做短语匹配,只要文本中包含匹配条件,就能匹配到。
检索方式
jvm内存模型
编译class - 类装载区
调内存都是调堆
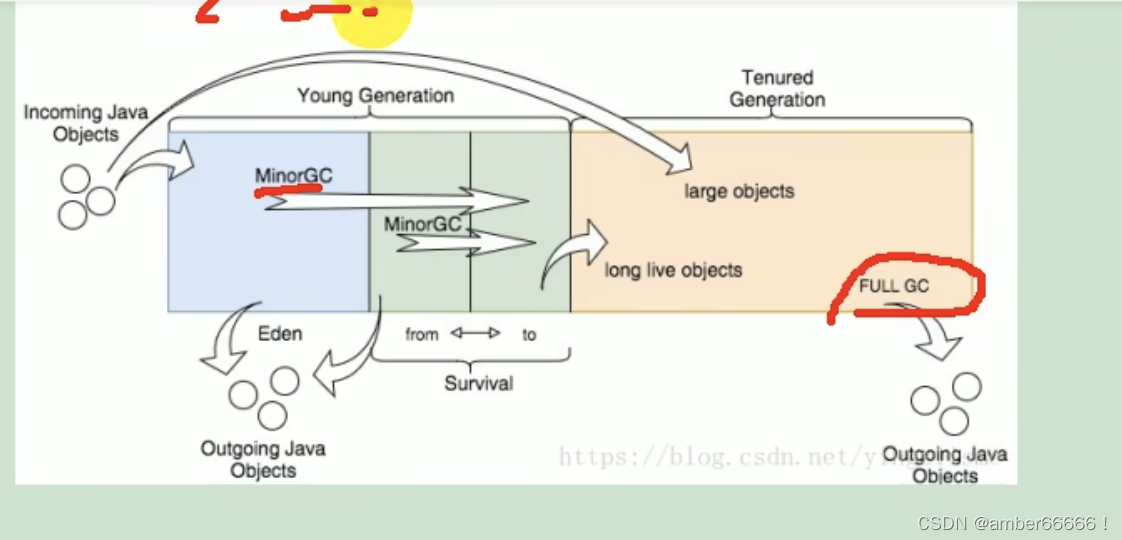
垃圾回收机制
在垃圾回收机制(Garbage Collection, GC)中,“GC”指的是一种自动内存管理机制。在编程语言和环境中,GC的主要作用是自动追踪内存分配和使用,以便发现那些不再被程序使用的内存区域,并释放这些区域以供重新使用。这样做的主要目的是减少内存泄漏和提高程序的内存效率。


jconsole来监控

一定要避免频繁的进行full GC
全链路为 800 88 310
150 Redis
Redis和数据库之间的关系可以看作是补充而非替代。通常,数据库用来长期存储数据,而Redis作为缓存系统,用来临时存储频繁访问的数据以提高访问速度和减轻数据库的压力。将数据存储在Redis中并不意味着就不需要在数据库中存储了。实际上,数据应该同时存储在数据库中以确保数据的持久性,而将经常或近期会被访问的数据副本存储在Redis中以提高性能。
Redis和数据库的关系简化说明:
- 数据库(如MySQL, PostgreSQL等):用于持久存储数据。所有的数据变更(增、删、改)首先在数据库中进行,以确保数据的安全和一致性。
- Redis:作为内存数据库,主要用于缓存数据。它存储的是数据库中数据的副本,目的是为了快速读取,减少对实际数据库的直接查询次数,从而提高应用的响应速度和降低数据库的负载。
简单例子解释:
假设你有一个在线商城应用,用户在浏览商品分类时,每次都从数据库查询分类信息,这在用户量大时会导致数据库压力增大。为了解决这个问题,可以使用Redis作为缓存来存储这些分类信息。
- 首次查询:当用户第一次请求分类信息时,应用会从数据库中查询这些信息,然后把它们存储到Redis中,并返回给用户。
- 后续查询:当另一个用户请求同样的分类信息时,应用首先会检查Redis中是否有这些信息的缓存,如果有,直接从Redis中读取并返回给用户,而不需要再次查询数据库。
- 数据更新:如果后台管理更新了分类信息,应用除了更新数据库中的信息外,还需要更新Redis中的缓存数据,以保持缓存的数据是最新的。
关键点:
- 数据一致性:需要保证Redis缓存的数据与数据库中的数据一致。当数据库数据更新时,相应的Redis缓存也需要更新。
- 数据持久性:重要的数据应该存储在数据库中,因为Redis是内存数据库,虽然它有一定的数据持久化功能,但主要还是作为临时缓存来使用。
- 性能优化:使用Redis可以显著提高应用的响应速度和扩展能力,尤其是对于读密集型的应用场景。
总结来说,Redis作为缓存层来加速数据的读取,而数据库则负责数据的持久存储和复杂查询,两者共同工作以提高应用的性能和用户体验。
什么叫:当用户第一次请求分类信息时
“当用户第一次请求分类信息时”这句话的意思是,在用户与应用交互过程中,用户进行了一个操作(如点击一个链接、按钮或进行了某种搜索操作等),试图获取某类商品或内容的分类信息的那一刻。这里的“第一次请求”强调的是在一系列可能的请求中的首次操作,目的是获取应用中存储的关于商品或内容的分类结构信息。
在Web应用或移动应用的上下文中,这通常意味着:
- 用户打开应用或网站,并且寻找特定种类的商品或内容。
- 用户选择或点击导航到特定的分类页面,比如“电子产品”、“图书”等。
- 应用接收到这个请求,并且需要从存储系统中(一开始是数据库)检索出相关的分类数据。
- 如果是应用中用户首次进行这种查询,且之前没有缓存这类信息,那么应用会从数据库中查询出这些信息,并可能将其存储在Redis等缓存系统中,以便后续快速访问。
这个过程中的“第一次请求”是相对于这个特定数据或信息而言的,它标志着从数据库到缓存的一个重要转变点:一旦数据被缓存,后续的相同请求就可以直接从缓存中获取数据,而不需要再次访问数据库,从而加快了数据的检索速度,提高了用户体验。
151 缓存

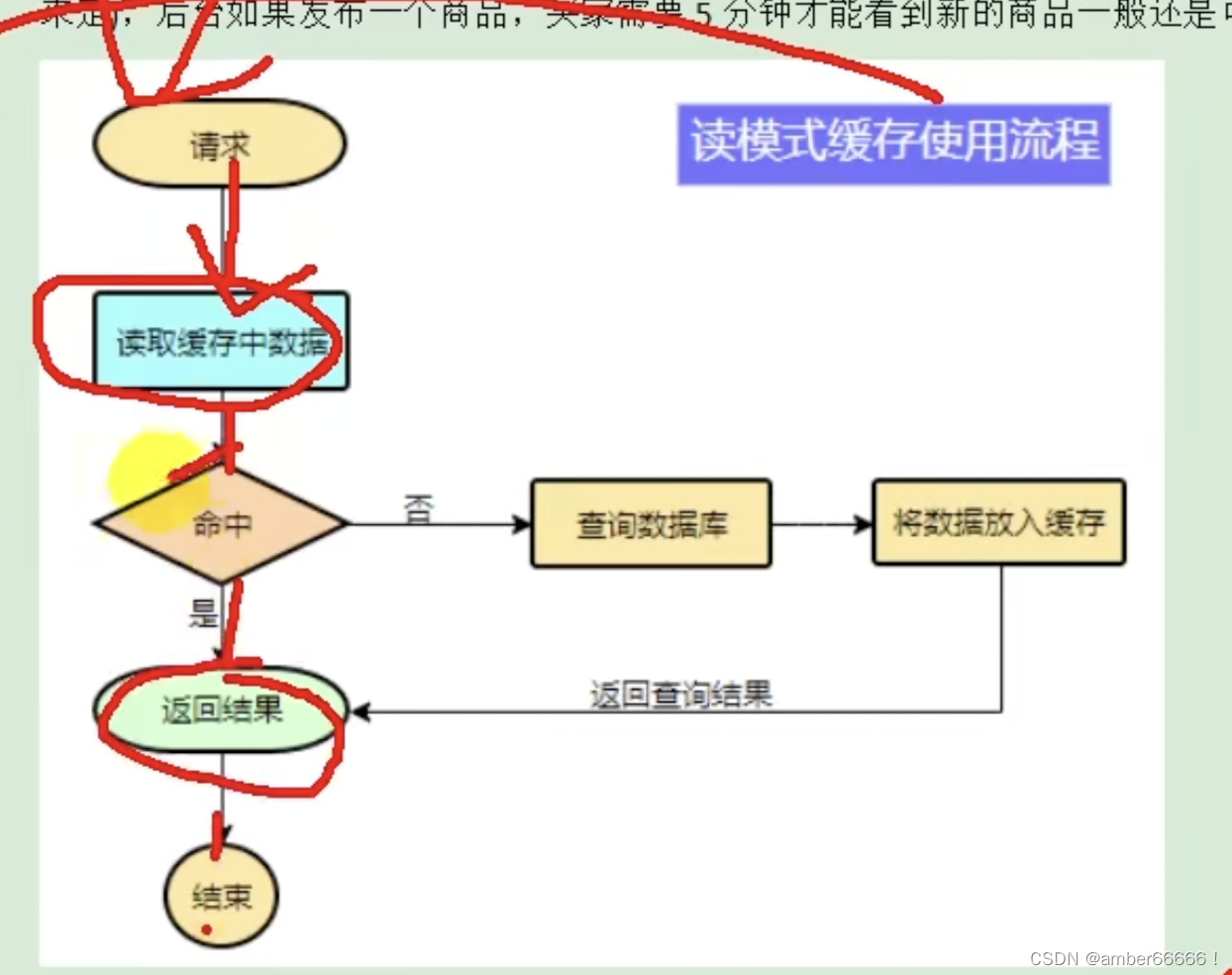
本地缓存的问题 - 缓存的修改问题,不一致
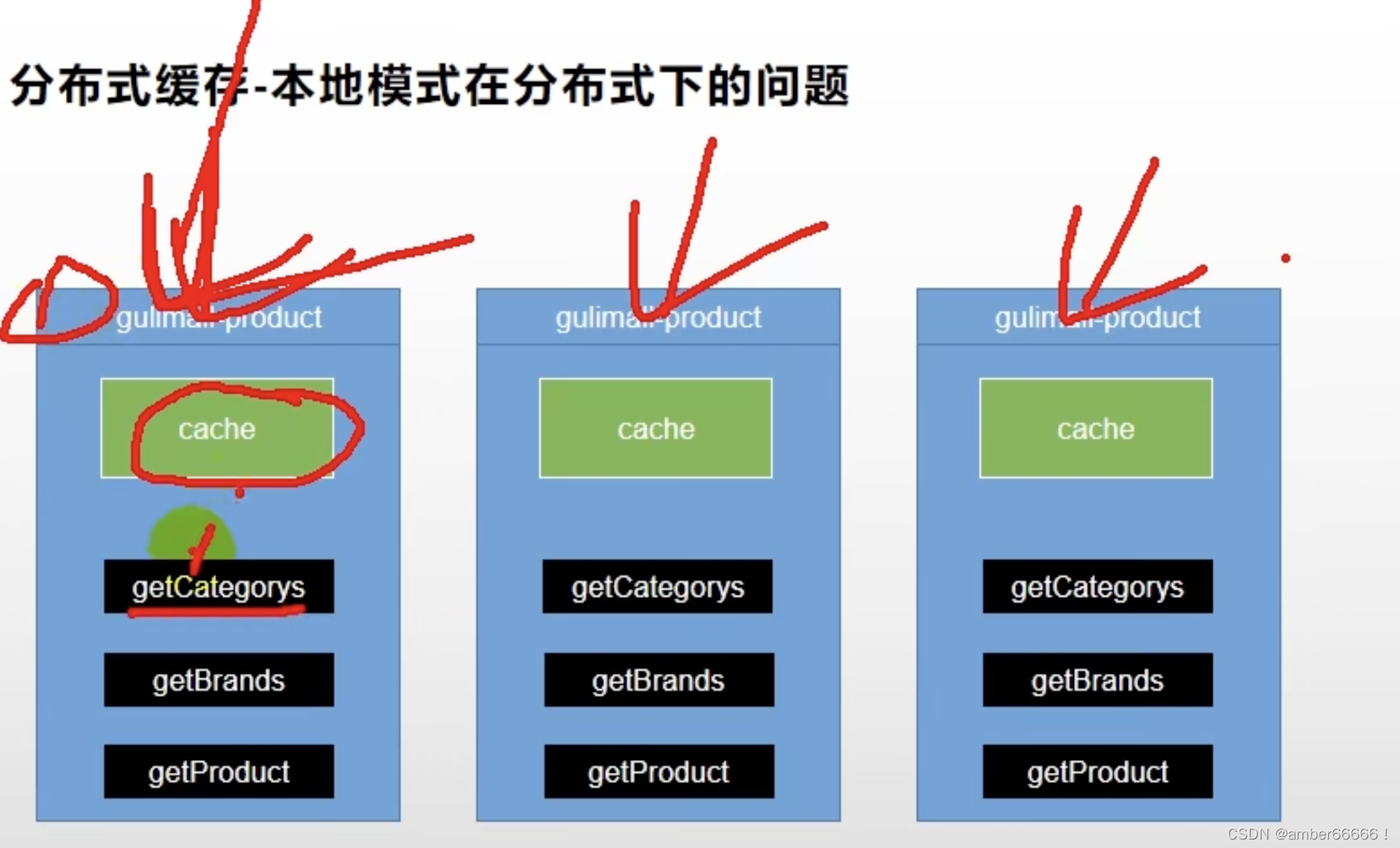
在分布式的情况下,应该使用 - 集中的使用缓存的中间件
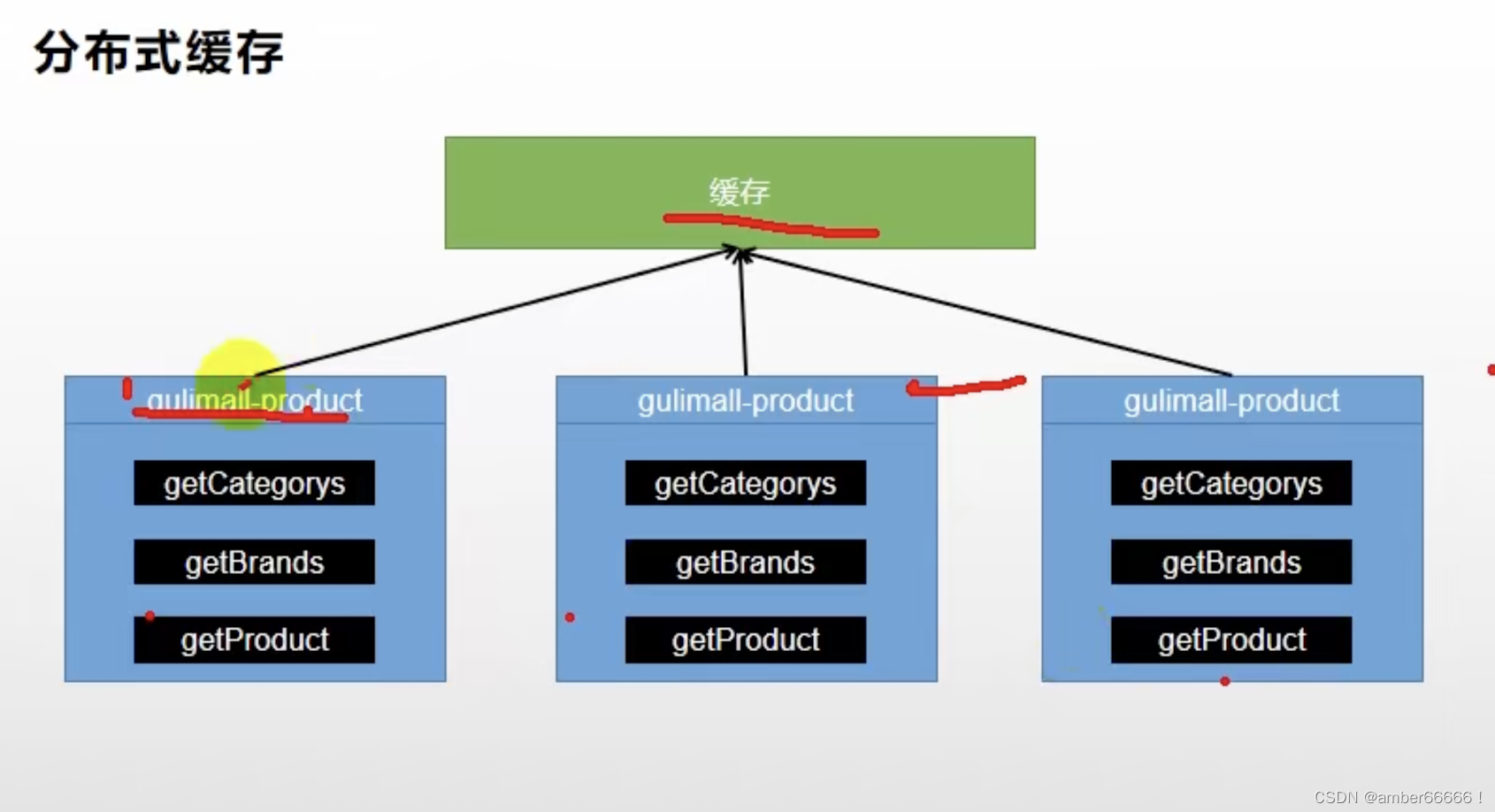
152 - 160 整合redis 

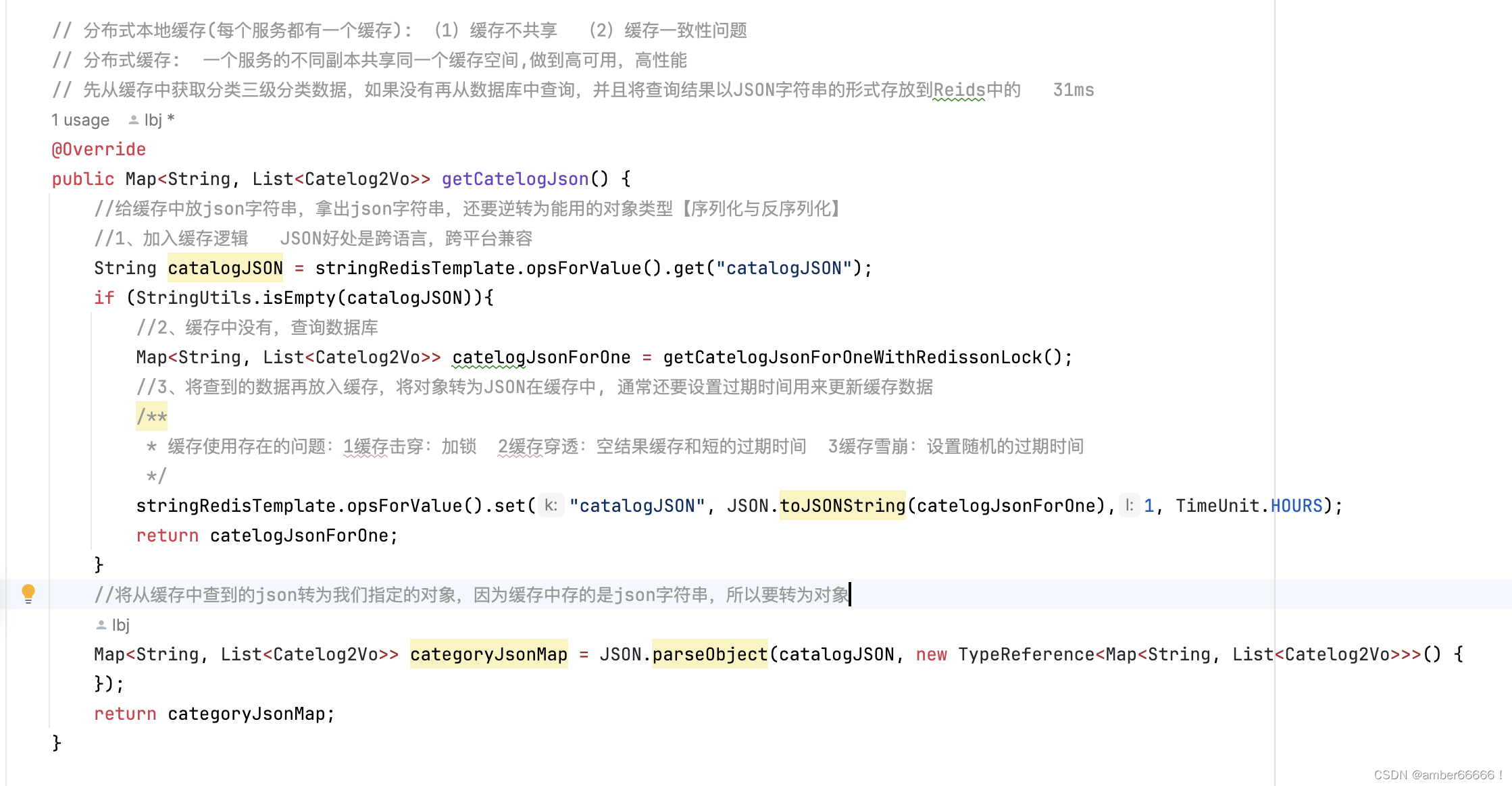 产生对外内存溢出的异常
产生对外内存溢出的异常
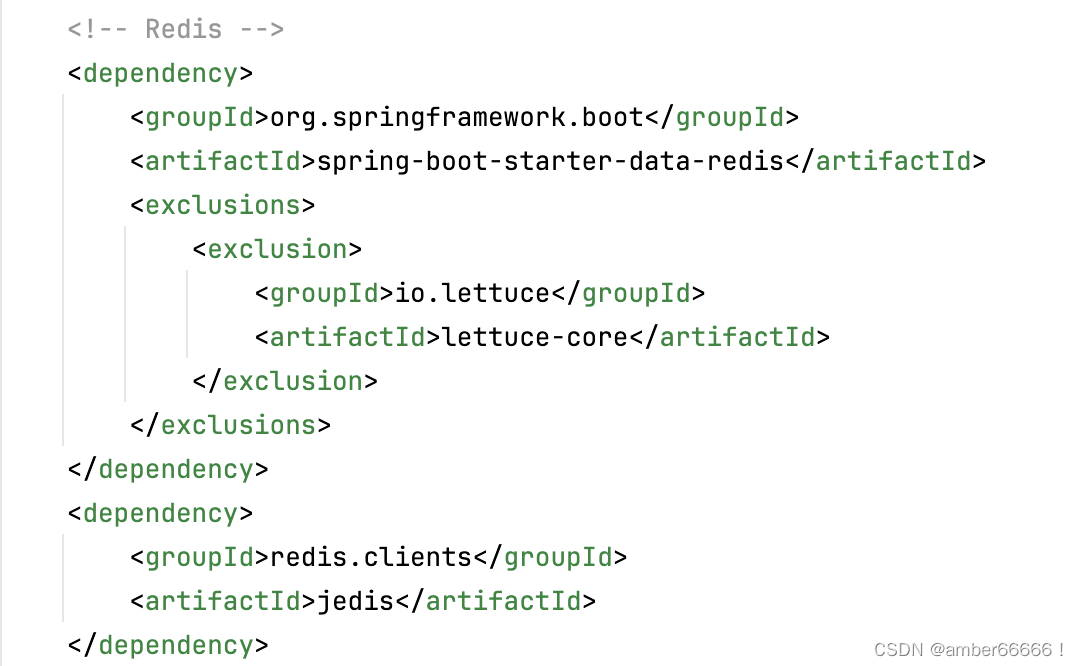
lettuce - 》netty 网络通信



因此修改更换一下

缓存穿透
如果本来就没有10000号商品,这个时候会反复去数据库查,会导致崩溃。
因为没有将空结果写入缓存。
解决 - 把null进行缓存,可以给空结果加一个过期时间,过了这个时间就不在缓存里存在了

指的是所有的存来的数据大面积失效 - 因此去反复请求数据库导致崩溃

一下大面积查询同一内容 - 这个在写代码的时候是不太好解决的

加锁的技术 - 如果是分布式的话,就不太可以了,分布式中this是指当前实例,一个项目一个容器,因此就有多个实例,每一个this都是不同的锁。本地锁也是可以的,



为什么会查询两次数据库 - 因为第一次放入缓存其实需要一定的时间,这个时候锁还释放了但是缓存中还暂时查不到数据,所以导致有两次查询数据库

更改为 - 等把数据放入redis之后再释放锁就可以了

在分布式的情况下 - 有几个分布式的组件就有几个锁 - 同时这些锁还同时会查数据库,本地🔐只能锁自己的,因此需要加一个分布式锁
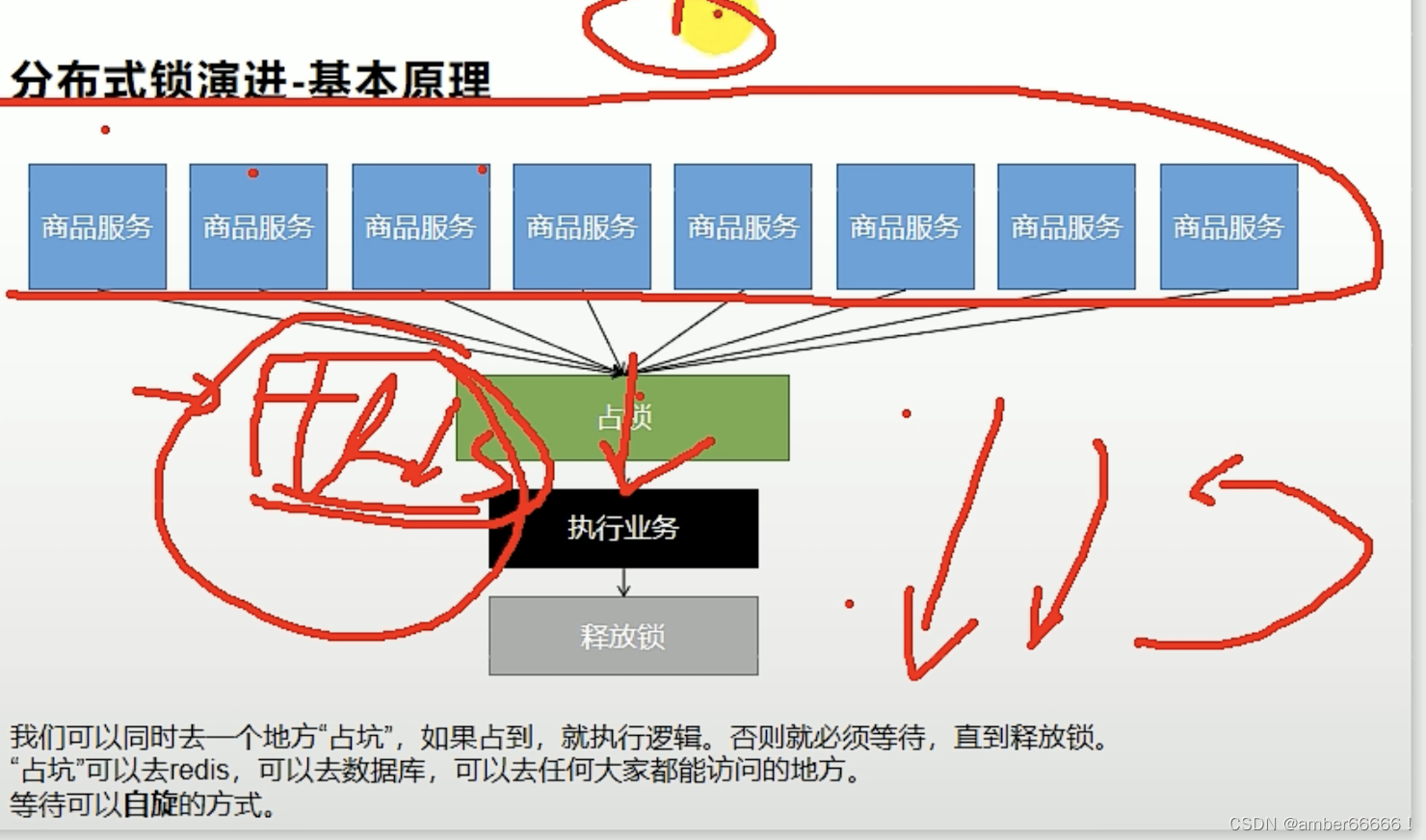
都去一个公共的地方占锁

不存在才放入,可以发现有的进程没有抢到这个lock

一个key和一个value


这里是指在redis中都没有(已经查过了)
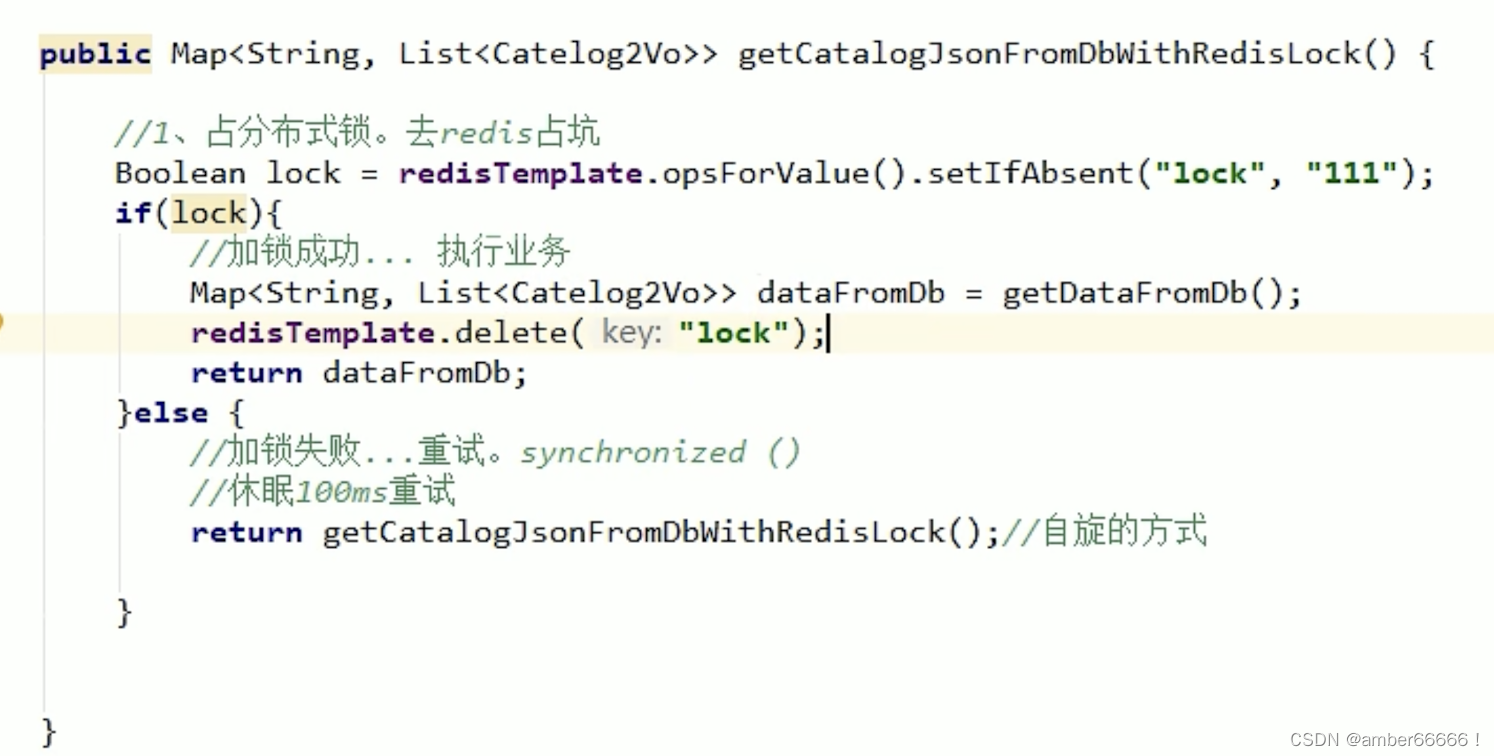
出现的问题
死锁 - 在getdatafromsb中出现了异常,在准备执行删锁的时候但没有成功删除
解决办法 - 给锁设置自动过期时间 - 即便没有删除 - 但是会自动删除锁

还有的问题 - 如果过期时间代码没有执行
解决办法 - 把加锁和设置过期时间是一个原子操作 - 过期时间是300ms


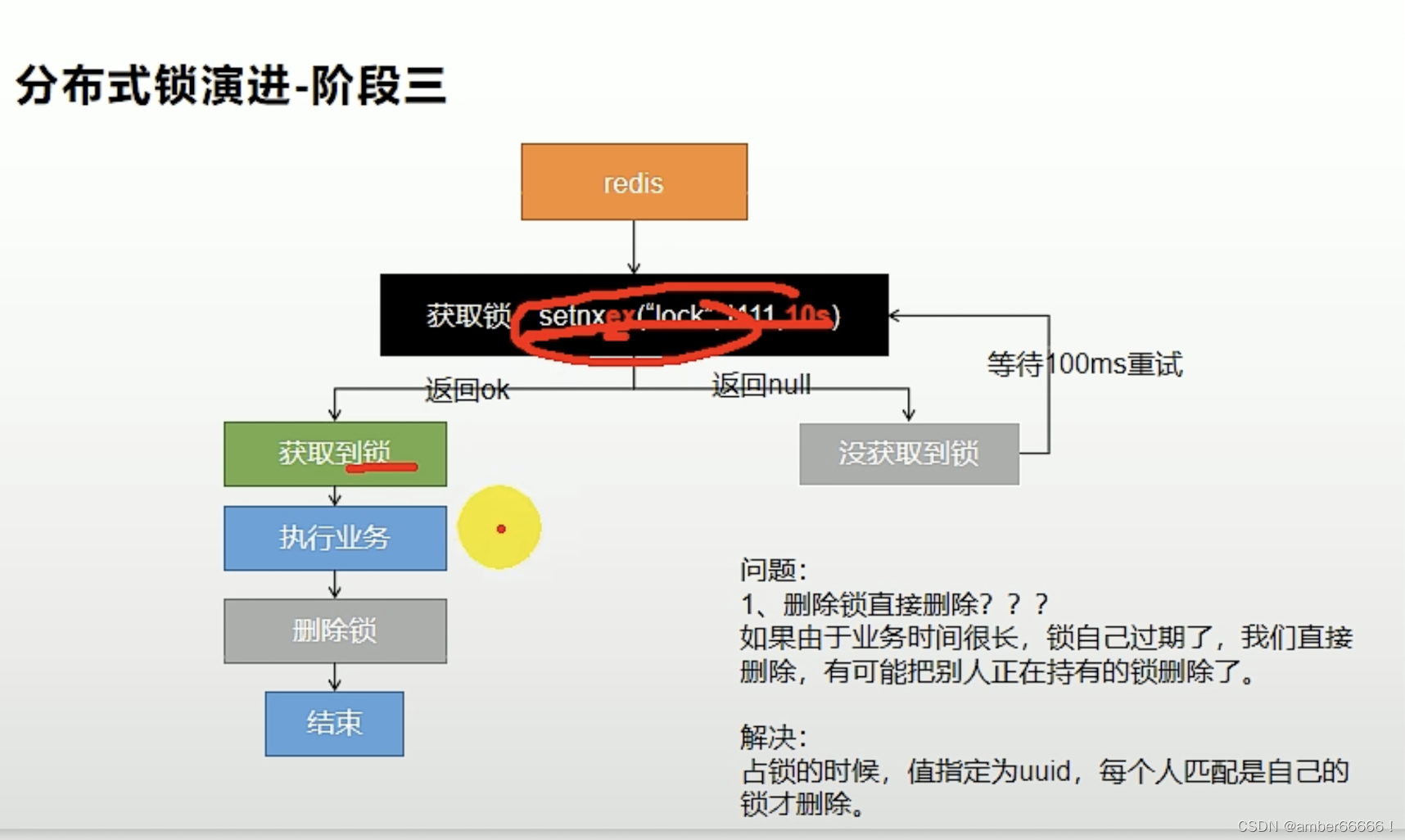
删除了别人的锁

拿到的lockvalue是原先的锁的uuid,但是后来突然过期了,那么删除的正好的就是别人的锁了。

使用luna脚本

执行业务逻辑,无论怎么样,都解锁了反正


写redission的config


写完之后立马来测试一下,使用test来测试,某种程度上也确保了程序的准确性,很神奇,果然代码要结合到实际才可以明白他的作用,自己写test总是不知道意义是什么,但在一个如此庞大的项目中使用test就显得十分有必要了。

可重入锁 - 所有的锁都应该设计为可重入锁,从而避免死锁问题
使用try,final的原因是业务代码可能出现问题,无论出不出现问题,都要进行解锁操作。

完整版 - 如果等不到锁,会阻塞式等待
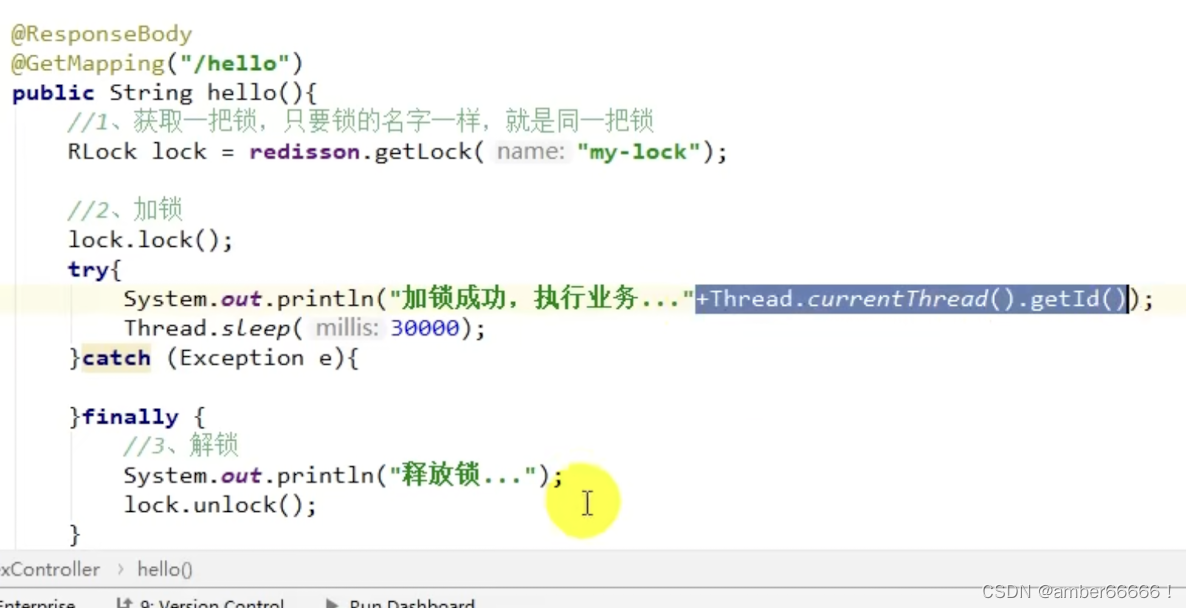
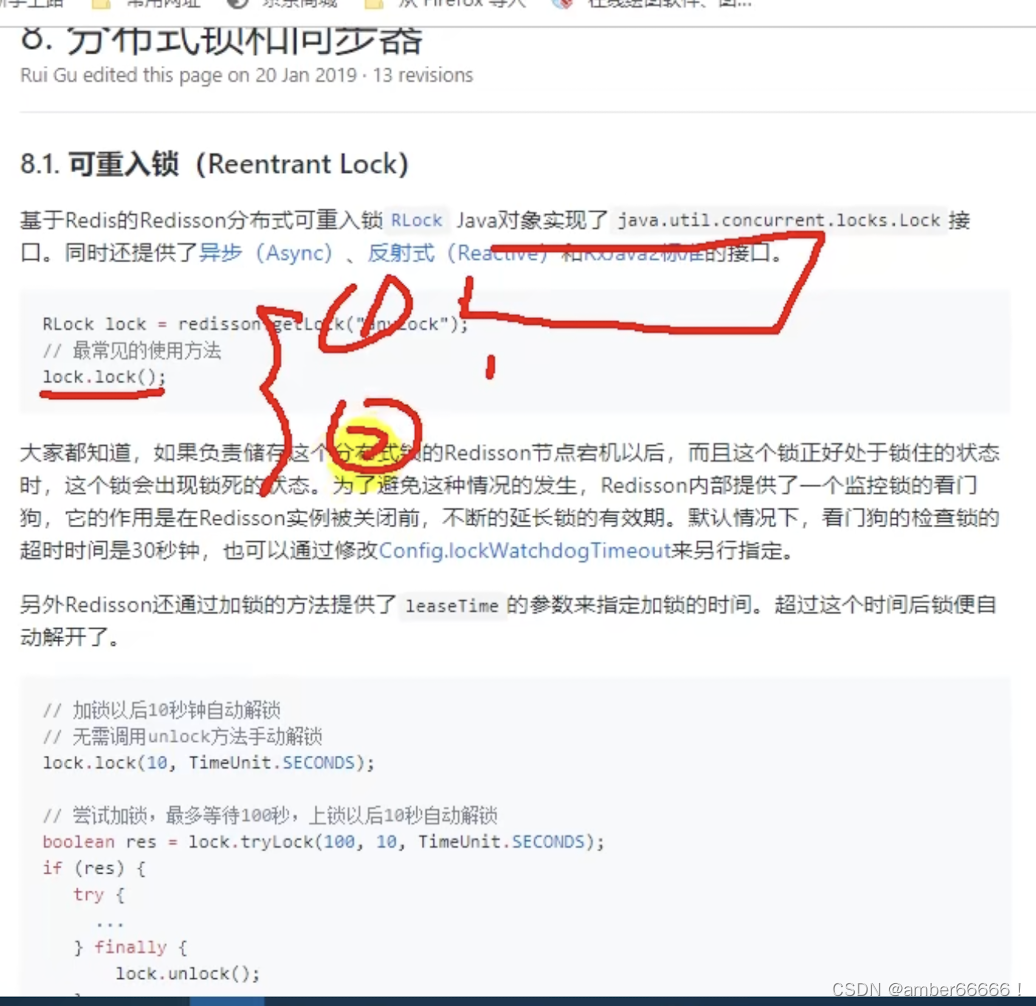
假设解锁代码没有运行,redis会不会出现死锁
(场景 - 运行两个线程 - 在抢到锁的那个线程突然终止不执行释放锁 - 答案- 不会死锁)
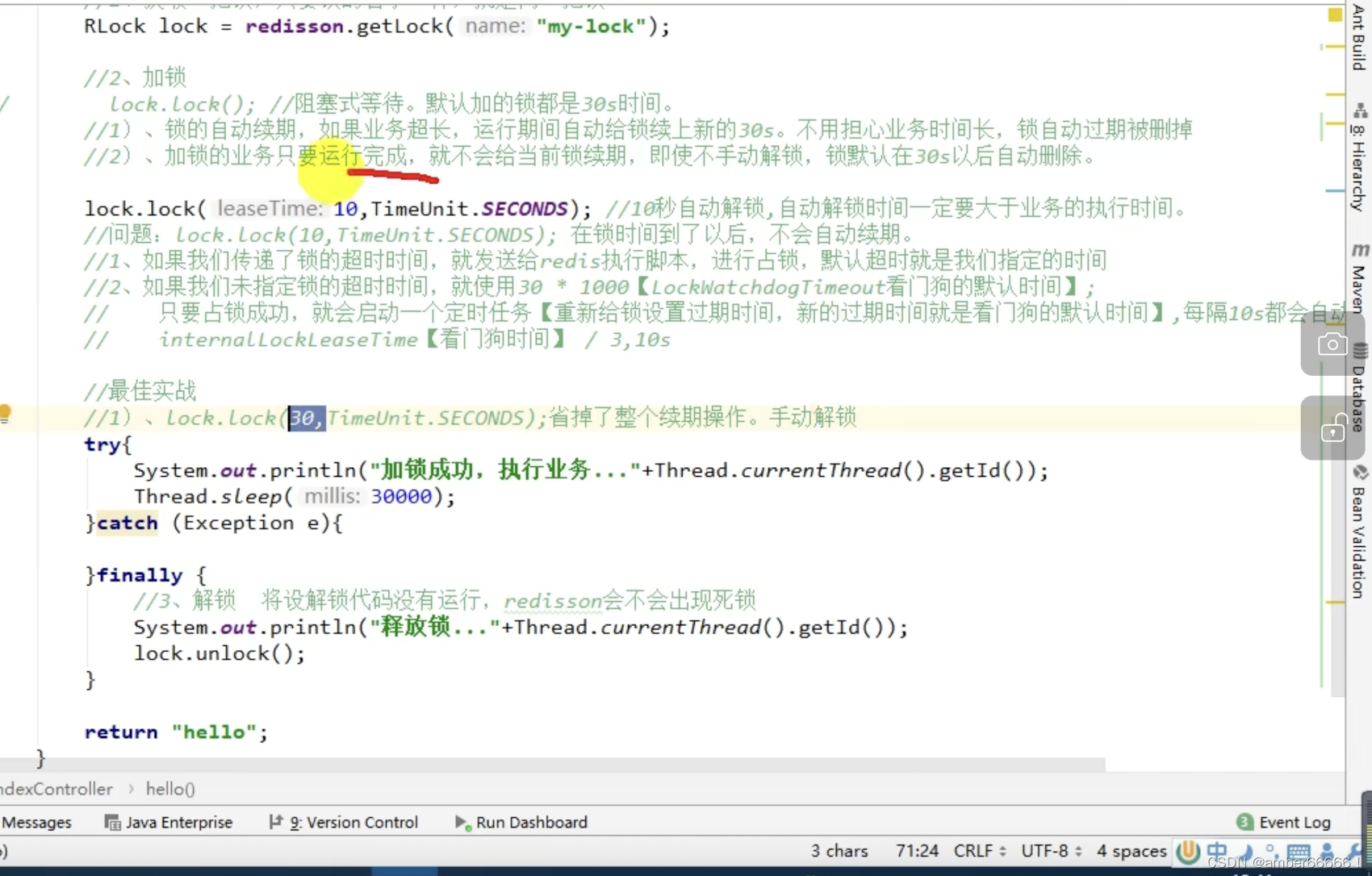
1)锁的自动续期 - 如果业务超长 - 会在运行期间自动给锁续时间30s - 即便没有指定锁的时间也会默认加的时间为30s
2)见code
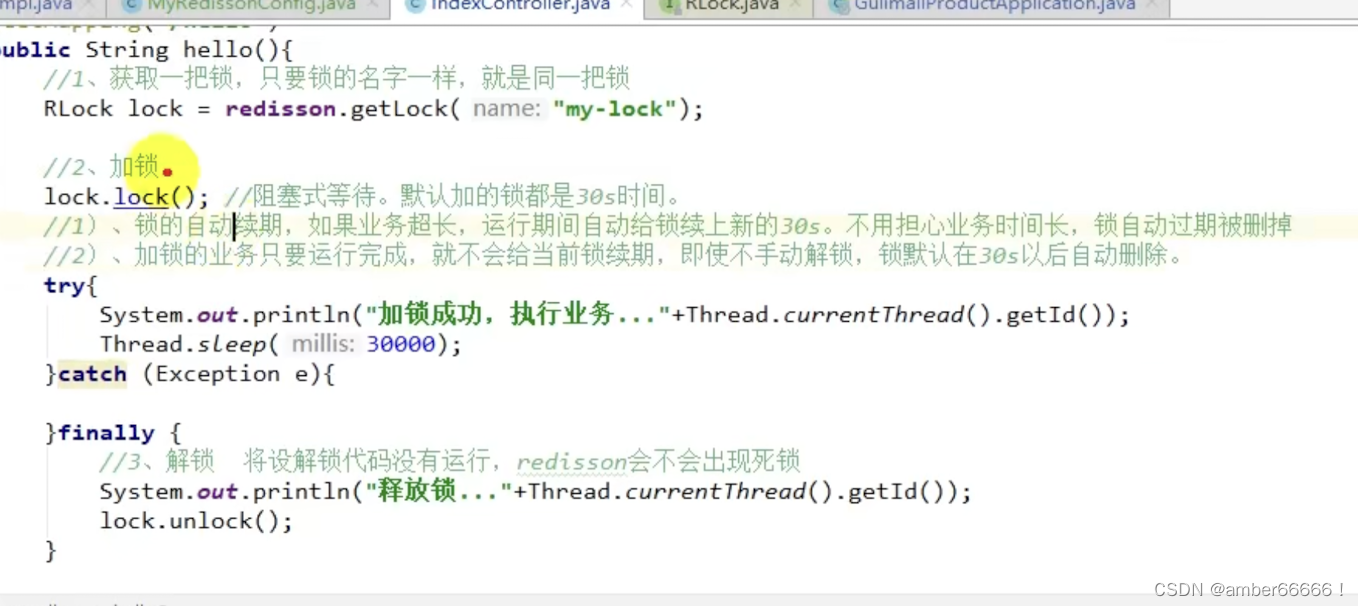
161 redis锁 - lock
设置解锁时间之后,即便业务没有执行完,锁也会释放,看门狗没有作用,不会自动加时。不会自动续期。
这里要注意

当没有设置超时时间的时候,默认使用看门狗的时间 - 30s

有异常的话直接返回,没有的话调用scheduleexpirationrenewal这个方法 - 传入线程号
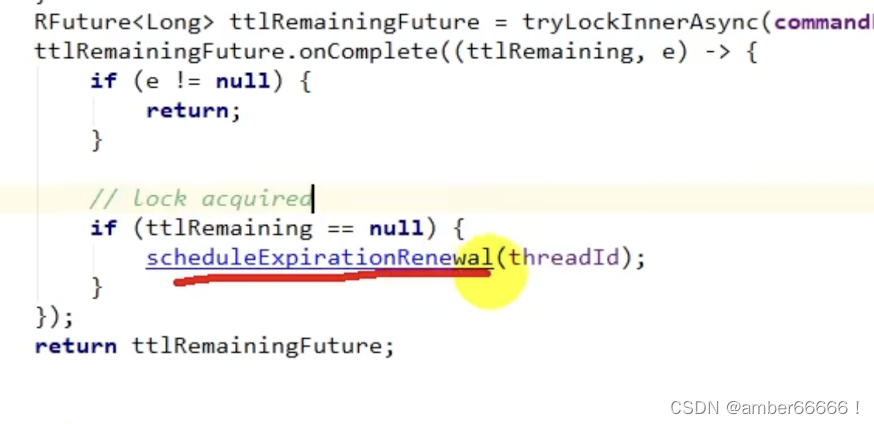
重新设置过期时间,

每到20秒都会续时间到30秒,每隔十秒都会自动再次续期 - 续为30s本来的时间
过于nb了
162
try lock - 阻塞后等锁释放最多等100s,如果等不到就算了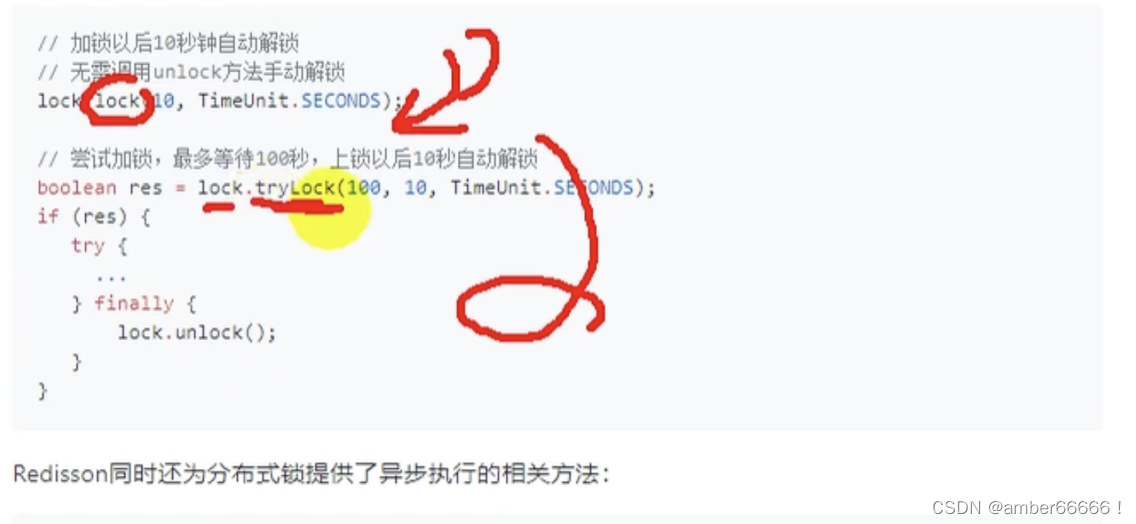
writereadlock - 读写锁
写锁存在,写锁和读锁都要等待
都是读锁的情况不用等待,可以一起执行
存在一个写锁,另一个要写的时候也要等待
















 28万+
28万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









