






系列文章目录
例如:第一章 Python 机器学习入门之pandas的使用
前言
提示:这里可以添加本文要记录的大概内容:
提示:以下是本篇文章正文内容,下面案例可供参考
一、
二、
1.为什么要使用线程池
可以分为核心线程池和非核心的

2.CompletableFuture 异步编排
第四个会依赖一的结果,要查询到sku的基本信息之后,才可以获得他的销售属性.
在编程和数据处理中,某些步骤之间存在依赖关系是很常见的。第四步获取销售属性依赖于第一步获取的基本信息,很可能是因为销售属性数据的获取或计算,需要用到第一步所获得的基本信息。举个例子:
基本信息的获取:第一步可能是获取一个产品的基本信息,如SKU(Stock Keeping Unit库存单位)编号,产品名称,分类等。
销售属性的获取:第四步则可能需要根据SKU编号来查询数据库或API以获取该产品的销售属性,如价格、尺寸、颜色变体等。
如果没有先执行第一步并成功获取到SKU编号,第四步就没有必要的信息来继续执行。这就像是在建房子时,必须先打好地基才能建墙。在编程中,如果试图在没有必要信息的情况下执行操作,可能会导致错误或者无效的结果。因此,程序需要以适当的顺序执行操作,确保所有数据处理都是基于完整和正确的信息集。

2.1 CompletableFuture - 创建异步对象

方法2可以传入指定的线程池
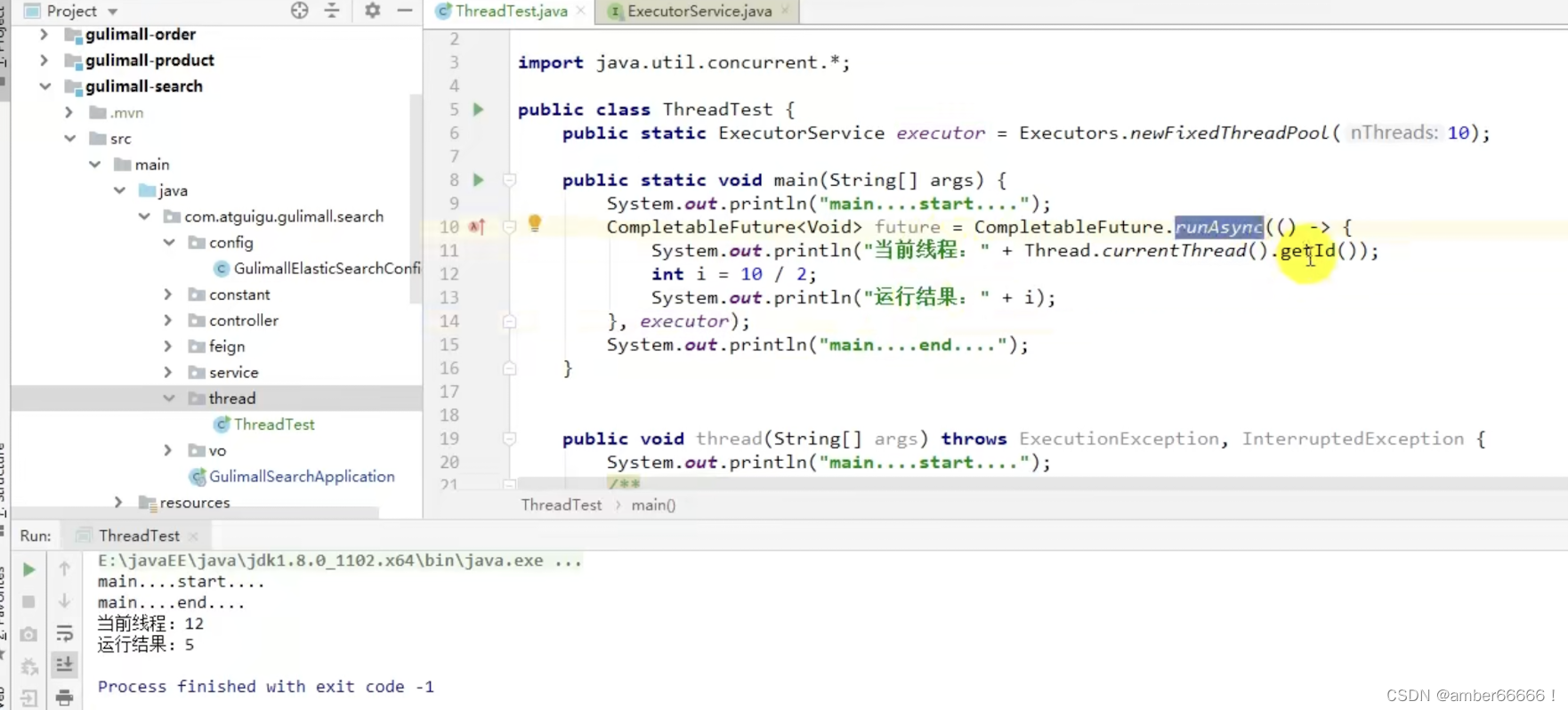
返回的是future对象,那么接下来就可以继续调用future的方法
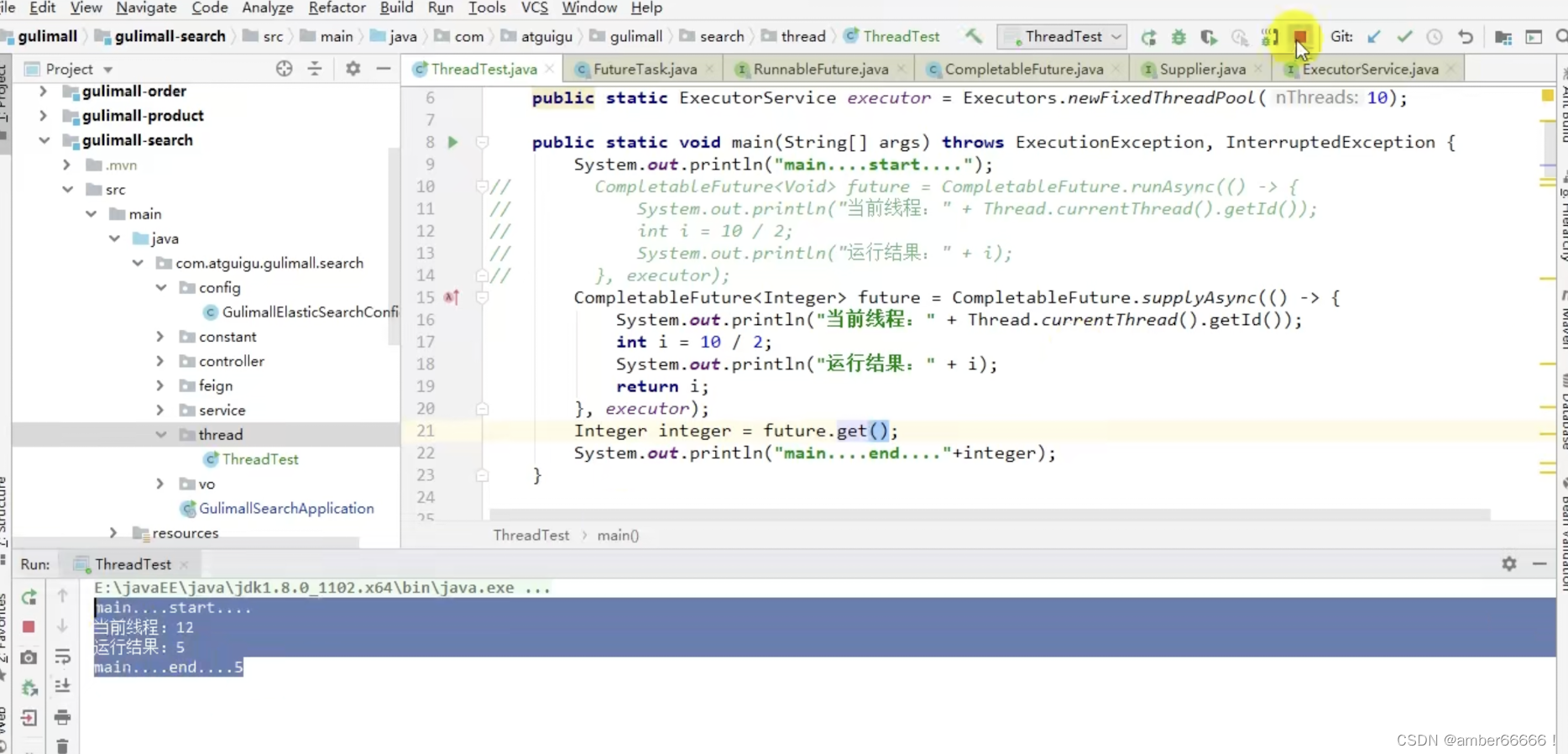
上述应该是有返回值,一个没有返回值
2.1 计算完成时的回调方法
有无Async - 还是在这个线程里面执行
代码如下(示例):
2.
代码如下(示例):
提示:这里对文章进行总结:















 3596
3596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









