







前言
随着 Amazon RDS MySQL 5.7 的生命周期终止,Amazon Aurora 2 大版本(兼容 Amazon RDS MySQL 5.7)将会在 2024 年 10 月 31 日退役。区别于之前的小版本升级的是,从 Amazon Aurora 2 升级到 Amazon Aurora 3 需要进行驱动兼容性测试、数据库对象兼容性测试以及业务 SQL 语句兼容性测试,其中前两者可参考下方升级系列博客:
保驾护航 – Amazon RDS for MySQL 5.7 到 8.0 升级前置检查
https://aws.amazon.com/cn/blogs/china/amazon-rds-for-mysql-5-7-to-8-0-pre-check/
而业务 SQL 语句兼容性检测往往依赖于业务研发分析代码中的 SQL 语法来对比新旧版本的兼容性变化, 需要投入大量的精力。本文将利用 Amazon Virtual Private Cloud (Amazon VPC) Traffic Mirroring 功能来提供一种近乎没有性能影响的方案, 旨在帮助用户更简单地提前发现升级到 Amazon Aurora 3 之后不兼容的语句。
项目范围
本项目在进行 Amazon Aurora MySQL 5.7 到 8.0 的业务 SQL 语句的语法兼容性检查时,将使用 Amazon VPC Traffic Mirroring 进行数据库流量(业务 SQL 语句)的采集,有关 Amazon VPC Traffic Mirroring 的技术细节,见下方表格:

在采集到某段时间内在 Amazon Aurora MySQL 5.7 上执行的业务 SQL 语句之后,我们会使用关键字和 STATEMENT_DIGEST_TEXT 方法来进行语法兼容性检查。
方案

架构设计
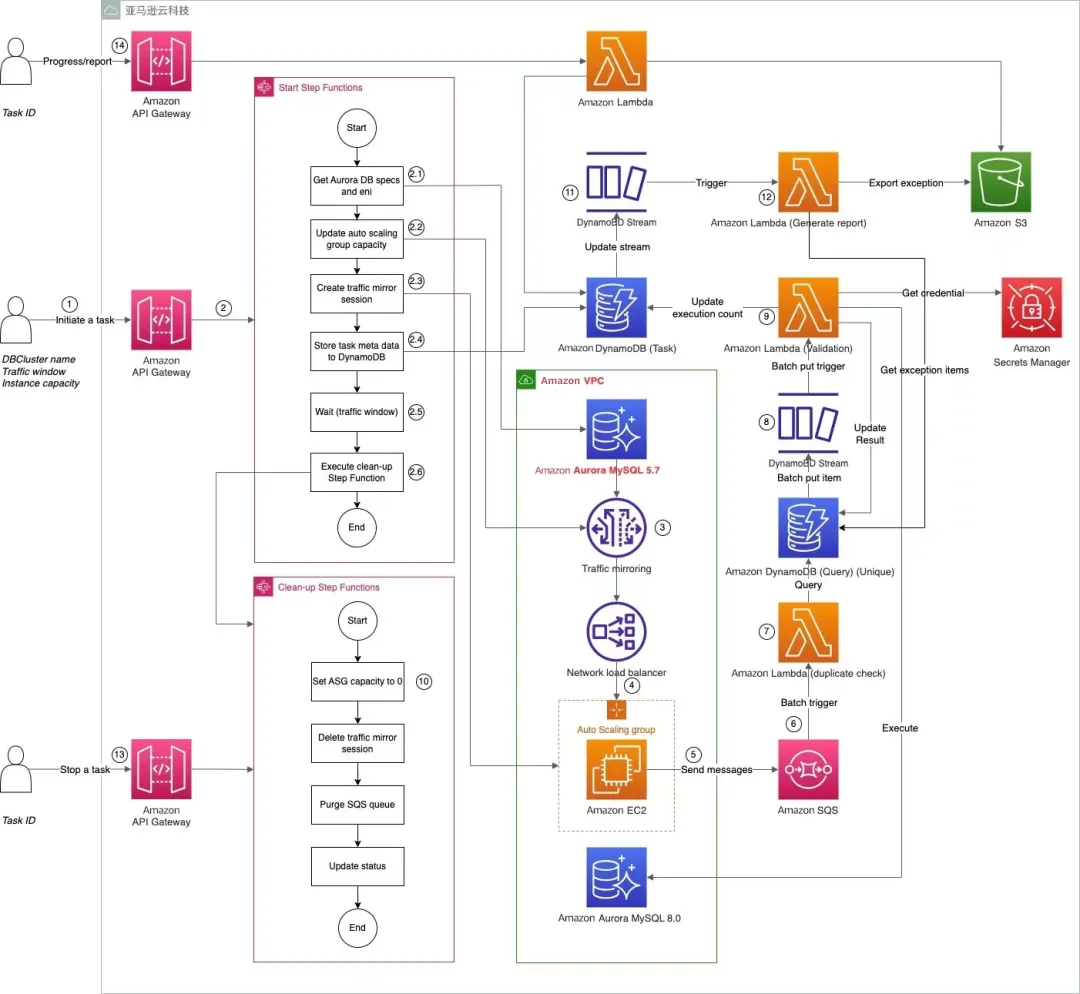
架构详细介绍
1.用户通过 Amazon API 调用启动一次流量兼容性检查任务。Amazon API 接口设计请见接口设计部分。
2.Amazon API Gateway 接受用户请求之后,会启动“Start” Step Function。“Start” Step Function 里面会执行:
检查 Amazon Aurora 数据库的信息,包括硬件配置,网卡信息等。Amazon Aurora 数据库的硬件配置会作为启动机器数量的依据;Amazon Aurora 数据库的网卡信息则会作为 Traffic Mirroring Session 的源。
修改 Amazon Auto Scaling Group 的机器数量,启动数台 Amazon EC2 实例作为 NLB 的目标组。启动机器的配置为,数量是根据源 Amazon Aurora 数据库的配置匹配产生。
启动 Amazon VPC Traffic Mirroring 的 Session,Session 的源为用户传入 Amazon Aurora 数据库的网卡,目标是通过 CDK 部署的 Network Load Balancer(NLB)。
将用户请求元数据作为一个 item 存入 Amazon DynamoDB(Task 表)。
之后 Step Function 进入等待阶段,等待时长是用户设置的采集流量 window。
等待结束之后,异步触发“Clean-up” Step Function。
3.Amazon VPC Traffic Mirroring Session 创建成功之后,会把发往 Amazon Aurora 数据库的流量同时发往 Traffic Mirroring 的目标,也就是 NLB。
4.NLB 会把流量通过负载均衡算法分发给 Amazon Auto Scaling Group 下面的 Amazon EC2 实例。来自同一个源 IP + 端口的流量会被转发到同一台机器。
5.Amazon EC2 实例通过监听 UDP 4789 端口获取 packet,通过 Tshark 软件解析原始 SQL 查询语句,把源 IP,源端口,时间戳,SQL 语句作为一个消息发送给 Amazon SQS。
6.Amazon SQS 触发 Amazon Lambda Function(validate),batch size 为 100,即每次 Amazon Lambda Function 执行的时候可以收到最多 100 条消息。
7.Amazon Lambda Function(validate)会首先对从 Amazon SQS 队列中拿到的文档进行去重处理,对于新的指令会使用在 Secrets Manager 中的 credential 连接一个 Amazon Aurora 3.0.4 Cluster,通过关键字检查和 STATEMENT_DIGEST_TEXT 指令检查 SQL 语句的语法兼容性。运行结果会存储在 Amazon DynamoDB(Query 表)中。
8.Amazon DynamoDB(Query 表)会触发 put item 的 Amazon DynamoDB Stream,启动 Amazon Lambda Function(Aggregation)。batch size 为 2,000。
9.Amazon Lambda Function(Aggregation)会轮训新增的执行结果 item,更新 Amazon DynamoDB(Task 表)中的源数据,供状态查询。
10.“Clean-up” Step Function 里面的步骤为:关闭 Amazon Auto Scaling Group 里面的机器,删除 Traffic Mirroring Session,清空 Amazon SQS,更新 Amazon DynamoDB(Task 表)中的源数据状态为“Finished”。
11.当 Amazon DynamoDB(Task 表)中的源数据被更新为“Finished”或“Stopped”时,Amazon DynamoDB Stream 会触发 Amazon Lambda Function(generate report)。
12.Amazon Lambda Function(generate report)会从 Amazon DynamoDB(Query 表)中查询本次出错的记录,写入 .csv 文件,写入 Amazon S3。.csv 文件中每条出错信息内容包括源 IP,源端口,时间戳,SQL 语句,报错信息。
13.在检查任务进行中(In progress 状态时),用户可以强行停止检查任务,并且关闭所有资源。这时该任务的状态变为“Stopped”。
14.用户可以调用查看任务进度和报告接口,该接口后面的 Amazon Lambda Function 会从 Amazon DynamoDB(Task 表)中查找该任务的状态,如果状态为 Finished 或者 Stopped 状态,Amazon Lambda Function 还会从 Amazon S3 中获取报告的下载连接。
主要服务
Amazon DynamoDB
Amazon DynamoDB 是一种全托管 NoSQL 数据库服务,提供快速而可预测的性能,能够实现无缝扩展。Amazon DynamoDB 可以免除操作和扩展分布式数据库的管理工作负担,因而无需担心硬件预置、设置和配置、复制、软件修补或集群扩展等问题。在本次原型项目中,我们使用 Amazon DynamoDB 来存储不同用户的会话相关的数。
Amazon DynamoDB Stream 是一种有关 Amazon DynamoDB 表中的项目更改的有序信息流。当您对表启用流时,Amazon DynamoDB 将捕获有关对表中的数据项目进行的每项修改的信息。在本次原型项目中,我们使用 Amazon DynamoDB Stream 实现模块之间的事件驱动(event driven),减少模块之间的相互依赖。
Amazon Lambda
利用 Amazon Lambda,您可以运行代码而无需预置或管理服务器。您只需为使用的计算时间付费,在代码未运行期间不产生任何费用。您可以为几乎任何类型的应用程序或后端服务运行代码,而无需任何管理。在本次原型项目中,我们使用 Amazon Lambda Function 执行一系列复杂的操作,比如说通过 Amazon Aurora Endpoint 找到 db cluster 的网卡信息等。
Amazon Step Functions
Amazon Step Functions 是一项无服务器编排服务,可让您与 Amazon Lambda Function 和其他功能集成亚马逊云科技服务以构建关键业务应用程序。使用 Amazon Step Functions 的内置控件,您可以检查工作流中每个步骤的状态,以便确保应用程序按预期顺序运行。本项目中 Amazon VPC Traffic Mirroring 的开启和关闭流程复杂,我们使用 Amazon Step Functions 来编排代码。
Amazon SQS
Amazon Simple Queue Service(SQS)是适用于微服务、分布式系统和无服务器应用程序的完全托管的消息队列,其中标准 Queue 可以提供接近无限的吞吐量,在本项目中适合存储来自源数据库网卡的流量信息。
Amazon S3
Amazon Simple Storage Service(Amazon S3)是一种对象存储服务,提供行业领先的可扩展性、数据可用性、安全性和性能。本项目中的关键结果就是兼容性检查的报错信息,由于报错信息可能会比较大,很难通过 Amazon API 接口以 .json 的格式返回,同时多次调用接口可能导致 Amazon DynamoDB 查询费用上升。我们会一次性把报错生成 .csv 文件保存到 Amazon S3 上,供用户随时下载查看。
Amazon VPC
借助 Amazon VPC,您可以在您定义的逻辑隔离的虚拟网络中启动亚马逊云科技资源。这个虚拟网络与您在数据中心中运行的传统网络极其相似,并会为您提供使用的可扩展基础设施的优势亚马逊云科技。
Traffic Mirroring 流量镜像是 Amazon VPC 的一个功能,您可以使用它来复制来自弹性网络接口的网络流量。本次原型项目中,我们利用 Traffic Mirroring 的功能复制来自 Amazon Aurora 网卡的流量,从而拿到 SQL query,而对生产数据库零影响。
Network Load Balancer
Network Load Balancer (NLB) 在一个或多个可用区中的多个目标(如 Amazon EC2 实例、容器和 IP 地址)之间自动分配传入的流量。它会监控已注册目标的运行状况,并仅将流量传输到运行状况良好的目标。弹性负载均衡 根据传入流量随时间的变化对负载均衡器进行扩展。它可以自动扩展来处理绝大部分工作负载。本原型项目中使用 NLB 把生产数据库的流量分发给不同的 Amazon EC2 实例,降低单台 Amazon EC2 的压力。
Amazon Secrets Manager
借助 Amazon Secrets Manager,您可以在数据库凭证、应用程序凭证、OAuth 令牌、API 密钥和其他密钥的整个生命周期内对其进行管理、检索和轮换。许多亚马逊云科技服务将密钥存储在 Amazon Secrets Manager 中。本项目中我们把 Amazon Aurora 3 的数据库访问令牌存储在 Amazon Secrets Manager 中,避免在代码中硬编码降低安全性。
名词解释
●Task:用于抓取某段时间的 Amazon Aurora 集群流量的一个任务, 包含时间窗口、开始时间、状态等信息。
●Traffic Window:一个 Task 抓取 Amazon Aurora 集群流量的时间窗口,单位为小时,比如 2 代表从 Task 被启动到完成中间等待 2 小时。
●Agent:启动在 ASG 中的每个 Amazon EC2 上的抓取 Amazon Aurora 集群流量数据的进程,对应代码在每台 Amazon EC2 的 /home/ec2-user/agent/agent.py 脚本。
●Agent Amazon EC2:用于运行 Agent 的 Auto Scaling Group 中的 Amazon EC2。
语法检查说明
本次原型项目我们进行的语法检查主要包括以下三个方法:
● 使用 MySQL 8.0 的 function STATEMENT_DIGEST_TEXT 进行检查,示例如下:
MySQL [sales_db]> SELECT STATEMENT_DIGEST_TEXT('CREATE TABLE t_gcol_dep (fid INTEGER NOT NULL PRIMARY KEY, g POINT GENERATED ALWAYS AS (PointFromText(POINT(10, 10))));'); ERROR 3676 (HY000): Could not parse argument to digest function: "Expression of generated column 'g' contains a disallowed function: `PointFromText`.".左右滑动查看完整示意
● 使用正则匹配,检查 MySQL 8.0 不支持的 function,检查的 function 列表如下:
functions = ['load_file', 'udf', 'geometrycollectome', 'geomcollfromtext', 'linestringfromtext', 'polygonfromtext', 'pointfromtex']左右滑动查看完整示意
● 使用正则匹配,检查 MySQL 8.0 预留的关键字,关键字列表如下:
keywords = [
'cume_dist', 'dense_rank', 'empty', 'except', 'first_value',
'grouping', 'groups', 'json_table', 'lag', 'last_value',
'lateral', 'lead', 'nth_value', 'ntile', 'of', 'over',
'percent_rank', 'rank', 'recursive', 'row_number', 'system', 'window'
]左右滑动查看完整示意
如果关键字用“引起来,则检查通过,否则不通过。
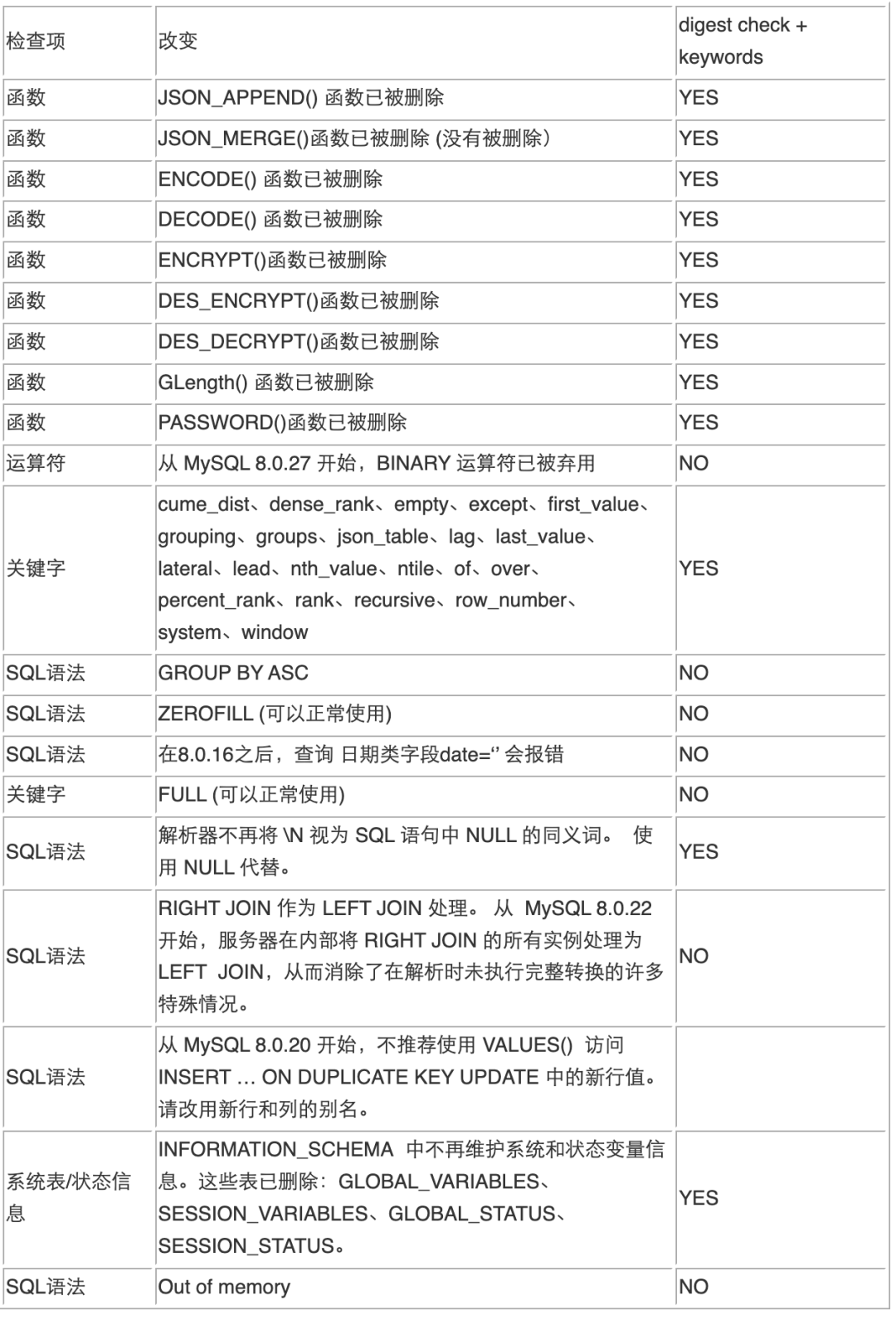
以下表格是我们通过测试列举出来的一些检查项,在 MySQL 8.0 上使用以上三种检查方式结合即 digest check + keywords 的检查结果的对比。
接口使用说明
本方案共实现了 3 个接口:启动检查任务接口;查看任务进度和报告接口;强行停止任务接口。
Amazon API example
https://xxxxxxxxxxx.execute-api.ap-southeast-1.amazonaws.com/prod/task
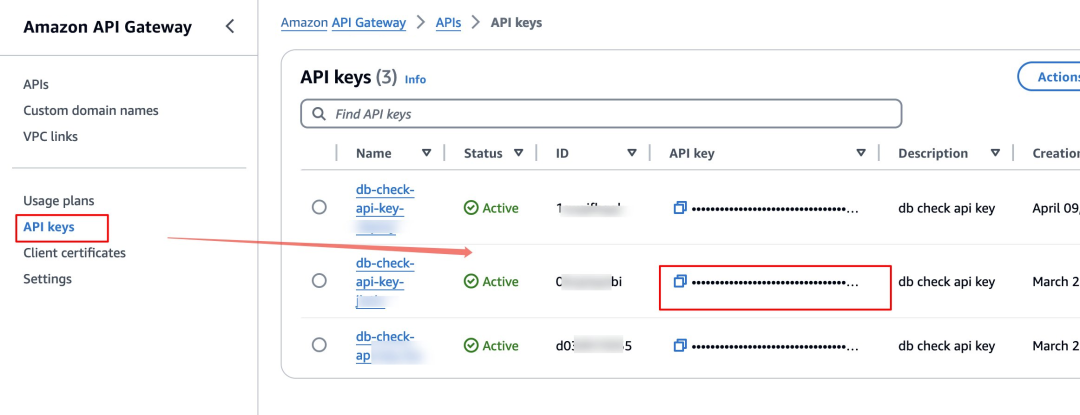
在使用该接口时, 需要在 Headers 中传入 x-api-key, 对应的 value 在 Amazon Console API Gateway 服务中, 如下图,找到您对应的 API key 复制即可:
启动检查任务接口:POST
● Request body:
{
"cluster_identifier": "string",
"traffic_window": 2
}左右滑动查看完整示意
database_endpoint 为数据库 Endpoint。traffic_window 为流量采集时长,单位为小时。
● Response:
{
"task_id": "string",
"message": "string"
}左右滑动查看完整示意
Task_id 是这次任务的唯一编号,其他的接口需要传入此 ID 进行针对一次检查任务的操作。message 是报错信息,默认为空。
查看任务进度和报告接口:GET
● Request:
?task_id=xxxx左右滑动查看完整示意
● Response:
# Response 的内容与 Task 的状态有关。
{
"message": "",
"status": "Finished", # Created,In progress,Finished,Stopped, Error
"captured_query": 134, # 抓取到的query数量
"checked_query": 3, # 已完成检查的query数量
"failed_query": 2, # 出错的query数量
"created_time": "2024-03-29T07:39:34.354Z",
"traffic_window": 1,
"complete_percentage": "100%", # 已经过去的时间/采集的总时间 * 100%
"start_capture_time": "2024-03-29T07:40:58.354Z", # 开始采集第一批query的时间
"end_time": "2024-03-29T08:39:50.354Z", # 任务结束/停止时间
"report_s3_presign_url":"presign_url_you_can_open_to_download_the_file", # 报告的下载链接
"report_s3_uri": "s3://bucket_name/failed_reports/task_id/failed_queries.csv" # 报告的S3 URI
}左右滑动查看完整示意
停止任务接口:PUT
● Request body:
{
"task_id": "string"
}左右滑动查看完整示意
Task_id 是这次任务的唯一编号。
● Response:
{
"message": "string"
}左右滑动查看完整示意
message 是报错信息,默认为空。
检查报告示例
在通过语法检查之后,如果有检查未通过的 Query,对于这些检查未通过的 Query 会生成一个 .csv 文件的报告,示例如下:
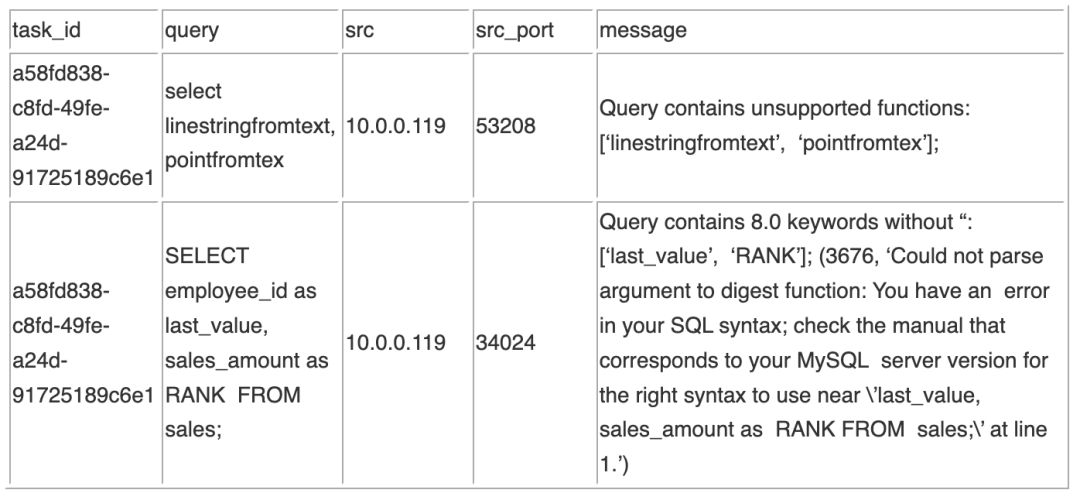
具体的检查未通过的原因在 message 一列中,如果当前进行的三种检查都未通过,则对应的信息都放于该字段中,并以;分隔。
部署文档
前提条件
● 确定需要部署的 Amazon VPC,被监控的 Amazon Aurora 数据库必须在同一个 Amazon VPC 下,记录下 Amazon VPC ID,作为参数。
● 在检测流量兼容性时,我们需要启动一台 MySQL 8.0 的 Amazon Aurora 数据库,所以需要准备至少两个私有子网 ID,作为参数,使用英文逗号分隔。
● 在采集流量的时候,我们需要部署一些 Agent Amazon EC2 实例,这些 Amazon EC2 实例需要部署在至少一个公有子网中,该公有子网应该有至少 100 个剩余 IP,这个公有子网的 IP 作为参数,如果多于一个公有子网,使用英文逗号进行分隔。
● 一个 Keypair,用于 ssh 本账号本区域下的 Linux 服务器,这个 Keypair 的名字作为参数。
● 最后,作为部署人员,需要至少有权限部署 CDK 代码,并且使用 Amazon Cloudshell 服务。
● 本方案 CDK 代码仓库链接在下面的附录 3。
部署步骤
在 Amazon Console 中搜索 Amazon Cloudshell 服务,或者打开 Cloudshell Console:
以新加坡 region 为例:
新加坡 region
https://ap-southeast-1.console.aws.amazon.com/cloudshell/home?region=ap-southeast-1
点击右上角 Action 下拉菜单,选择 Upload file。
选择本地下载的 CDK 压缩文件 queries-compatibility-check.zip。
默认会上传到 /home/cloudshell-user 目录,并在该目录下执行:
unzip queries-compatibility-check.zip
cd queries-compatibility-check
pip3 install -r requirements.txt
# Install requirements for lambda layer
cd infrastructure/query_validation/lambda_function/
mkdir -p lambda_layer/python && cd lambda_layer/python/
pip3 install -t . pymysql
# Go back to folder queries-compatibility-check/
cd infrastructure/query_collection/lambda_function/
mkdir -p lambda_layer/dnspython/python && cd lambda_layer/dnspython/python
pip3 install -t . dnspython
cdk bootstrap -c env=<environment name> \
-c vpc=<VPC ID> \
-c private_subnets=<private subnets ID> \
-c public_subnets=<public subnets ID> \
-c keypair=<Keypair name>
# Example: cdk deploy -c env=dt \
# -c vpc=vpc-0b217a017fa41dedb
# -c private_subnets=subnet-0dadd45276ef33efc,subnet-01ab09023c8403e03\
# -c public_subnets=subnet-090b3b480c87e8c56
# -c keypair=dt-deploy
cdk deploy -c env=<environment name> \
-c vpc=<VPC ID> \
-c private_subnets=<private subnets ID> \
-c public_subnets=<public subnets ID> \
-c keypair=<Keypair name>左右滑动查看完整示意
查询报告
在 Amazon Console 中打开 Amazon Athena,在 Query Editor 中运行以下 SQL(如果当前账号未配置使用过 Amazon Athena,需要在第一次使用时配置一个用来输出查询运行日志的 Amazon S3 bucket)。
-- 创建表,注意请将LOCATION中的S3 bucket名字改成我们用CDK部署的S3 bucket
CREATE EXTERNAL TABLE failed_report_table (
task_id string,
query string,
src string,
src_port string,
message string
)
PARTITIONED BY (id string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
STORED AS TEXTFILE
LOCATION 's3://db-check-bucket-637423544808-ap-southeast-1-jiatin/failed_reports/';
-- 加入新分区的数据,后续如果有新的task跑完,直接运行此句即可
msck repair table failed_report_table;
-- 查询数据
select * from failed_report_table where id='502395e9-220b-4ec2-a5ee-04c7641478a0';左右滑动查看完整示意
测试总结
Agent(部署在 Amazon EC2 上运行 Tshark 抓取 Amazon Aurora 流量数据的 Python 脚本)
● Agent 机型为 c6gn.large。
● Agent 的并发数为 6,在 Aurora db.r6g.16xlarge 的机型上压测时,c6gn.large 每秒钟通过 Tshark 抓取到进行 filter 等操作并发送到 Amazon SQS 的最大数量为 500 左右。
整体架构压测
● 在 Amazon Aurora db.r6g.16xlarge 的机型上压测时,用 32 台 c6gn.large 机型抓取流量,从 Task 启动到开始抓取第一批流量的时间为 4 分钟左右。对应 Task get 接口中的 start_capture_time – created_time。
● 在 Amazon Aurora db.r6g.16xlarge 的机型上每秒钟 20K 左右的 query 数量时,用 32 台 c6gn.large 机型抓取流量,大约在停止往 Amazon Aurora 发送 query 的 1 分钟之后获取到所有 query,对应 Task get 接口中的 captured_query。
MySQL client connection
● 对于从 client 起的一个 connection,对应一台抓取流量的 Amazon EC2。
对于 UDP 流量、负载均衡器使用基于协议、源 IP 地址、源端口、目标 IP 地址和目标端口的哈希算法选择目标。一个 UDP 流具有相同的源和目标,因此在其生命周期内会始终路由到同一个目标。不同的 UDP 流具有不同的源 IP 地址和端口,因此它们可以被路由到不同的目标。
24 小时测试报告
Amazon RDS Aurora
Write instance: db.r6g.16xlarge
Read instance: db.r6g.16xlarge
Agent: c6gn.2xlarge * 16
{
"message": "",
"status": "Finished",
"captured_query": 1067483255,
"checked_query": 463,
"failed_query": 7,
"created_time": "2024-04-18T08:58:37.621Z",
"traffic_window": 24,
"complete_percentage": "100%",
"start_capture_time": "2024-04-18T09:00:16.934Z"
}左右滑动查看完整示意
截取流量总大小:1,067,483,255
截取流量时长:24 小时
流量速率:12k/s
参数调整
本解决方案里面有很多地方可以按照实际情况进行调整和升级:
ASG 里的 Amazon EC2 数量和类型
如果我们发现后续使用的时候,Agent 的 Amazon EC2 的 CPU 使用率不高,或者对于目标数据库高并发场景有限,可以更改 ASG 里面 Amazon EC2 的数量甚至机型,具体更改方法如下:
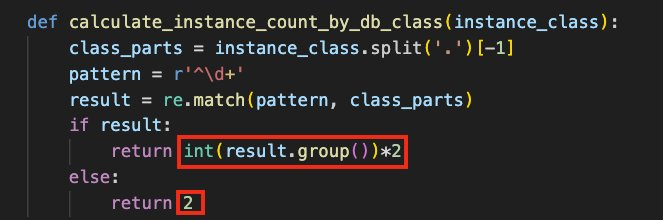
更改机型:在 /infrastructure/query_collection/launch_template/stack.py 文件中搜索 aws_ec2.InstanceType.of,通过更改 XLARGE2,可以更改 Amazon EC2 的大小,目前 C6GN 的最小机型是 MEDIUM,如果选择 2xlarge 的机型,需改为 XLARGE。如下图中所示,为 c6gn.2xlarge:
Agent 的并发
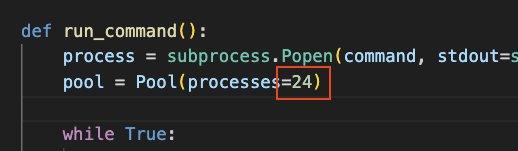
通过更改 Agent 的并发可以有效地提高 Agent 的效率,目前我们测试的条件下,单台 Amazon EC2 启动 7 并发效果比较好,不过这个并发数也可以根据未来的实际情况机型调整,并发数越高,单 Agent 的利用率越高,CPU 用量也越高。想调整 Agent 并发数,可以修改 /agent/agent.py 文件,找到 run_command 方法,修改 processes 的数量,如下图改为并发 24:
Validation Lambda Function
的检查项添加
我们现在在验证 query 兼容性方面做了如下的处理:使用正则表达式查找 query 是否使用了 MySQL 8.0 不支持的方法;使用正则表达式查找 query 中是否使用了新增的 MySQL 8.0 关键字;使用 MySQL 8.0 新增的 STATEMENT_DIGEST_TEXT 方法验证 syntax 是否正确。如果有需要新增了新的关键字,或者新增的检查,我们都可以通过更改/infrastructure/query_validation/lambda_function/validate_query/lambda_function.py 方法来新增或者去掉检查内容。目前的 3 个检查方法分别为:check_for_unsupported_functions,check_for_keywords,check_for_mysql_syntax。我们可以根据需要,增加自己的方法或者去掉不需要检查的项目。
从 Amazon SQS 消费 message 对 query 去重的批处理大小
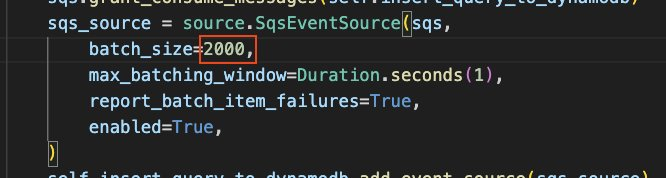
在架构中,我们有一个 Amazon Lambda Function 会从 Amazon SQS 中接到所有的流量,然后去重之后写入 Amazon DynamoDB,而后进行后续的流程。这个 Amazon Lambda Function 我们进行了批处理的操作,一次从 Amazon SQS 中取 2,000 条 query 然后进行去重的工作。这个批处理的步骤的批量大小也可以进行配置。
修改 /infrastructure/query_collection/lambda_function/stack.py 文件,搜索关键字 sqs_source,通过修改 batch_size 或者 max_batch_window 来控制批处理工作的批量大小和等待时间:
使用限制
目前仅支持 Amazon Aurora MySQL 8.0 语法兼容性检查, 不会检查执行效率以及返回结果。
基于 Amazon VPC Traffic Mirroring 限制,超过 8947 bytes 的 SQL 语句无法检查。
部分废弃语法不支持检查,详见上面 <语法检查说明> 章节的表格说明。
如果应用程序是使用 TLS 连接访问 Amazon Aurora 数据库,无法使用 Traffic Mirroring 获取加密流量。
安全建议
Amazon CloudWatch log group 加密。
Amazon S3 bucket 开启 access logging。
Amazon API Gateway 调用白名单限制。
附录
CDK 文档
https://aws.amazon.com/cn/blogs/china/amazon-rds-for-mysql-5-7-to-8-0-pre-check
本方案代码仓库:
https://github.com/aws-samples/queries-compatibility-check
本篇作者

Fox Qin
亚马逊云科技快速原型团队解决方案架构师,主要负责 IoT 和移动端方向的架构设计和原型开发,此外对亚马逊云科技的无服务器架构、跨地区的多账号组织、网络管理、解决方案工程化部署等方面也有深入的研究。

贾婷
亚马逊云科技快速原型团队解决方案架构师,致力于帮助客户设计和开发大数据方向的快速原型方案,有游戏、汽车等行业的大数据开发经验。

陈阳
亚马逊云科技数据库专家架构师,十余年数据库行业经验,主要负责基于亚马逊云科技云计算数据库产品的解决方案与架构设计工作。在海量数据架构设计、自动化运维、稳定性保障等方面有丰富的经验。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!
















 9267
9267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









