







背景
相较于直接使用 Amazon EC2,通过 Amazon SageMaker 进行模型训练具有训练环境统一,降低训练实例的空置率,减少训练任务的等待资源的时间等优势。
在复杂模型的训练场景下,一般我们会选用 BYOC(Bring Your Own Container),即构建自定义镜像的方式在 Amazon SageMaker 上进行模型训练。构建的容器中包含了训练所需要的操作系统和依赖项构成的独立隔离环境,因此其可以确保一致的运行时和可靠的训练过程。通过在容器中增加 Amazon SageMaker-Training-Toolkit 的依赖即可完成训练环境与 Amazon SageMaker 的集成。通常不同的模型需要的框架和依赖不同,因此需要为不同的模型构建不同的镜像。
LlamaFactory 框架支持多种 Llama 类模型的训练与微调技术,因此我们可以构建统一的容器来完成多种 Llama 类模型的训练与微调,减少构建不同镜像的工作量。
本文以 Amazon SageMaker 平台上使用 LlamaFactory 框架训练 Llama3 为例介绍这一过程。
源码
https://github.com/aws-samples/training-meta-llama-3-on-amazon-sagemager-with-llama-factory
Amazon SageMaker 介绍
Amazon SageMaker 是一项机器学习服务,可帮助数据科学家和开发人员快速准备机器学习模型。它提供了全面的工具集,涵盖了从构建、训练到部署机器学习模型的整个过程,其功能涵盖了机器学习全流程,提供了完整的工具集,使数据科学家和开发人员能够快速构建、训练和部署机器学习模型,并持续优化模型性能。
Amazon SageMaker Training 镜像构建
我们可以使用 Amazon EC2 来进行镜像构建。本文采用了 g5.2xlarge 的 Amazon EC2 以及 Deep Learning AMI GPU PyTorch 2.0.0(Ubuntu 20.04)的 AMI 进行了测试验证 。
训练脚本来源于下方链接。请确保您拥有 Hugging Face 的 API Token。并且已经通过了权限申请。
训练脚本
https://github.com/Shenzhi-Wang/Llama3-Chinese-Chat
Hugging Face 的 API Token
https://huggingface.co/docs/transformers.js/guides/private
权限申请
https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
1. 构建包含 LlamaFactory 以及 Amazon SageMaker-Training-Toolkit 的 Dockerfile:
# 根据https://docs.nvidia.com/deeplearning/frameworks/support-matrix/index.html 找到合适的基础镜像
FROM nvcr.io/nvidia/pytorch:24.01-py3
ENV LANG=C.UTF-8
ENV PYTHONUNBUFFERED=TRUE
ENV PYTHONDONTWRITEBYTECODE=TRUE
# 允许使用所有显卡
ENV NVIDIA_VISIBLE_DEVICES="all"
# 下载并安装LlamaFactory
RUN git clone https://github.com/hiyouga/LLaMA-Factory.git --branch v0.7.0 --single-branch
WORKDIR /workspace/LLaMA-Factory
RUN pip install -e .[metrics,deepspeed,bitsandbytes]
# 安装SageMaker-Training-Toolkit的pytorch版本
RUN pip install sagemaker-pytorch-training
COPY llama3-sft.sh .
COPY ad-hoc-inference.py .左右滑动查看完整示意
2. 构建镜像:
docker build . -t llama-factory3. 进入容器并进行本地测试:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -it llama-factory bash左右滑动查看完整示意
考虑到本地 GPU VRAM 比较小,我们这里选用量化的模型配合 QLora 来进行 SFT 训练测试容器环境:
# 将YOUR_HF_TOKEN替换为您的HuggingFace Access Token
export HF_TOKEN=YOUR_HF_TOKEN
export 'PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:32'
deepspeed --num_gpus 1 src/train_bash.py \
--deepspeed examples/deepspeed/ds_z2_offload_config.json \
--stage sft \
--do_train \
--model_name_or_path unsloth/llama-3-8b-Instruct-bnb-4bit \
--dataset identity,alpaca_gpt4_en \
--template llama3 \
--finetuning_type lora \
--lora_target all \
--quantization_bit 4 \
--output_dir ../llama-result-lora \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--log_level info \
--logging_steps 5 \
--save_strategy epoch \
--save_total_limit 1 \
--save_steps 100 \
--learning_rate 5e-5 \
--loraplus_lr_ratio 16 \
--max_grad_norm 1 \
--num_train_epochs 1.0 \
--plot_loss \
--do_eval false \
--max_steps -1 \
--bf16 true \
--seed 42 \
--warmup_ratio 0.1 \
--cutoff_len 8192 \
--flash_attn auto \
--orpo_beta 0.05 \
--overwrite_output_dir左右滑动查看完整示意
4. 把容器推送到 Amazon ECR 上。
推送到 Amazon ECR
https://docs.aws.amazon.com/AmazonECR/latest/userguide/docker-push-ecr-image.html
训练
1. 在 Amazon SageMaker Studio Code Editor 或者 JupyterLab 中准备以下目录及文件:
llama3-training -- train.ipynb
\- src -- train.sh
# train.ipynb
import sagemaker
import os
from sagemaker.pytorch.estimator import PyTorch
from time import gmtime, strftime
job_id = "llama3-chinese-full-"+strftime("%Y-%m-%d-%H-%M-%S", gmtime())
# 训练结果存储的S3桶
bucket = "YOUR_BUCKET"
# 请确保训练使用的角色可以写入上述S3桶
sm_role = sagemaker.get_execution_role()
print(sm_role)
# 如果是PEFT训练则可以考虑使用ml.g5系列,并且设置use_spot_instances=True
instance_type = 'ml.p4d.24xlarge'
use_spot_instances = False
max_wait = 1200 if use_spot_instances else None
# 适当调整训练任务最大运行时间
max_run = 432000
# 如果想在训练完成后不立即回收加快下一次训练的启动时间,则可以设置keep_alive_period_in_seconds
keep_alive_period_in_seconds = None
# 拼接输出路径
output_uri = os.path.join("s3://", bucket, job_id, "output")
checkpoint_uri = os.path.join("s3://", bucket, job_id, "checkpoints")
metric_definitions = [
{'Name': 'loss', 'Regex': "'loss': ([0-9]+(.|e-)[0-9]+),?"},
{'Name': 'grad_norm', 'Regex': "'grad_norm': ([0-9]+(.|e-)[0-9]+),?"},
{'Name': 'learning_rate', 'Regex': "'learning_rate': ([0-9]+(.|e-)[0-9]+),?"},
{'Name': 'rewards/chosen', 'Regex': "'rewards/chosen': ([0-9]+(.|e-)[0-9]+),?"},
{'Name': 'rewards/rejected', 'Regex': "'rewards/rejected': ([0-9]+(.|e-)[0-9]+),?"},
{'Name': 'rewards/accuracies', 'Regex': "'rewards/accuracies': ([0-9]+(.|e-)[0-9]+),?"},
{'Name': 'rewards/margins', 'Regex': "'rewards/margins': ([0-9]+(.|e-)[0-9]+),?"},
{'Name': 'logps/rejected', 'Regex': "'logps/rejected': ([0-9]+(.|e-)[0-9]+),?"},
{'Name': 'logps/chosen', 'Regex': "'logps/chosen': ([0-9]+(.|e-)[0-9]+),?"},
{'Name': 'logits/rejected', 'Regex': "'logits/rejected': ([0-9]+(.|e-)[0-9]+),?"},
{'Name': 'logits/chosen', 'Regex': "'logits/chosen': ([0-9]+(.|e-)[0-9]+),?"},
{'Name': 'sft_loss', 'Regex': "'sft_loss': ([0-9]+(.|e-)[0-9]+),?"},
{'Name': 'odds_ratio_loss', 'Regex': "'odds_ratio_loss': ([0-9]+(.|e-)[0-9]+),?"},
{'Name': 'epoch', 'Regex': "'epoch': ([0-9]+(.|e-)[0-9]+),?"},
]
environment = {'NCCL_DEBUG': 'INFO', 'FI_PROVIDER': 'efa', 'NCCL_PROTO': 'simple', 'FI_EFA_USE_DEVICE_RDMA': '1'}
huggingface_estimator = PyTorch(entry_point='train.sh',
source_dir='./src',
instance_type=instance_type,
instance_count=1,
image_uri='YOUR_IMAGE_URI',
role=sm_role,
metric_definitions = metric_definitions,
environment=environment,
use_spot_instances=use_spot_instances,
max_run=max_run,
max_wait=max_wait,
output_path=output_uri,
checkpoint_s3_uri=checkpoint_uri,
keep_alive_period_in_seconds=keep_alive_period_in_seconds,
)
huggingface_estimator.fit(job_name=job_id)
# train.sh
cd /workspace/LLaMA-Factory
export HF_TOKEN=YOUR_HF_TOKEN
deepspeed --num_gpus 8 src/train_bash.py \
--deepspeed examples/deepspeed/ds_z3_config.json \
--stage orpo \
--do_train \
--model_name_or_path meta-llama/Meta-Llama-3-8B-Instruct \
--dataset dpo_mix_en,dpo_mix_zh \
--template llama3 \
--finetuning_type full \
--output_dir /opt/ml/checkpoints \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--log_level info \
--logging_steps 5 \
--save_strategy epoch \左右滑动查看完整示意
2. 执行 notebook.ipynb 开始训练,大约 7 小时可以完成训练,训练过程中以及完成后可以通过 Amazon SageMaker→Traing→TraingJobs 中对应任务查看训练进度,指标以及日志:
...
2024-04-29T18:08:46.490Z {'loss': 0.6692, 'grad_norm': 3.5630225761691583, 'learning_rate': 1.7401435318531444e-11, 'rewards/chosen': -0.03467336297035217, 'rewards/rejected': -0.08115329593420029, 'rewards/accuracies': 0.9750000238418579, 'rewards/margins': 0.046479929238557816, 'logps/rejected': -1.623065710067749, 'logps/chosen': -0.6934672594070435, 'logits/rejected': -0.48842868208885193, 'logits/chosen': -0.4446081221103668, 'sft_loss': 0.6934672594070435, 'odds_ratio_loss': 0.2594018280506134, 'epoch': 2.99}
...
2024-04-29T18:10:09.511Z {'train_runtime': 25889.5895, 'train_samples_per_second': 2.318, 'train_steps_per_second': 0.036, 'train_loss': 0.9441630041115304, 'epoch': 3.0}
2024-04-29T18:10:09.511Z #015 #015#015100%|██████████| 936/936 [7:11:29<00:00, 26.36s/it]#015100%|██████████| 936/936 [7:11:29<00:00, 27.66s/it]
2024-04-29T18:10:20.514Z [INFO|trainer.py:3305] 2024-04-29 18:10:20,252 >> Saving model checkpoint to /opt/ml/checkpoints左右滑动查看完整示意
3. 查看 Amazon S3 output path 可以看到训练完的模型以及训练的结果。
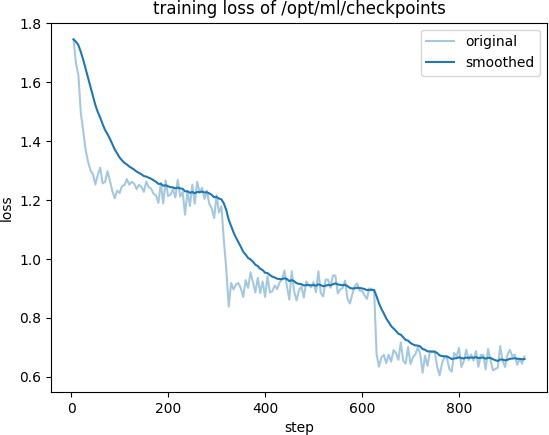
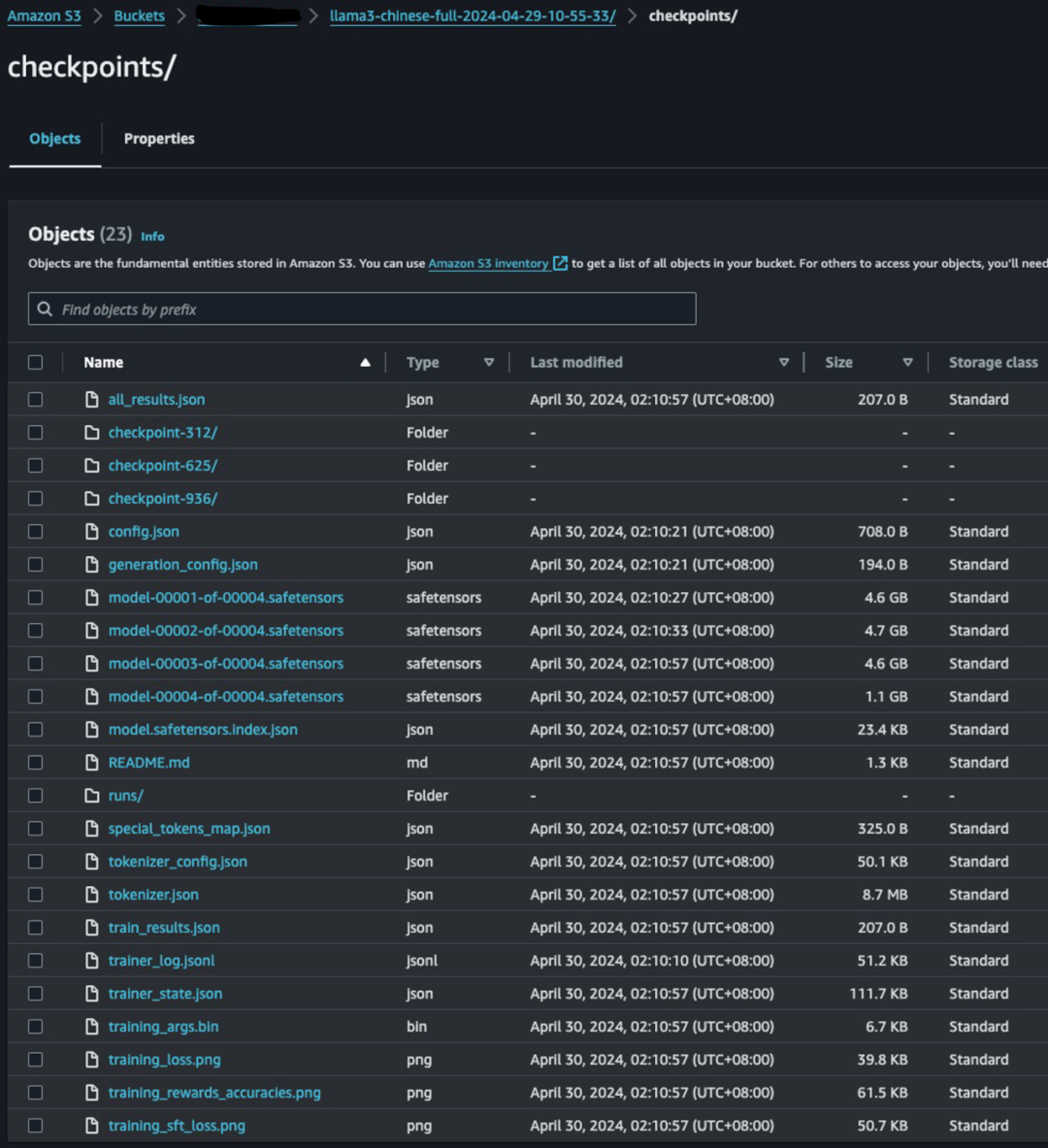
结果验证
我们可以把模型下载到本地运行的容器中进行快速验证:
# 把YOUR_S3_BUCKET以及JOB_ID替换为您使用的S3桶以及训练任务ID
aws s3 cp s3://YOUR_S3_BUCKET/JOB_ID/checkpoints/ /workspace/llama3-chinese/ --recursive --exclude="checkpoint*"左右滑动查看完整示意
from transformers import AutoTokenizer, AutoModelForCausalLM
# 包含模型的本地路径
model_id = "/workspace/llama3-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id, torch_dtype="auto", device_map="auto"
)
messages = [
{"role": "user", "content": "我的蓝牙耳机坏了,我该去看牙科还是耳鼻喉科?"},
]
input_ids = tokenizer.apply_chat_template(
messages, add_generation_prompt=True, return_tensors="pt"
).to(model.device)
outputs = model.generate(
input_ids,
max_new_tokens=8192,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))左右滑动查看完整示意
部署模型
当模型验证通过后,我们可以参考下方链接把模型部署成为一个 Amazon SageMaker Endpoint。
链接
https://www.philschmid.de/sagemaker-llama3
1. 压缩模型并上传到 Amazon S3:
tar --use-compress-program=pigz -cvf llama3-chinese.tar.gz -C ./llama3-chinese .
aws s3 cp llama3-chinese.tar.gz s3://YOUR_BUCKET/llama3-chinese.tar.gz左右滑动查看完整示意
2. 部署 Amazon SageMaker Endpoint:
import json
import sagemaker
from sagemaker.huggingface import HuggingFaceModel
sess = sagemaker.Session()
sm_role = sagemaker.get_execution_role()
llm_image = f"763104351884.dkr.ecr.{sess.boto_region_name}.amazonaws.com/huggingface-pytorch-tgi-inference:2.1-tgi2.0-gpu-py310-cu121-ubuntu22.04"
print(f"llm image uri: {llm_image}")
instance_type = "ml.g5.2xlarge"
health_check_timeout = 900
# 在SageMaker中,模型会被下载到/opt/ml/model中,因此使用这一本地路径作为模型路径
config = {
'HF_MODEL_ID':'/opt/ml/model',
'MAX_INPUT_LENGTH': "2048", # Max length of input text
'MAX_TOTAL_TOKENS': "4096", # Max length of the generation (including input text)
'MAX_BATCH_TOTAL_TOKENS': "8192", # Limits the number of tokens that can be processed in parallel during the generation
'MESSAGES_API_ENABLED': "true", # Enable the messages API
}
# 创建HuggingFaceModel,注意将YOUR_BUCKET替换为模型上传的S3桶
llm_model = HuggingFaceModel(
model_data='s3://YOUR_BUCKET/llama-chinese.tar.gz',
role=sm_role,
image_uri=llm_image,
env=config
)
# 将HuggingFaceModel创建为SageMaker Endpoint
# https://sagemaker.readthedocs.io/en/stable/api/inference/model.html#sagemaker.model.Model.deploy
llm = llm_model.deploy(
initial_instance_count=1,
instance_type=instance_type,
container_startup_health_check_timeout=health_check_timeout, # 10 minutes to be able to load the model
)左右滑动查看完整示意
3. 等待部署完成进行测试:
# 提示词
messages=[
{ "role": "system", "content": "你是个智能AI,小心回答用户的脑筋急转弯问题" },
{ "role": "user", "content": "我的蓝牙耳机坏了,我该去看牙科还是耳鼻喉科?" }
]
# 生成参数
parameters = {
"model": "meta-llama/Meta-Llama-3-8B-Instruct", # placholder, needed
"top_p": 0.8,
"temperature": 0.9,
"max_tokens": 512,
"stop": ["<|eot_id|>"],
}
chat = llm.predict({"messages" :messages, **parameters})
print(chat["choices"][0]["message"]["content"].strip())左右滑动查看完整示意
本篇作者

施俊
亚马逊云科技解决方案架构师,主要负责数字金融客户和企业级客户在亚马逊云科技上的架构设计与实施。10余年金融软件研发和机器学习经验。

张尹
亚马逊云科技技术客户经理,负责企业级客户的架构和成本优化、技术支持等工作。有多年的大数据架构设计、数仓建模等实战经验。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9413
9413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









