







在当今全球化的环境中,高质量的翻译服务变得越来越重要。大语言模型凭借其强大的语言理解和生成能力,在翻译任务中表现出色。通过精心设计的提示词(Prompt),LLM能够更好地理解翻译场景,产出符合特定业务需求的翻译结果。然而,在涉及大量专业术语的特定领域中,LLM的原生翻译能力往往显得力不从心。
本文将探讨如何结合多个亚马逊云科技服务来增强LLM的翻译能力,特别是在处理专业术语时的表现。
专业术语翻译的挑战
在诸如法律、医疗、游戏等垂直领域,存在大量的术语和专有名词。这些词汇在不同语言中往往有其特定的表达方式,而这些表达并不总是可以通过字面意思直接翻译。LLM在处理这些专业术语时,可能会产生不准确或不恰当的翻译,影响整体翻译质量。
以下是游戏场景中的两个专词,通过翻译工具直接进行翻译无法得到预期的结果:
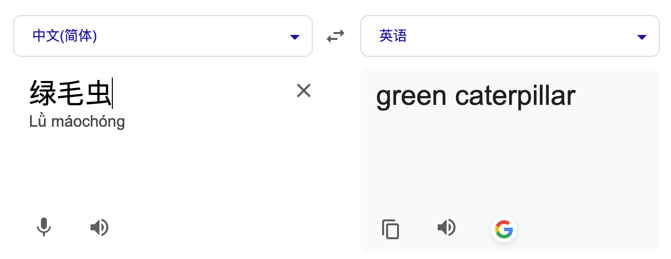
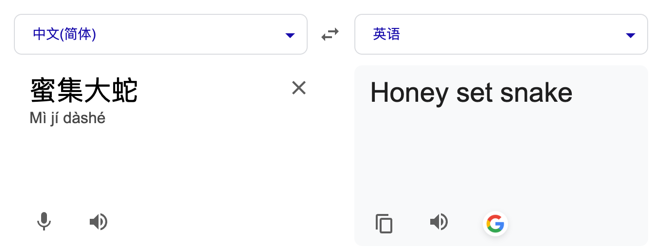
在一般场景、专词不多的情况下,我们直接把专词映射固化在提示词中就能很好地解决这个问题。
但是如果专词量比较大,那么直接固化在提示词中会导致提示词过长,首先导致翻译的成本大大增加,而且由于引入了太多无关的映射,也会影响大语言模型对于相关内容的注意力,所以在翻译的流程中,我们必须利用RAG的思想,把翻译相关的专词映射元信息召回回来,融合到Prompt中。
方案介绍
为了解决上述挑战,我们提出了一个包含Amazon DynamoDB、Amazon Glue和Amazon Bedrock等服务的解决方案。其中Amazon DynamoDB作为一个快速、灵活的KV数据库服务,非常适合存储和管理这些专业术语及其对应的翻译;Amazon Glue则是一个轻量无服务器的一个离线任务引擎,非常适合做离线的数据处理,而Amazon Bedrock作为大语言模型平台,负责提供模型能力。下图是整个方案的产品架构图:
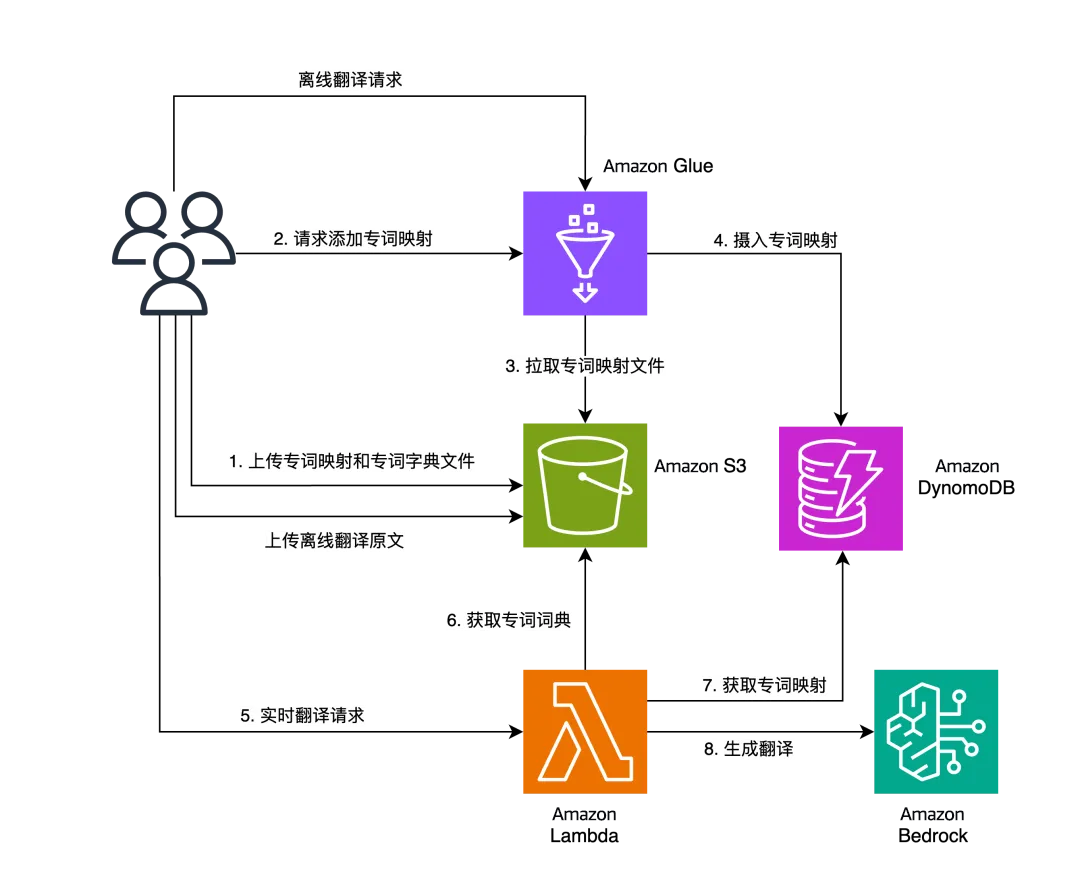
产品交互流程主要存在两路:离线流程和在线流程。
离线流程为图中的1-4步,需要用户上传自己的多语言专词映射关系表和专词字典(分词所需)到Amazon S3桶,启动离线的Amazon Glue Job拉取解析多语言专词映射关系表,并以专词为键摄入到Amazon DynamoDB中去。
在线流程为5-8步,用户直接访问Amazon Lambda的在线接口,Amazon Lambda在预热过程会拉取并加载Amazon S3中的分词专词词典文件,对请求翻译的文本进行切词,切词结果仅仅保留专词部分,然后从Amazon DynamoDB中获取其对应的多语言映射关系,构造出翻译的Prompt,最后触发Amazon Bedrock LLM的生成接口。
整个方案除了提供在线的翻译接口,针对大批量的翻译,也提供了基于Amazon Glue Job这种离线任务的接口,区别于在线接口,具备以下优势:
可以按照文件级别进行并发生成翻译
具备任务执行追踪以及重试的能力
技术细节问题
1.文本过长怎么办?
大语言模型翻译受到模型输出Token数量的限制(通常为4,096个Tokens)。因此,对于长文本,我们需要首先进行切分处理。对于大多数情况下的翻译来说,按照段落进行拆分是比较合适的策略,这个步骤确保了我们可以处理任意长度的文本,而不受模型限制的影响。
2.为什么采用切词的办法来召回翻译文本中的专词映射?
在实践中,最早有考虑基于Amazon OpenSearch这类典型RAG引擎来做,但需要全文检索方式来召回专词映射,基于Bm25打分-Bm25打分容易受到翻译内容在Amazon OpenSearch内置切词中产生的一些不相关词汇的干扰。而语义召回,则更不具备精准性,不适应用来召回专词映射。另外一个考虑因素,本方案是一个轻量的无服务器方案,暂未引入量级相对重的服务。
基于专词的文本精准匹配才是更恰当的方式,在具体实现时,直接通过字符串匹配去遍历所有专词是一种简单的方式,但是你会发现它的效率比较低下,且容易出现误匹配。如下面例子:
专词:gg(good game)
翻译原文:In the new action-adventure game, players must juggle multiple weapons and abilities to defeat increasingly challenging enemies.
可以看出在字符串匹配时对于较短的专词可能会匹配到待翻译内容的部分字符。
利用基于词表的切词方法则能够避免这种问题,更加精准地获取到期望的专词映射,且效率更高。
部署与测试
1.Amazon CDK部署运行环境准备
连接到一台Amazon EC2,并执行下面的命令去准备Amazon CDK环境。
# 安装nodejs 18
sudo yum install https://rpm.nodesource.com/pub_18.x/nodistro/repo/nodesource-release-nodistro-1.noarch.rpm -y
sudo yum install nodejs -y --setopt=nodesource-nodejs.module_hotfixes=1 --nogpgcheck
# 安装&启动docker
sudo yum install docker -y
sudo service docker start
sudo chmod 666 /var/run/docker.sock
#安装aws-cdk
sudo npm install -g aws-cdk
sudo npm install --global yarn左右滑动查看完整示意
2.下载代码并进行部署
执行下面命令进行自动化部署。
https://github.com/aws-samples/rag-based-translation-with-dynamodb-and-bedrock.git
cd rag-based-translation-with-dynamodb-and-bedrock/deploy/
#设置当前region,需手动修改这个变量,如us-east-1
export region=${region}
sh gen_env.sh ${region}
npm install
cdk bootstrap
# 执行部署
cdk deploy --require-approval never RagTranslateStack左右滑动查看完整示意
部署完毕后,会产生一个Amazon Lambda Function – translate_tool和一个Amazon Glue Job– ingest_knowledge2ddb,分别是在线翻译的入口和离线专词映射注入入口。
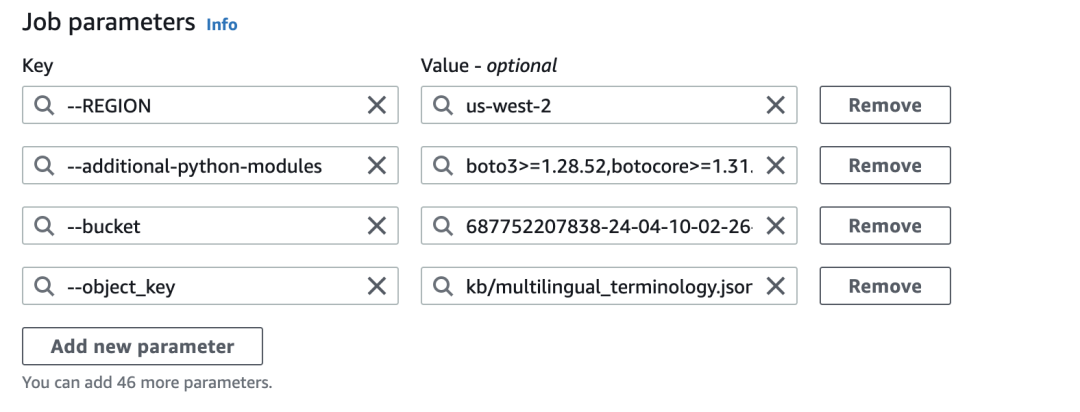
3.摄入专词映射和准备专词字典
专词映射文件需要放到Amazon S3指定目录,再执行ingest_knowledge2ddb这个Amazon Glue Job把元数据导入到Amazon DynamoDB。映射文件的路径通过Amazon Glue Job的执行参数进行设置,请注意保证Bukect与Object_key的设置正确。如下图所示:
专词字典只需要拷贝到指定Amazon S3路径,Amazon Lambda会从这个路径下载到运行环境的本地路径中。
4.翻译接口测试
进入Lambda Function–translate_tool的Test选项卡中。参考使用下面的Payload进行测试。
{
"src_content":"奇怪的渔人吐司可以达到下面效果,队伍中所有角色防御力提高88点,持续300秒。多人游戏时,仅对自己的角色生效。《原神手游》赤魔王图鉴,赤魔王能捉吗",
"src_lang":"CHS",
"dest_lang":"EN",
"request_type":"translate",
"model_id":"anthropic.claude-3-sonnet-20240229-v1:0"
}左右滑动查看完整示意
测试效果如下图所示:
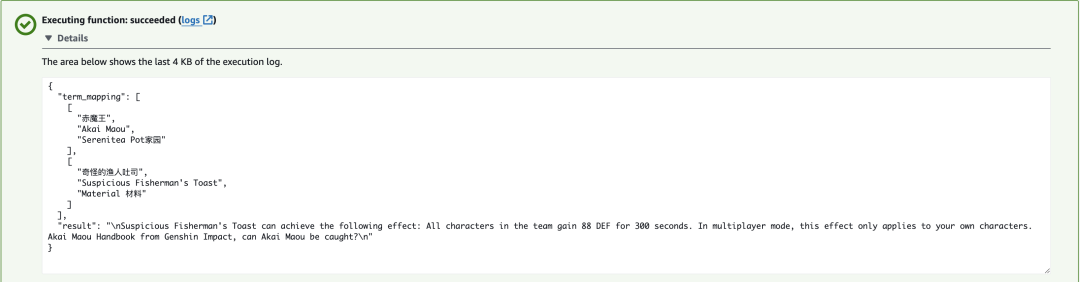
该Amazon Lambda为了提供灵活性支持了三种不同的调用方式,除了翻译内容以外,还可以支持获取专词映射和仅切词,通过切换request_type参数来进行切换。
总结
本文介绍了具备专词映射能力的翻译方案,通过引入这个轻量的方案,以低成本的方式有效的解决了大量专词场景下的翻译问题。在游戏客户的场景中,通过这种方式在翻译过程中从几十万专词映射中动态的引入相关的映射关系,大大改善了翻译质量,在多种语言的人工评估中得到明显提升。
但在翻译场景中,不仅仅存在专词映射能力的问题。各种细分场景更加复杂,还包括比如文件翻译、图片翻译、广告词翻译等需要复杂上下文引入和LLM流程编排的翻译场景。如何更好地解决以上各种场景,还需要进一步实践和总结。

相关代码
代码库
https://github.com/aws-samples/rag-based-translation-with-dynamodb-and-bedrock



本篇作者

李元博
亚马逊云科技解决方案架构师,专注于人工智能和机器学习,特别是生成式AI场景落地的端到端架构设计和业务优化。在互联网行业工作多年,对用户画像、精细化运营、推荐系统、大数据处理方面有丰富的实战经验。

韩医徽
亚马逊云科技资深解决方案架构师,曾负责亚马逊云科技合作伙伴生态系统的云计算方案架构咨询和设计,现负责游戏行业技术架构设计和支持,同时致力于亚马逊云科技云服务的应用和推广。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9440
9440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









