







继推出可将训练基础模型(FM)的时间缩短多达40%的Amazon SageMaker HyperPod后,在近日落幕的re:Invent 2024,亚马逊云科技再度重磅推出Amazon SageMaker HyperPod recipes。
通过访问经过优化的recipes,Amazon SageMaker HyperPod recipes帮助数据科学家和开发者训练和微调常用的公开FM,将训练时间再缩短至几分钟!
SageMaker HyperPod recipes包括由亚马逊云科技测试的训练堆栈,可自动执行加载训练数据集等多个关键步骤,从而省去了尝试不同模型配置的繁琐工作与耗时数周的迭代评估和测试。
通过简单的recipes更改,即可在基于GPU或Trainium的实例之间无缝切换,进一步优化训练性能并降低成本。也让生产环境中的工作负载能在Amazon SageMaker HyperPod或SageMaker训练作业上轻松运行。
SageMaker HyperPod
recipes实际应用
要开始使用,请访问SageMaker HyperPod recipes GitHub存储库,浏览常用公开FM的训练recipes。
SageMaker HyperPod recipes GitHub存储库:
https://github.com/aws/sagemaker-hyperpod-recipes
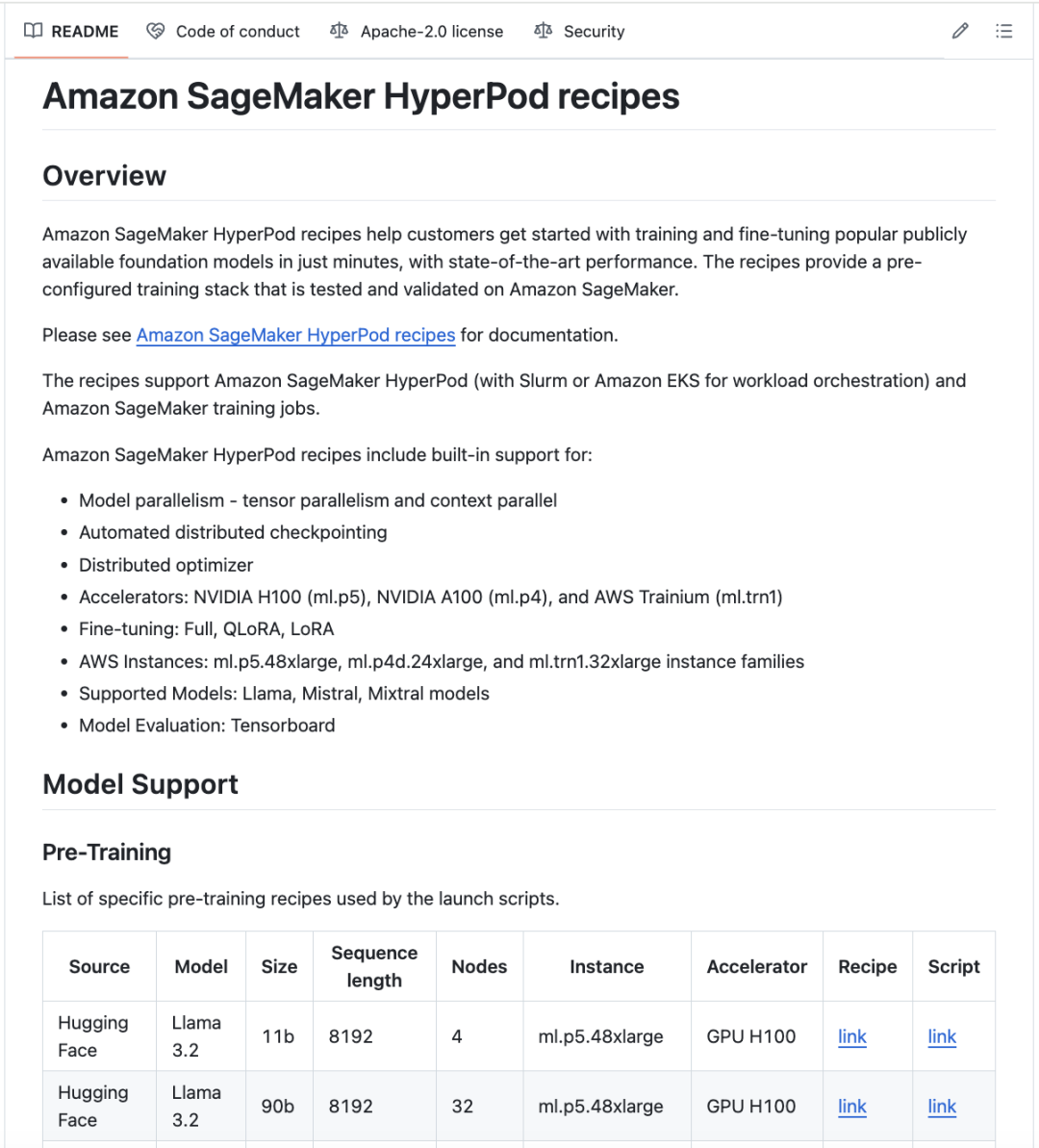
您只需要编辑简单的recipes参数来指定实例类型和数据集在集群配置中的位置,然后使用单行命令运行recipes即可实现先进的性能。
克隆存储库后,需要编辑recipes config.yaml文件,指定模型和集群类型。
$ git clone --recursive https://github.com/aws/sagemaker-hyperpod-recipes.git
$ cd sagemaker-hyperpod-recipes
$ pip3 install -r requirements.txt.
$ cd ./recipes_collections
$ vim config.yaml左右滑动查看完整示意
这些recipes支持带有Slurm的SageMaker HyperPod、带有Amazon Elastic Kubernetes Service(Amazon EKS)的SageMaker HyperPod以及SageMaker训练作业。您可以设置集群类型(Slurm编排工具)、模型名称(Meta Llama 3.1 405B语言模型)、实例类型(ml.p5.48xlarge)和数据位置,例如存储训练数据、结果、日志等。
defaults:
- cluster: slurm # support: slurm / k8s / sm_jobs
- recipes: fine-tuning/llama/hf_llama3_405b_seq8k_gpu_qlora # name of model to be trained
debug: False # set to True to debug the launcher configuration
instance_type: ml.p5.48xlarge # or other supported cluster instances
base_results_dir: # Location(s) to store the results, checkpoints, logs etc.左右滑动查看完整示意
您可以选择调整此YAML文件中特定于模型的训练参数,该文件概述了最佳配置,包括加速器设备的数量、实例类型、训练精度、并行化和分片技术、优化器以及通过TensorBoard监控实验的日志记录。
run:
name: llama-405b
results_dir: ${base_results_dir}/${.name}
time_limit: "6-00:00:00"
restore_from_path: null
trainer:
devices: 8
num_nodes: 2
accelerator: gpu
precision: bf16
max_steps: 50
log_every_n_steps: 10
...
exp_manager:
exp_dir: # location for TensorBoard logging
name: helloworld
create_tensorboard_logger: True
create_checkpoint_callback: True
checkpoint_callback_params:
...
auto_checkpoint: True # for automated checkpointing
use_smp: True
distributed_backend: smddp # optimized collectives
# Start training from pretrained model
model:
model_type: llama_v3
train_batch_size: 4
tensor_model_parallel_degree: 1
expert_model_parallel_degree: 1
# other model-specific params左右滑动查看完整示意
要在带有Slurm的SageMaker HyperPod中运行recipes,您必须按照集群设置说明准备SageMaker HyperPod集群。
然后连接到SageMaker HyperPod头节点,访问Slurm控制器,复制编辑后的recipes。接下来运行帮助文件为作业生成Slurm提交脚本,可以使用该脚本进行试运行,在开始训练作业之前检查内容。
$ python3 main.py --config-path recipes_collection --config-name=config左右滑动查看完整示意
训练完成后,经过训练的模型将自动保存到指定的数据位置。
要在带有Amazon EKS的SageMaker HyperPod上运行recipes,需要从GitHub存储库中克隆recipes,安装要求的组件,然后在笔记本电脑上编辑recipes(cluster: k8s)。然后在笔记本电脑和运行EKS集群之间创建链接,随后使用HyperPod命令行界面(CLI)运行recipes。
$ hyperpod start-job –recipe fine-tuning/llama/hf_llama3_405b_seq8k_gpu_qlora \
--persistent-volume-claims fsx-claim:data \
--override-parameters \
'{
"recipes.run.name": "hf-llama3-405b-seq8k-gpu-qlora",
"recipes.exp_manager.exp_dir": "/data/<your_exp_dir>",
"cluster": "k8s",
"cluster_type": "k8s",
"container": "658645717510.dkr.ecr.<region>.amazonaws.com/smdistributed-modelparallel:2.4.1-gpu-py311-cu121",
"recipes.model.data.train_dir": "<your_train_data_dir>",
"recipes.model.data.val_dir": "<your_val_data_dir>",
}'左右滑动查看完整示意
您还可以使用SageMaker Python SDK在SageMaker训练作业上运行recipes。以下示例使用覆盖训练recipes在SageMaker训练作业上运行PyTorch训练脚本。
...
recipe_overrides = {
"run": {
"results_dir": "/opt/ml/model",
},
"exp_manager": {
"exp_dir": "",
"explicit_log_dir": "/opt/ml/output/tensorboard",
"checkpoint_dir": "/opt/ml/checkpoints",
},
"model": {
"data": {
"train_dir": "/opt/ml/input/data/train",
"val_dir": "/opt/ml/input/data/val",
},
},
}
pytorch_estimator = PyTorch(
output_path=<output_path>,
base_job_name=f"llama-recipe",
role=<role>,
instance_type="p5.48xlarge",
training_recipe="fine-tuning/llama/hf_llama3_405b_seq8k_gpu_qlora",
recipe_overrides=recipe_overrides,
sagemaker_session=sagemaker_session,
tensorboard_output_config=tensorboard_output_config,
)
...左右滑动查看完整示意
随着训练的进行,模型检查点存储在具有全自动检查点功能的Amazon Simple Storage Service(Amazon S3)中,从而可以更快地从训练错误和实例重启中恢复。
现已推出
Amazon SageMaker HyperPod recipes现已在Amazon SageMaker HyperPod recipes GitHub存储库中推出。您可访问Amazon SageMaker HyperPod产品页面和Amazon SageMaker AI开发人员指南,了解更多详细信息。
Amazon SageMaker HyperPod:
https://aws.amazon.com/cn/sagemaker-ai/hyperpod/
Amazon SageMaker AI开发人员指南:
https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-hyperpod.html




星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文,获得更详细内容!


















 9440
9440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









