







Amazon Bedrock Guardails是亚马逊云科技唯一一项负责任的AI功能,通过过滤不良内容、删除个人身份信息(PII)以及增强内容安全性和隐私性,为生成式AI应用构建和定制安全性、隐私性和真实性保障。
Amazon Bedrock Guardrails增加自动推理检查功能(预览版),可从数学角度验证大语言模型(LLMs)所生成响应的准确性,并防止因幻觉而产生事实错误。
自动推理检查通过基于数学原理和逻辑算法的验证与推理机制,核实模型生成信息,有效避免因幻觉导致的事实错误,确保输出结果与已知事实相吻合。
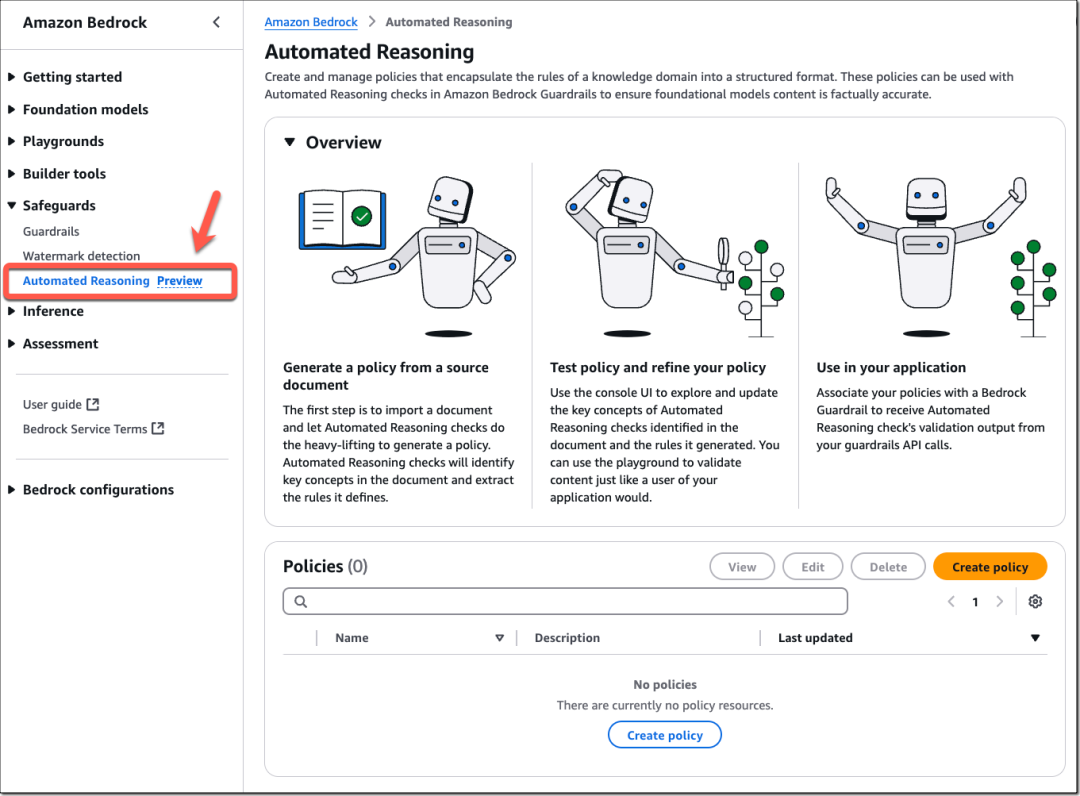
自动推理概述
自动推理是计算机科学的一个领域,它利用数学证明和逻辑演绎来验证系统和程序的行为。与进行预测的机器学习不同,自动推理能为系统行为提供数学保证。
亚马逊云科技已将自动推理应用于存储、网络、虚拟化、身份识别和密码学等关键服务领域。例如将自动推理用于正式验证加密实现的正确性,从而提高性能和开发速度。要了解更多信息,请查阅Amazon Science博客中的“可证明安全性”和“自动推理”研究领域。
自动推理:
https://aws.amazon.com/what-is/automated-reasoning/
可证明安全性研究:
https://aws.amazon.com/security/provable-security/
自动推理研究:
https://www.amazon.science/research-areas/automated-reasoning
亚马逊云科技正将类似方法应用于生成式AI。Amazon Bedrock Guardrails中全新的自动推理检查(预览版),是首个也是唯一一项生成式AI保障措施,它使用逻辑准确且可验证的推理来解释生成式AI响应正确的原因,从而有助于防止因幻觉导致的事实错误。自动推理检查在追求事实精准与解释清晰的用例中尤为奏效,例如您可使用自动推理检查来验证大语言模型(LLM)生成的人力资源政策、公司产品信息或运营工作流程等响应的准确性。
与提示词工程、检索增强生成(RAG)和上下文定位检查等其他技术结合使用时,自动推理检查提供了一种更为严谨且可验证的方法,旨在确保大语言模型生成的输出与事实准确相符。通过将领域知识编码为结构化策略,您可以确信对话式AI应用正在向用户提供可靠且值得信赖的信息。
在Amazon Bedrock Guardrails中
使用自动推理检查(预览版)
借助Amazon Bedrock Guardrails中的自动推理检查功能,您可以创建自动推理策略,将组织的规则、程序和准则编码为结构化的数学格式,这些策略可用于来验证由大语言模型驱动的应用程序生成的内容是否符合准则。
自动推理策略由一组具有名称、类型和描述的变量及其逻辑规则组成,规则在幕后以形式逻辑表达,但为了方便不具备形式逻辑专业知识的用户优化模型,规则会转换为自然语言。在进行问答验证时,自动推理检查会使用变量描述来提取其值。
下文将介绍其工作原理。
创建自动推理策略
通过Amazon Bedrock控制台,您可以上传描述组织规则和程序的文档,Amazon Bedrock将分析这些文档,并自动创建初始自动推理策略,该策略以数学形式表示关键概念及其关系。
Amazon Bedrock控制台:
https://console.aws.amazon.com/bedrock/home
在“Safeguards”中找到新的“自动推理”菜单项,创建一个新策略并为其命名,并上传一份定义了正确解决方案空间的现有文档,例如人力资源指南或操作手册。本演示将使用一个机票策略文档,其中包括航空公司的机票更改策略。
然后,定义策略的目的和任何处理参数。例如,指定它是否验证机场工作人员的查询,并确定处理中应排除的任何要素,如内部参考编号,并且包括一个或多个示例问答,以帮助系统理解典型的交互。
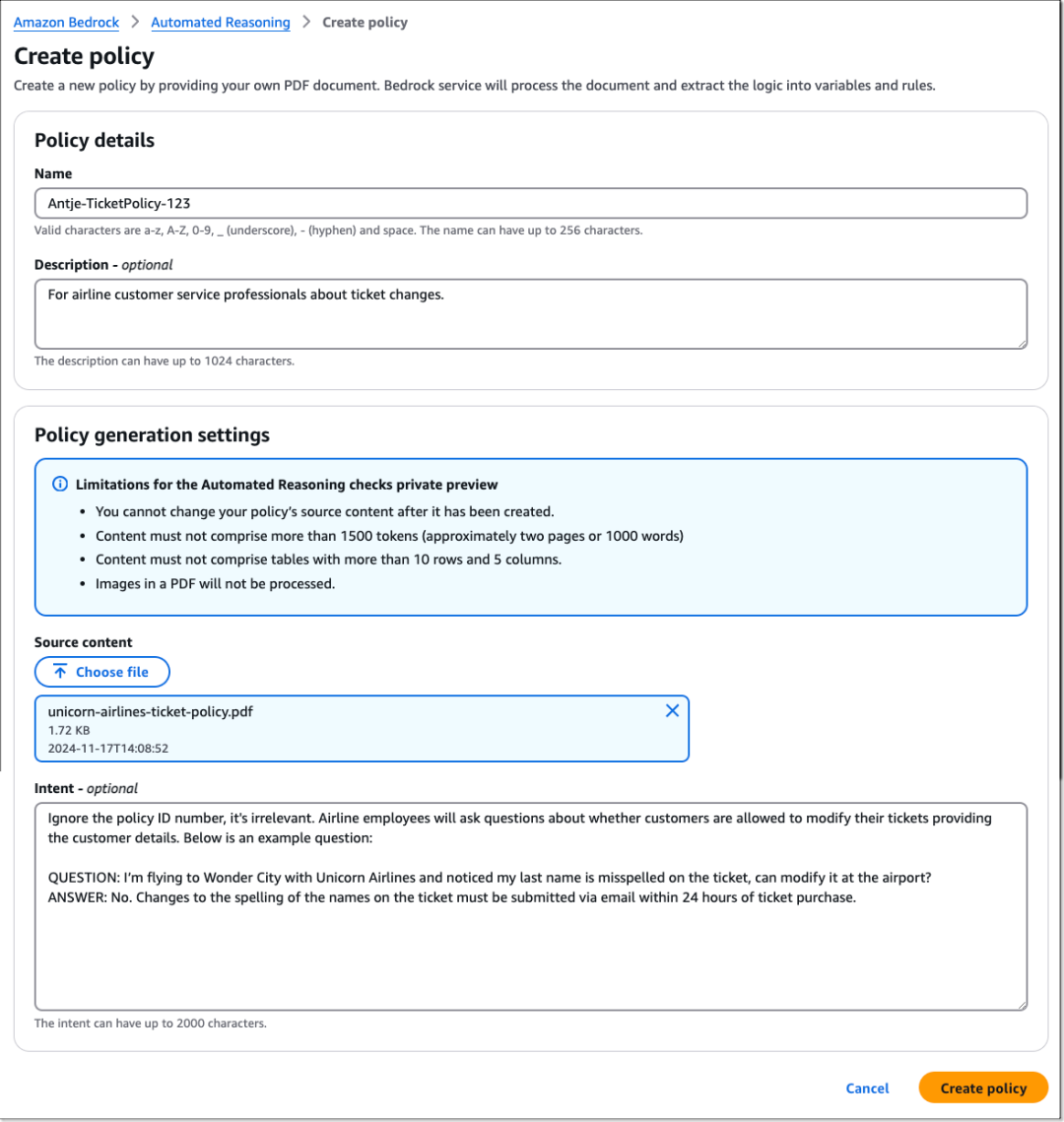
以下为目的说明。
忽略无关的保单号,航空公司员工会询问客户是否可以修改机票,届时需要提供客户的详细信息,以下为一个示例问题。
问题:我将乘坐Unicorn航空飞往奇幻城,但突然发现机票上的姓氏拼写错误,可以在机场修改吗?
回答:不可以。机票上姓名拼写的更改必须在购票后24小时内通过电子邮件提交。
然后选择创建。
系统将启动自动流程,创建自动推理策略。这一过程包括分析文档、识别关键概念、将文档拆分为单个单元、将自然语言单元转换为形式逻辑、验证转换结果,最终组合成一个全面的逻辑模型。完成后,请查看生成的包括规则和变量在内的结构,并可通过用户界面编辑这些内容,以确保准确性。
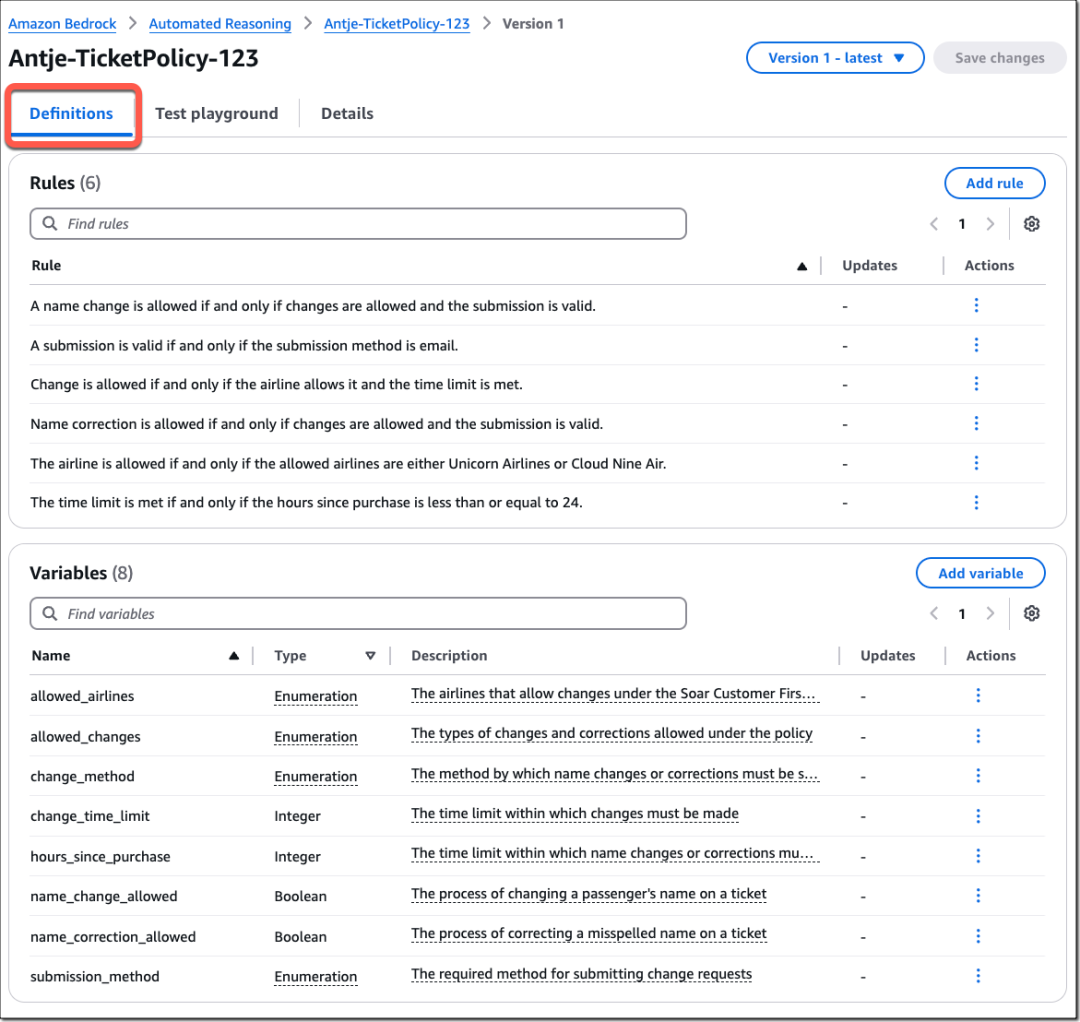
要测试自动推理策略,首先需要创建一个防护机制。
创建防护机制
配置自动推理检查
在使用Amazon Bedrock Guardrails构建对话式AI应用程序时,您可以启用自动推理检查,并指定要使用哪些自动推理策略进行验证。
导航至“Safeguards”中的“Guardrails”菜单项,创建一个新的防护机制并为其命名。选择“启用自动推理策略”,并选择您要使用的策略及策略版本,然后完成防护机制配置。
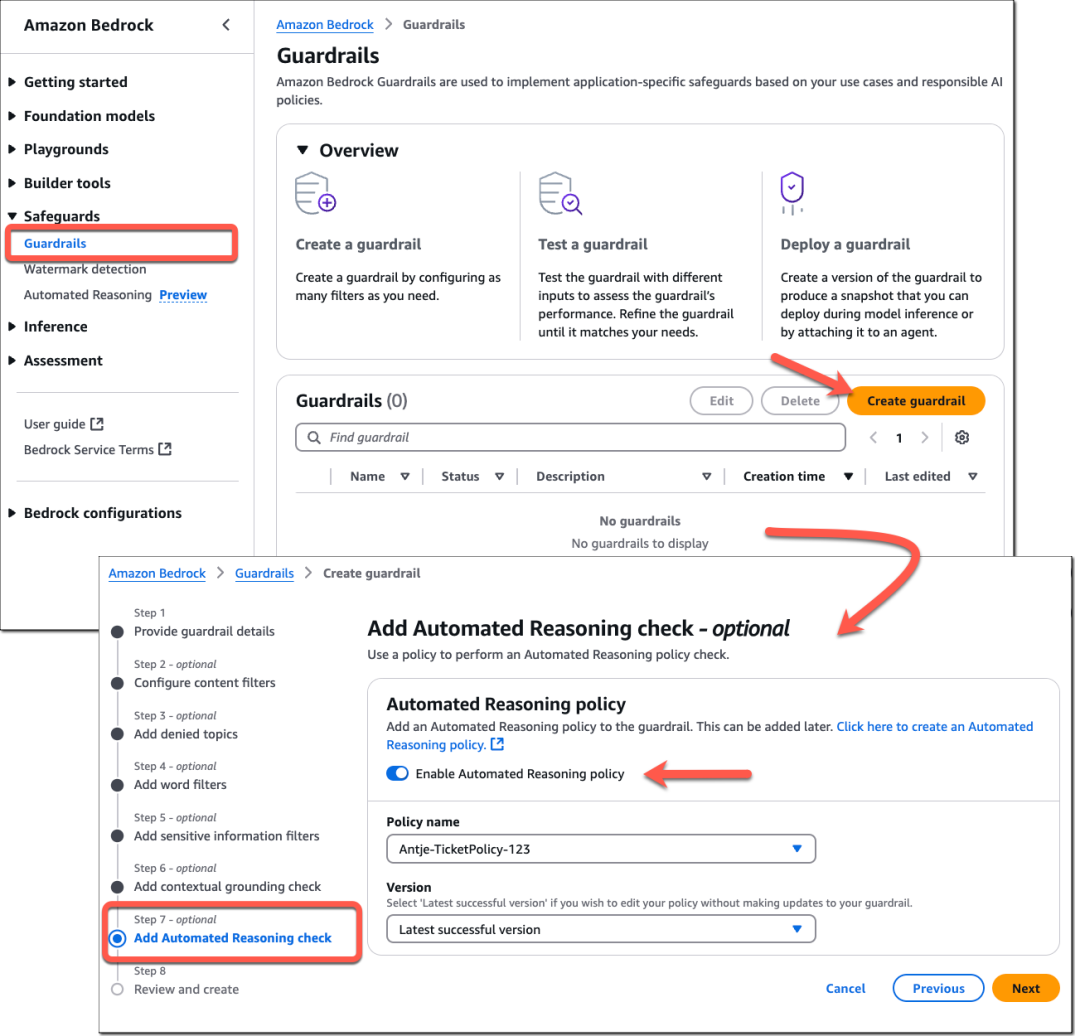
测试自动推理检查
您可以使用自动推理控制台中的“测试平台”来验证自动推理策略的有效性,您可像应用程序用户一样输入测试问题,并提供一个示例答案以供验证。
本演示特意输入了一个错误答案,看看测试会发生什么。
问题:我乘坐Unicorn航空飞往奇幻城,发现机票上的姓氏拼写错误,现在已经在机场,可以现场提交更改吗?
回答:可以。您可以在任何时候更改机票上的姓名,即使已经到达机场现场也可以更改。
然后,选择您刚刚创建的防护机制并选择提交。
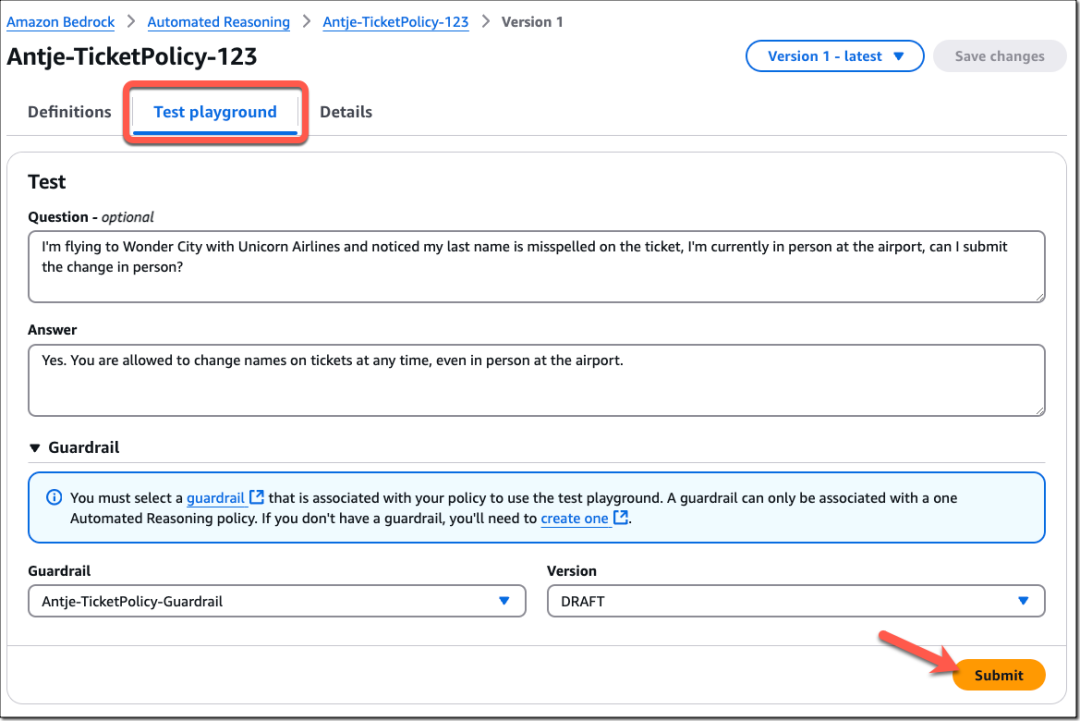
自动推理检查将分析内容,并根据您配置的自动推理策略进行验证。检查将识别任何与事实不符或不准确的内容,并为验证结果提供解释。
在本演示中,自动推理检查正确识别出该响应无效,并显示了导致该结果的规则原因,以及提取的变量和建议。
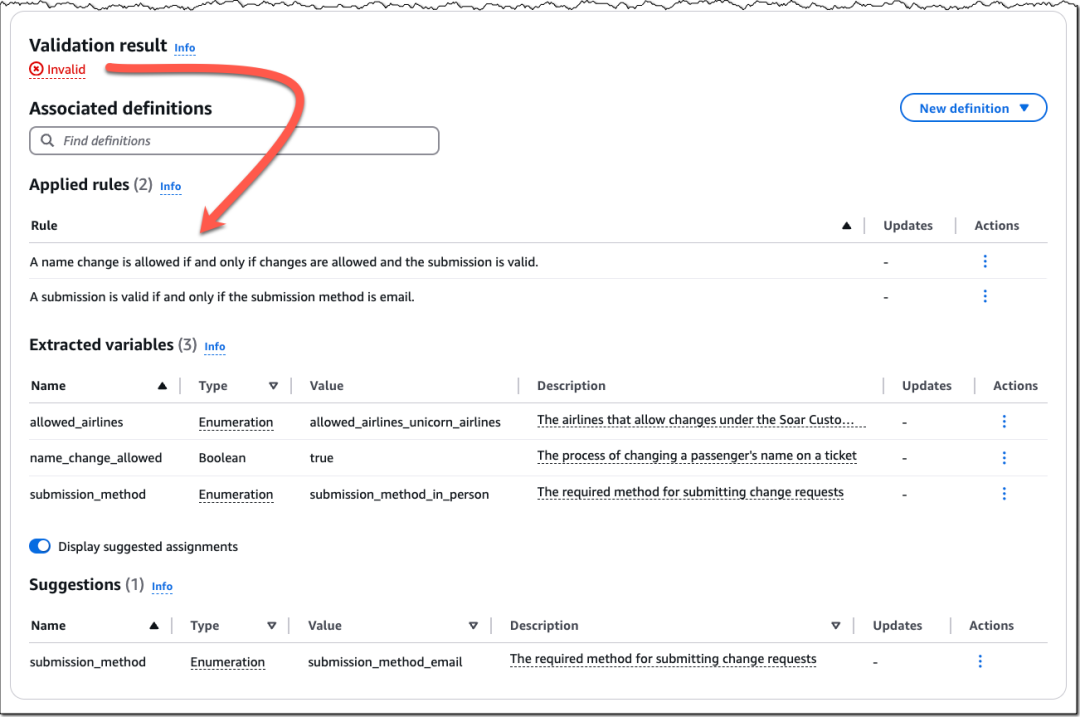
当验证结果为无效时,生成建议会显示一组使结论变为有效的变量赋值。在本演示中,建议显示要使验证结果有效,提交更改方法必须是电子邮件。
如果没有检测到任何事实上的不准确之处,并且验证结果为有效,则建议会显示一系列结果成立所必需的赋值,这些是答案中未说明的假设。在本演示中,这可能是诸如必须在原始机票上进行姓名更正或机票类型符合更改要求等假设。
当检测到与事实的不一致之处时,控制台将显示混合结果作为验证结果。在API响应中,您将看到一系列结果,其中一部分被标记为有效,另一部分被标记为无效。如果出现这种情况,请检查系统的发现和建议,并编辑任何不清晰的策略规则。
您还可以根据反馈,利用验证结果来增强LLM生成的响应。例如,以下代码片段演示了如何要求模型根据收到的反馈重新生成答案。
for f in findings:
if f.result == "INVALID":
if f.rules is not None:
for r in f.rules:
feedback += f"<feedback>{r.description}</feedback>\n"
new_prompt = (
"The answer you generated is inaccurate. Consider the feedback below within "
f"<feedback> tags and rewrite your answer.\n\n{feedback}"
)左右滑动查看完整示意
实现高验证准确性是一个迭代过程,最佳做法是定期检查策略性能并按需调整。您可以用自然语言编辑规则,系统将自动更新逻辑模型。
例如,更新变量描述可以显著提高验证准确性。以这一场景为例:一个问题表述为“我是一名全职(full-time)员工……”,而is_full_time变量的描述仅表述为“每周工作超过20小时”。在这种情况下,自动推理检查可能无法识别“全职”这一表述。为了提高准确性,您应该更新变量描述,使其更加全面,例如:“每周工作超过20小时,用户可能将其称为全职或兼职。对于全职,该值应为true;对于兼职,该值应为false。”这种详细描述有助于系统识别自然语言问题,和在答案中提取所有相关的事实陈述进行验证,从而提供更准确的结果。
自动推理检查防护功能(预览版)
现已可用
新的自动推理检查防护功能已在Amazon Bedrock Guardrails中以预览版形式推出,可在美国西部(俄勒冈州)亚马逊云科技区域使用。
本篇作者

Antje Barth
亚马逊云科技生成式AI首席开发者布道师。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9442
9442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









