







题目:离散特征的独热编码
1. 读取data数据
2. 对所有缺失值进行填充
3. 对离散变量进行one-hot编码
4. 对独热编码后的变量转化为int类型
离散特征可以进行标签编码(有顺序等级关系)和独热编码(无顺序等级关系)
一、独热编码使用示例
1. 读取data数据
# 读取数据
import pandas as pd
data = pd.read_csv('data.csv')# 输出所有离散特征
for discrete_feature in data.columns:
if data[discrete_feature].dtype == 'object':
print(discrete_feature)输出:
Home Ownership
Years in current job
Purpose
Term有四个离散特征:
1. Home Ownership :住房所有情况
2. Years in current job :当前工作年限
3. Purpose :目的
4. Term :期限
注:如何判断离散特征
离散特征(离散变量)通常可以分为两大类:
定序变量(OrdinalVariable):类别之间存在明确的顺序或等级关系。
1.教育程度(小学、初中、高中、大学)
2.满意度评分(非常不满意、不满意、一般、满意、非常满意)
3. 收入等级(低、中,高)
名义变量(NominalVariable):类别之间没有顺序或等级关系,仅仅是不同的类别,名义
变量的类别是平等的,没有高低之分
1. 颜色(红、绿、蓝)
2. 城市(北京、上海、广州)
3.性别(男、女)
int 或 float 类型的特征 可能是离散特征 ,具体取决于其 实际含义和取值是否有限且不连续 ,而非仅由数据类型决定。例如:
- int 类型的“购买次数”(1/2/3次)是离散特征;
- float 类型的“精确温度”(25.3℃/25.4℃)是连续特征;
- float 类型的“固定评分”(1.0/2.0/3.0)是离散特征(尽管不常见)。
以其中一个离散特征Home Ownership为例:
# value_counts()统计每个类别的个数,查看不同类别之间的关系,判断使用标签编码还是独热编码
data['Home Ownership'].value_counts()输出:
Home Ownership
Home Mortgage 3637
Rent 3204
Own Home 647
Have Mortgage 12
Name: count, dtype: int641. Home Mortgage 住房抵押贷款
2. Rent 租房
3. Own Home 自有住房
4. Have Mortgage 有抵押贷款
2.进行独热编码
# 无循序关系,可使用独热编码
# pd.get_dummies(待处理数据集, columns= ['待处理列']),dummy虚拟->dummies
data = pd.get_dummies(data, columns= ['Home Ownership'])
data.columns输出:
Index(['Id', 'Annual Income', 'Years in current job', 'Tax Liens',
'Number of Open Accounts', 'Years of Credit History',
'Maximum Open Credit', 'Number of Credit Problems',
'Months since last delinquent', 'Bankruptcies', 'Purpose', 'Term',
'Current Loan Amount', 'Current Credit Balance', 'Monthly Debt',
'Credit Score', 'Credit Default', 'Home Ownership_Have Mortgage',
'Home Ownership_Home Mortgage', 'Home Ownership_Own Home',
'Home Ownership_Rent'],
dtype='object')可查看,原列名Home Ownership替换为了
1. 'Home Ownership_Have Mortgage'
2. 'Home Ownership_Home Mortgage'
3. 'Home Ownership_Own Home'
4. 'Home Ownership_Rent'
查看前5行,新特征下是bool类型
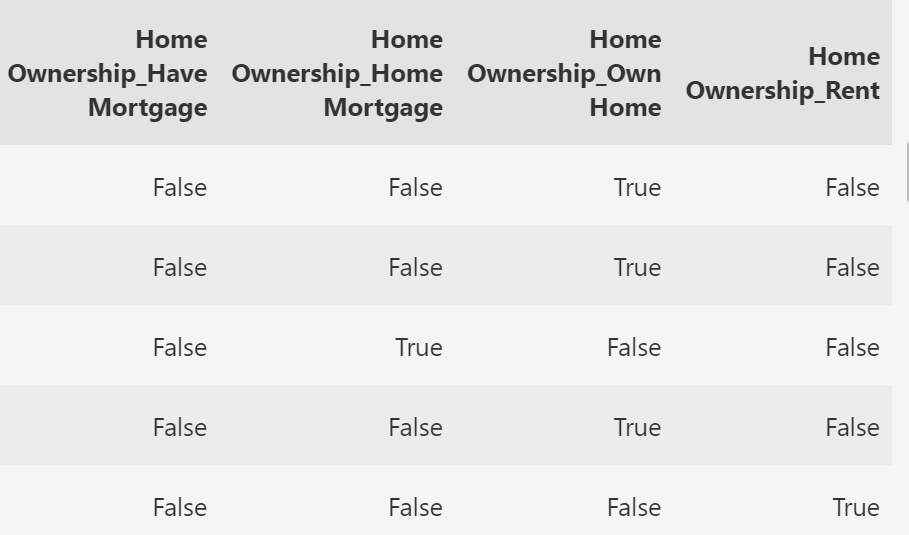
注:
1、get_dummies()函数
dummies是dummy的复数形式,有虚拟的意思
get_dummies(<待处理原始数据集>, columns=<需要处理的列>, drop_first=True)
drop_first=True表示删除第一列,若原特征S编码后的新特征若为A,B,C三列,则删除第一列后只有B,C两列,减少冗余。
2、理解独热编码的过程
独热编码就可以解决这个问题。它会把每个类别用一个 只有一位是 1,其他位都是 0 的向量来表示。对于我们的动物分类例子,就可以这样进行独热编码:
猫:[1, 0, 0]
狗:[0, 1, 0]
猪:[0, 0, 1]
这样每个动物都有了一个独一无二的编码,而且编码之间没有大小关系和不合理的距离计算问题。计算机在处理数据时,就能清楚地知道每个编码代表的是不同的类别,不会产生误解。
3.编码后新特征bool型转换为int型
# 独热编码后内容是bool型,需要转化为int型,以Home Ownership_Have Mortgage为例
# 使用astype()方法,即as type
data['Home Ownership_Have Mortgage'] = data['Home Ownership_Have Mortgage'].astype(int)
输出:

到此为止,已经掌握了对离散变量进行独热编码的所有方法
二、对所有离散特征进行独热编码(分步)
注:本数据集所有离散特征下的类别均无顺序关系,故只进行独热编码即可,无需进行标签编码
首先,填补缺失值,然后
1. 找到离散变量
2. 进行独热编码
3. 转换成int型
# 重新读取数据
data = pd.read_csv('data.csv')
# 先 进行缺失值补全
for i in data.columns:
if data[i].isnull().sum() > 0:
# 使用第一个众数补全
mode = data[i].mode()[0]
data[i].fillna(mode, inplace=True)
# 找到所有的离散变量
# 创建一个空列表,用于存储离散变量的列名
discrete_lists = []
for i in data.columns:
if data[i].dtype == 'object':
discrete_lists.append(i)
# 对所有离散变量进行独热编码
# drop_first=True表示删除第一列,编码后有A,B,C三列,删除第一列后只有B,C两列,减少冗余
data = pd.get_dummies(data, columns=discrete_lists, drop_first=True)
data.columns输出:
Index(['Id', 'Annual Income', 'Tax Liens', 'Number of Open Accounts',
'Years of Credit History', 'Maximum Open Credit',
'Number of Credit Problems', 'Months since last delinquent',
'Bankruptcies', 'Current Loan Amount', 'Current Credit Balance',
'Monthly Debt', 'Credit Score', 'Credit Default',
'Home Ownership_Home Mortgage', 'Home Ownership_Own Home',
'Home Ownership_Rent', 'Years in current job_10+ years',
'Years in current job_2 years', 'Years in current job_3 years',
'Years in current job_4 years', 'Years in current job_5 years',
'Years in current job_6 years', 'Years in current job_7 years',
'Years in current job_8 years', 'Years in current job_9 years',
'Years in current job_< 1 year', 'Purpose_buy a car',
'Purpose_buy house', 'Purpose_debt consolidation',
'Purpose_educational expenses', 'Purpose_home improvements',
'Purpose_major purchase', 'Purpose_medical bills', 'Purpose_moving',
'Purpose_other', 'Purpose_renewable energy', 'Purpose_small business',
'Purpose_take a trip', 'Purpose_vacation', 'Purpose_wedding',
'Term_Short Term'],
dtype='object')如何找到所有编码后的新特征名来将bool型转化为int型
# 将编码前后的特征名进行对比即可
new_feature_list = [] # 存储新特征名
# 重新读取获得旧特征名
data2 = pd.read_csv('data.csv')
for i in data.columns:
if i not in data2.columns:
new_feature_list.append(i)
new_feature_list 输出:
['Home Ownership_Home Mortgage',
'Home Ownership_Own Home',
'Home Ownership_Rent',
'Years in current job_10+ years',
'Years in current job_2 years',
'Years in current job_3 years',
'Years in current job_4 years',
'Years in current job_5 years',
'Years in current job_6 years',
'Years in current job_7 years',
'Years in current job_8 years',
'Years in current job_9 years',
'Years in current job_< 1 year',
'Purpose_buy a car',
'Purpose_buy house',
'Purpose_debt consolidation',
'Purpose_educational expenses',
'Purpose_home improvements',
'Purpose_major purchase',
'Purpose_medical bills',
'Purpose_moving',
'Purpose_other',
'Purpose_renewable energy',
'Purpose_small business',
'Purpose_take a trip',
'Purpose_vacation',
'Purpose_wedding',
'Term_Short Term']# 新特征类型转换为int型
for i in new_feature_list:
data[i] = data[i].astype(int)输出:(部分)
三、完整版(.py文件):
import pandas as pd
# 1.读取数据
data = pd.read_csv(r'py60-stud\data.csv')
# 2.补全缺失值
for i in data.columns:
if data[i].isnull().sum() > 0:
# 众数补全
mode = data[i].mode()[0]
data[i].fillna(mode, inplace=True)
# 3.找出离散特征进行独热编码
discrete_features_list =[]
for i in data.columns:
if data[i].dtype == 'object':
discrete_features_list.append(i)
# 每个离散特征下的类别无顺序关系
data = pd.get_dummies(data, columns=discrete_features_list)
# 4.新特征bool型转化为int型
# 重新读取旧特征
data2 = pd.read_csv(r'py60-stud\data.csv')
new_feature_list = []
# 获取新特征名
for i in data.columns:
if i not in data2.columns:
new_feature_list.append(i)
# bool型转化为int型,False->0,True->1
for i in new_feature_list:
data[i] = data[i].astype(int)
print(data.head(5))
pip install pywinpty --only-binary=:all:
pip install jupyter -i https://mirrors.aliyun.com/pypi/simple


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









