







- 单特征可视化:连续变量箱线图(核密度直方图)、离散特征直方图
- 特征和标签关系可视化
- 特征与特征关系可视化
一、单特征分布可视化
1、找到连续特征
# 读取数据
import pandas as pd
data = pd.read_csv('data.csv')
# for循环遍历列名,查找连续特征
continuous_features = []
for i in data.columns:
if data[i].dtype != 'object':
continuous_features.append(i)
continuous_features 输出:
['Id',
'Annual Income',
'Tax Liens',
'Number of Open Accounts',
'Years of Credit History',
'Maximum Open Credit',
'Number of Credit Problems',
'Months since last delinquent',
'Bankruptcies',
'Current Loan Amount',
'Current Credit Balance',
'Monthly Debt',
'Credit Score',
'Credit Default']2、另一种方法查找连续特征
# 另一种方法查找连续特征
# select_dtypes(),返回的是DataFrame类型,即符合函数参数要求的表格
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist()
continuous_features输出:同上
注:以上方法筛选的类型是int64和float64的,但未必全是连续特征
连续特征的本质 :理论上可以取区间内任意实数值(无限多个可能值),例如温度(25.3℃、
25.31℃等)、收入(5000.5元、5000.51元等)。
离散特征的本质 :只能取有限个或可数无限个值(如整数、分类标签),例如“家庭人数”(只能是
1、2、3…)、“学历”(小学/初中/高中等)、“年龄”(20岁、23岁)。
3、初识matplotlib库
画一个图需要哪些要素?
1. 指定图的类型,比如折线图、柱状图、散点图
2. 指定图的坐标轴,x轴有轴,传入数据
3. 指定图的标题,x轴和y轴的标签
绘制连续特征“年收入”分布图(箱线图)
# 数据可视化库,基于matplotlib封装
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# 使用seborn绘制箱线图boxplot
sns.boxplot(x=data['Annual Income'])
# 设置标题
plt.title('Annual Income 的箱线图')
# 设置x轴标签
plt.xlabel('Annual Income')
# 显示图表
plt.show()输出:
e:\CondaEnvs\envs\py60\lib\site-packages\IPython\core\pylabtools.py:152: UserWarning: Glyph 30340 (\N{CJK UNIFIED IDEOGRAPH-7684}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
e:\CondaEnvs\envs\py60\lib\site-packages\IPython\core\pylabtools.py:152: UserWarning: Glyph 31665 (\N{CJK UNIFIED IDEOGRAPH-7BB1}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
e:\CondaEnvs\envs\py60\lib\site-packages\IPython\core\pylabtools.py:152: UserWarning: Glyph 32447 (\N{CJK UNIFIED IDEOGRAPH-7EBF}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
e:\CondaEnvs\envs\py60\lib\site-packages\IPython\core\pylabtools.py:152: UserWarning: Glyph 22270 (\N{CJK UNIFIED IDEOGRAPH-56FE}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)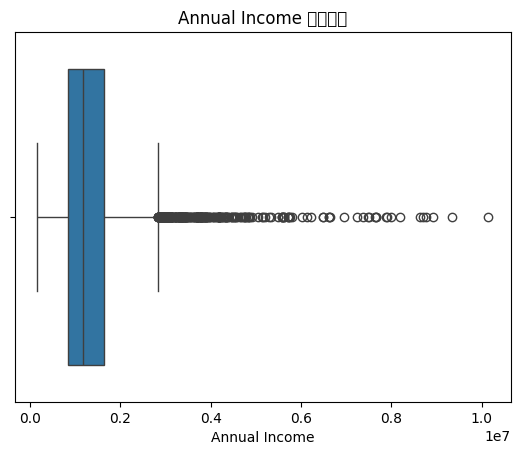
发现问题:
1. 会有警告
2. 中文显示为方块
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
data = pd.read_csv('data.csv')
# 设置 全局字体 为支持中文的字体(例如黑体SimHei)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号‘-’显示为方块的异常
plt.rcParams['axes.unicode_minus'] = False
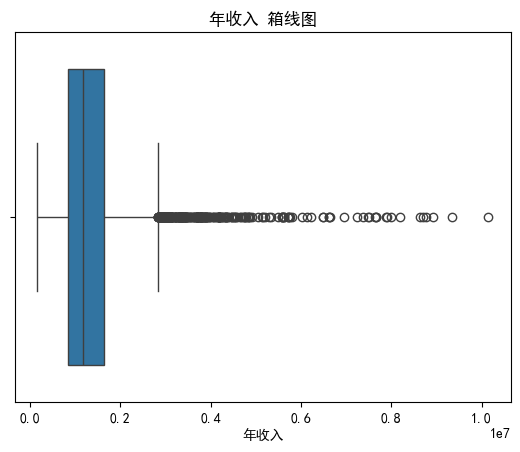
# 绘制箱线图 boxplot
sns.boxplot(x=data['Annual Income'])
plt.title('年收入 箱线图')
plt.xlabel('年收入')
plt.show()输出:
注:
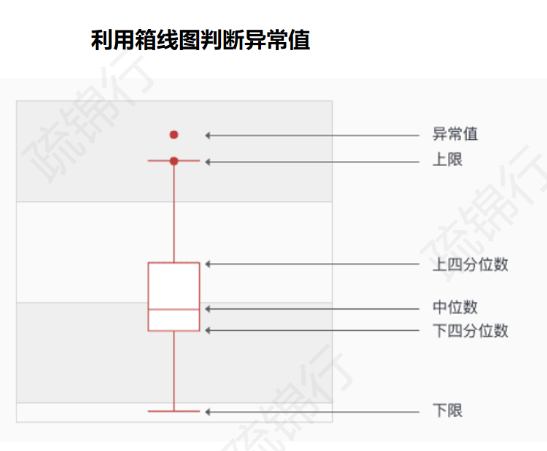
plt.rcParams 是Matplotlib的全局配置参数,用于设置图表的各种样式(如字体、颜色等)。
font.sans-serif 表示无衬线字体的配置项(无衬线字体通常更适合屏幕显示)。
SimHei 是具体的字体名称(黑体),通过这行代码将全局无衬线字体设置为SimHei,解决中文乱码问题(默认字体可能不支持中文)。
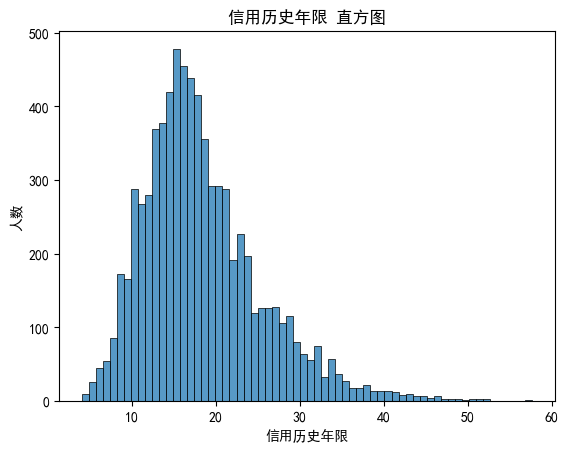
绘制离散特征“信用历史年限”分布图(直方图)
# 绘制直方图 histplot
sns.histplot(x=data['Years of Credit History'])
plt.title('信用历史年限 直方图')
plt.xlabel('信用历史年限')
plt.ylabel('人数')
plt.show()输出;
绘制离散特征“当前工作年限”单特征分布图(直方图):
# 当前工作年限 直方图
sns.histplot(x=data['Years in current job'])
plt.title('当前工作年限 直方图')
plt.xlabel('年')
plt.ylabel('员工数量')
plt.show()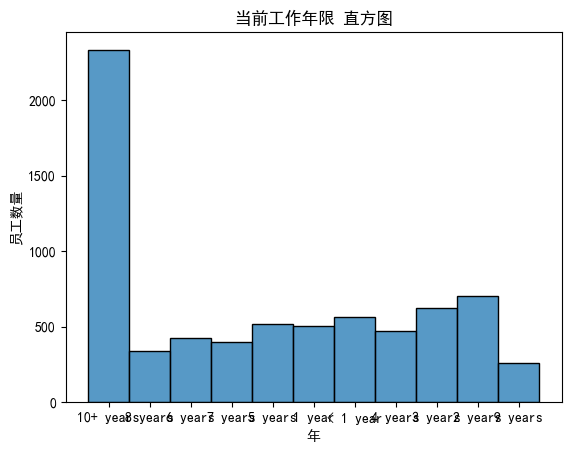
发现问题:横坐标太窄,标签显示重叠
# 使用plt的一些新参数调整图像
sns.histplot(x=data['Years in current job'])
plt.title('在当前工作年限 直方图')
plt.xlabel('在当前工作年限')
plt.ylabel('员工数量')
plt.xticks(rotation=45, ha='right') # 旋转(rotation)45度,并右对齐
plt.tight_layout() # 自动调整布局(layout),防止标签重叠
plt.show()输出:
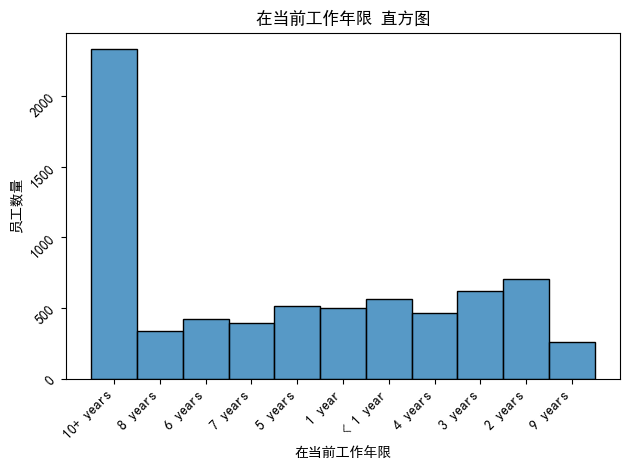
二、绘制特征和标签的关系
1、连续特征与标签的关系
本数据集标签是离散的(违约、不违约),特征是连续的,如何绘图
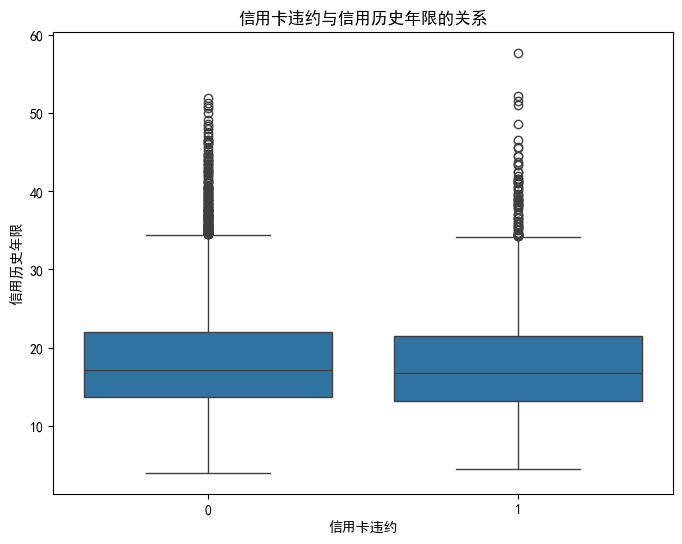
1. 绘制箱线图
2. 横坐标为标签,纵坐标为连续特征
plt.figure(figsize=(8, 6))
sns.boxplot(x='Credit Default', y='Years of Credit History', data=data)
plt.title('信用卡违约与信用历史年限的关系')
plt.xlabel('信用卡违约')
plt.ylabel('信用历史年限')
plt.show()输出:
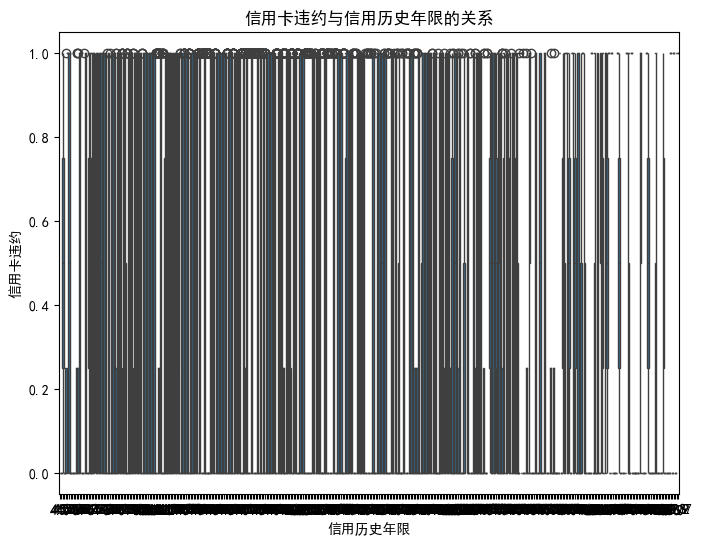
若横坐标为连续特征,纵坐标为标签
输出:横坐标“信用历史年限”(小数)是连续值,可能取值太多了,结果跟条形码似的。
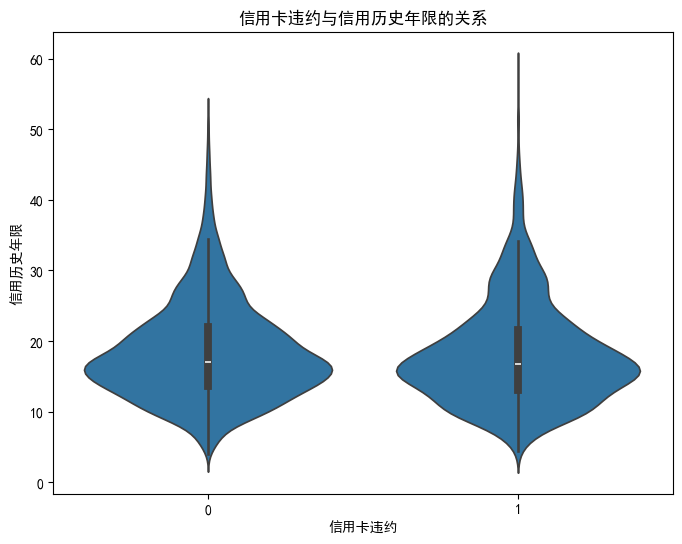
另一种方式:小提琴图 violinplot
# 另一种方式:小提琴图
plt.figure(figsize=(8,6))
sns.violinplot(x='Credit Default', y='Years of Credit History', data=data)
plt.title('信用卡违约与信用历史年限的关系')
plt.xlabel('信用卡违约')
plt.ylabel('信用历史年限')
plt.show()输出:
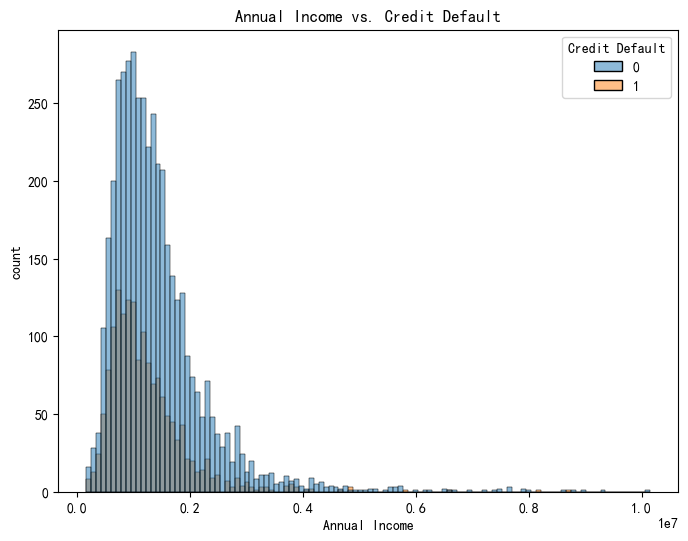
实际上连续特征也可以画直方图,并用核密度估计来完成边缘密度的柔和化
plt.figure(figsize=(8,6))
# hue='Credit Default' 根据Credit Default的值进行颜色区分
# kde=True 显示核密度估计曲线
# element='step' 绘制阶梯状的直方图
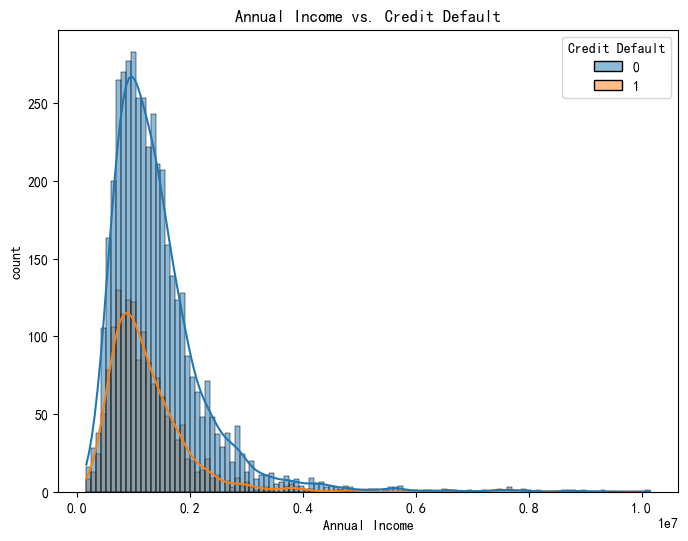
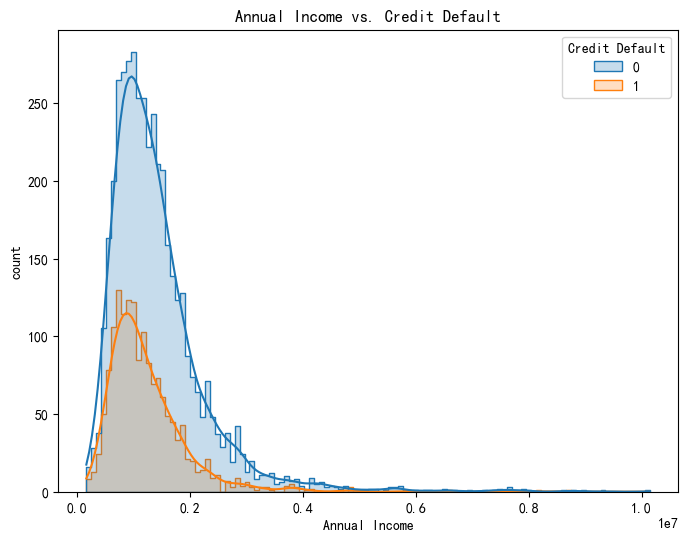
sns.histplot(x='Annual Income', hue='Credit Default', data=data,kde=True, element='step' )
plt.title('Annual Income vs. Credit Default')
plt.xlabel('Annual Income')
plt.ylabel('count')
plt.show()- hue='Credit Default' 根据标签 Credit Default 的值进行颜色区分
- kde=True 显示核密度估计曲线,更柔和地反映年收入的概率密度分布
- element='step' 绘制阶梯状的直方图,默认情况下,直方图可能显示为填充的矩形块,等同( element="bars" ),而 step 会仅绘制矩形的边框,形成阶梯线条,适合多类别叠加时避免颜色覆盖过深,提高可读性。
2、离散特征与标签的关系
plt.figure(figsize=(8,6))
sns.countplot(x='Number of Open Accounts', hue='Credit Default', data = data, )
plt.title('Number of Open Accounts vs. Credit Default')
plt.xlabel('Number of Open Accounts')
plt.ylabel('Count')
plt.show()输出:hue='Credit Default' 根据标签 Credit Default 的值进行颜色区分
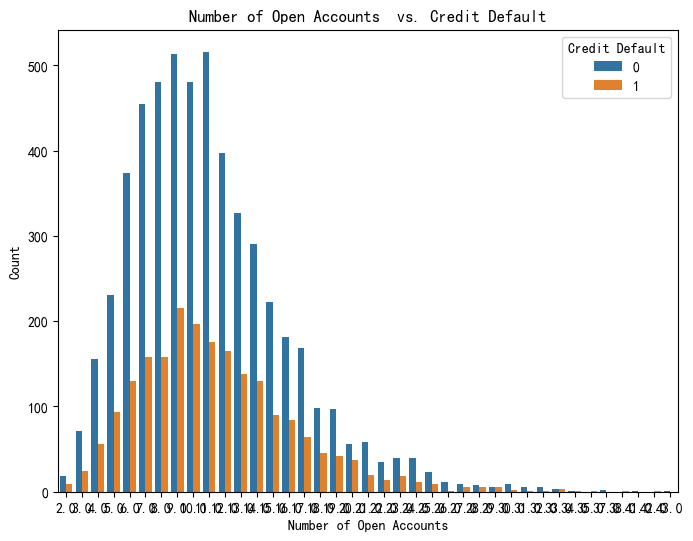
离散特征的取值可能也很多,此时横坐标可能会很散,不美观,还可以先将特征进行分组,再画图pd.cut()
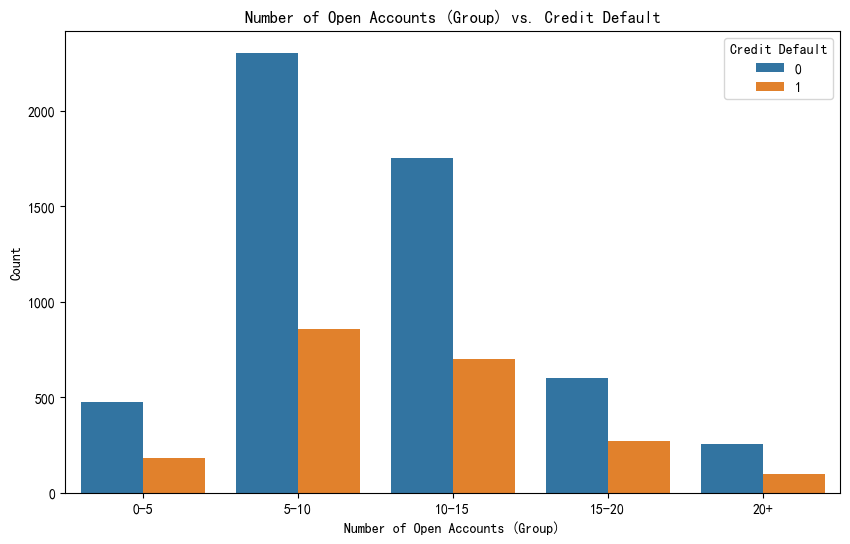
# 将Number of Open Accounts 分组, 并将其转换为字符串类型
data['Open Accounts Group'] = pd.cut(data['Number of Open Accounts'], bins=[0, 5, 10, 15, 20, float('inf')], labels=['0-5', '6-10', '11-15', '16-20', '20+']) # 根据你的数据调整分组
plt.figure(figsize=(10,6))
sns.countplot(x='Open Accounts Group', hue='Credit Default', data = data, )
plt.title('Number of Open Accounts (Group) vs. Credit Default')
plt.xlabel('Number of Open Accounts (Group)')
plt.ylabel('Count')
plt.show()注:
- data['Number of Open Accounts']:(必填)需要被分箱的原始数据列,必须是数值型
- bins=[0, 5, 10, 15, 20, float('inf')]:(必填)指定分箱的区间边界,定义了取值范围,分箱规则为左开右闭,即(0,5]、(5,10]...(15,20]、(20,正无穷]
- labels=['0-5', '6-10', '11-15', '16-20', '20+']:自定义标签,标签数量必须与bins定义的区间数量一致


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









