






神经网络的偏差与方差处理
模型偏差与方差实例
| 测试集 | 验证集 | 模型问题 |
|---|---|---|
| 高误差 | 高误差 | 模型或数据处理错误 |
| 底误差 | 高误差 | 方差过大,过拟合 |
| 高误差 | 底误差 | 偏差过大,欠拟合 |
偏差与方差处理
正则化 regularization
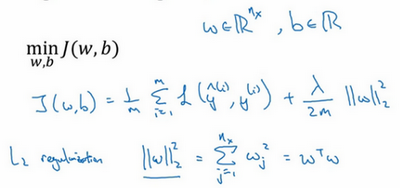
在成本函数中添加参数
λ
/
2
m
∗
∥
w
∥
2
2
\lambda/2m*\begin{Vmatrix}w \end{Vmatrix}_2^2
λ/2m∗∥∥w∥∥22
以上是常用的L2正则化,除此外,还有L1正则化或者对b参数正则化等。
特别的,L1正则经常会得到稀疏矩阵,但并未因稀疏而降低内存使用。
λ
=
r
e
g
u
l
a
r
i
z
a
t
i
o
n
_
p
a
r
a
m
e
t
e
r
\lambda = regularization\_parameter
λ=regularization_parameter
对于神经网络中的二维 W 矩阵,我们用弗罗贝尼乌斯范数代替L2范数即正则参数表达为:
λ
/
2
m
∗
∥
w
∥
F
2
\lambda/2m*\begin{Vmatrix}w \end{Vmatrix}_F^2
λ/2m∗∥∥w∥∥F2
后令
d
w
[
L
]
=
δ
J
/
δ
w
+
λ
/
m
w
[
L
]
dw^{[L]}=\delta J/\delta w +\lambda/m w^{[L]}
dw[L]=δJ/δw+λ/mw[L]
得到新的梯度下降公式:
w
[
L
]
:
=
w
[
L
]
−
α
d
w
[
L
]
w^{[L]}:=w^{[L]}-\alpha dw^{[L]}
w[L]:=w[L]−αdw[L]
:
=
(
1
−
α
λ
/
m
)
w
[
L
]
−
α
δ
J
/
δ
w
:=(1-\alpha \lambda/m)w^{[L]} -\alpha \delta J/\delta w
:=(1−αλ/m)w[L]−αδJ/δw
















 1149
1149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









