






在前面的内容中我们介绍了集合框架中的List集合、Set集合以及JDK1.5版本新特性——泛型的内容,在这篇博客中我们来继续介绍集合框架中的另一个重要部分——Map集合。
1. Map集合的特点
我们去查阅Map集合的API文档可以发现,Map接口的泛型类型有两个,分别是K和V,这与我们之前看到的其他只应用一个泛型类型的接口和类是不同的。其中,K代表Key,意思是键;V代表Value,意思是值。另外,Map的英文本意就有映射的意思,这其实也就体现了Map集合存储元素的特点。看到这我们就可以很自然的联想到,我们在使用Map集合的时候需要同时存储两个元素——键和与其对应的值,而键与值之间存在着映射关系,或者说是一一对应的关系。这里我们引用一下Map接口API文档对它的描述:将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。可以将Map集合和List集合进行比较:List集合其实也有映射关系,只不过它的键是基本数据类型——int,与其对应的值是对象;Map集合的的映射关系是,对象与对象之间的映射。
小知识点1:
我们阅读Map接口的API文档知可知,Map并不是Collection接口的子接口,可以说Map是单独成一派的,但两个接口之间还是由其内在联系。
我们用一句话来总结Map集合的特点:该集合存储一对一对的键值对,可以保证键值对映射关系的唯一性。
2. Map接口常见实现类
Map接口有三个较为常见的实现类,分别为:Hashtable、HashMap、TreeMap,我们就按照这个顺序对其逐一进行介绍。
2.1 Hashtable
Hashtable类的API文档描述为:此类实现一个哈希表,该哈希表将键映射到相应的值。任何非null对象都可以用作键或值。为了成功地在哈希表中存储和获取对象,用作键的对象必须实现hashCode方法和equals方法。这与我们之前介绍的HashSet集合是类似的,若需要把对象存储到HashSet集合中,那么被存储对象所属的类必须复写hashCode和equals方法。
此外,Hashtable出现于JDK1.0版本中,那么通常该类的方法都是实现了同步机制的,这也可以从API文档描述得到证实。
2.2 HashMap
同样,我们首先来阅读该类的API文档:基于哈希表的Map接口的实现。此实现提供所有可选的映射操作,并允许使用null值和null键。(除了非同步和允许使用null 之外,HashMap类与Hashtable大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。简单来说,HashMap就是Hashtable的升级版本,而升级版本通常都不会默认具备同步功能,因此HashMap是不同步的。
小知识点1:
区分HashMap和Hashtable之间的不同是面试中经常被问到的题目,那么除了回答前者不同步,后者同步以外,一定要答出,前者允许null值和null键;而后者不允许null值和键。如果想要表达得更为全面,那么两者的出现版本也不同,而且前者因未使用同步机制而效率较高,后者效率较低。另外,如果问两者的相同点,那就是两个底层都是用了哈希表数据结构。
2.3 TreeMap
基于二叉树的数据结构的Map集合。它可以根据键的自然顺序进行排序,或者根据创建集合时提供的Comparator比较器进行排序。同样,线程不同步。
了解了上述三个Map实现类的特点,细心的朋友可能会发现,Map集合的特点与Set集合非常类似,而实际上Set底层的实现原理就是应用的Map集合,有兴趣的朋友可以去查阅Map集合的源代码。
3 Map集合共性方法
3.1 Map集合共性方法介绍
与学习Set和List集合一样,我们还是通过顶层接口Map,来了解Map集合系列的共性方法。详细的方法信息,请参考Map集合的API文档。
(a) 添加
V put(K key, Vvalue):向集合中存储一个指定键值对。返回值为该映射关系中的值。
voidputAll(Map<?extends K, ? extends V> m):向集合中存储参数集合中的所有映射关系。
(b) 删除
void clear():从此映射中移除所有映射关系。可以理解为删除全部元素。
V remove(Object key):从集合中删除指定键对应的值,换句话说,删除指定键值对。返回值为被删除的值。
(c) 判断
booleancontainsKey(Objectkey):判断集合中是否存在指定的键。若存在,则返回true;否则返回false。
booleancontainsValue(Objectvalue):判断集合中是否存在指定的值。若存在,则返回true;
否则返回false。
booleanisEmpty():判断集合是否为空。如果该集合中没有任何元素,则返回true。
(d) 获取
V get(Object key):返回指定键对应的值。如果集合中不存在指定键,那么返回null。
int size():获取集合的长度。
Collection<V>values():将该集合中所有值存储到一个新集合中,并返回该新集合。
以上这些方法相对比较易于掌握,而我们需要重点介绍的是entrySet和keySet两个方法。 按照以往的惯例,我们通过顶层接口来了解该集合系列的共性方法,并通过该接口的实现类来掌握这些方法的具体调用方式及效果,因此在应用这些方法以前首先简单介绍Map接口常见实现类及其特点。
3.2Map集合共性方法应用
这里我们以HashMap为例介绍Map集合的具体调用方式及效果。
3.2.1基本方法应用
首先介绍Map集合较为常见而易于掌握的一些方法,阅读下面代码,
代码1:
import java.util.*;
class MapDemo
{
public static void main(String[] args)
{
//多态地创建一个HashMap集合对象
Map<String,String> map = new HashMap<String,String>();
//添加非空键值对
map.put("201501","Zoey");
map.put("201502","Peter");
map.put("201503","Charlie");
map.put("201504","Jack");
//判断集合中是否存在指定的键
System.out.println("containsKey:"+map.containsKey("201502"));
//判断集合是否存在指定的值
System.out.println("containsValue:"+map.containsValue("Charlie"));
System.out.println("=======================================");
//删除集合中指定键对应的键值对
System.out.println(map);//删除元素前打印集合内容
System.out.println("remove:"+map.remove("201502"));//删除集合中存在的键值对
System.out.println("remove:"+map.remove("201505"));//删除集合中不存在键值对
System.out.println(map);//删除元素后打印集合内容
System.out.println("=======================================");
//获取集合中指定键对应的值
System.out.println("201503="+map.get("201503"));//获取集合中存在的键值对
System.out.println("201523="+map.get("201523"));//获取集合中不存在的键值对
System.out.println("=======================================");
//获取集合中所有的值
Collection<String> coll= map.values();
System.out.println(coll);
}
}containsKey:true
containsValue:true
=======================================
{201503=Charlie, 201502=Peter,201504=Jack, 201501=Zoey}
remove:Peter
remove:null
{201503=Charlie, 201504=Jack,201501=Zoey}
=======================================
201503=Charlie
201523=null
=======================================
[Charlie, Jack, Zoey]
运行结果表明,元素的打印顺序与存储顺序是无关,这也就体现了哈希表数据结构元素顺序的无序性。
作两点补充说明:
(1) 除了通过containsKey和containsValue方法以外,我们还可以通过remove或get方法的返回值来判断集合中是否存在指定键对应的值,也就是说当这两个方法的返回值为null时,表明集合中不存在指定键对应的键值对。
(2) API文档中显示的put方法返回值类型为V,而实际的返回值为指定键对应的前一个值,观察下面的代码,
代码2:
import java.util.*;
class MapDemo2
{
public static void main(String[] args)
{
Map<String,String> map = new HashMap<String,String>();
System.out.println("key1="+map.put("key1","value1"));
//将key1键对应的值更新为value2
System.out.println("key1="+map.put("key1","value2"));
}
}key1=null
key1=value1
第一行结果表明,键key1对应的前一个值为null,换句话说在存储key1和value1键值对以前,集合中不存在key1的值,而存储了这一键值对后key1真正对应的值为value1;此后,将key1对应的值设置为value2时,打印的值为前一个对应的值value1。那么其实,这一过程也就体现了,哈希表数据结构保证元素(这里指的是值)唯一性的特点,或者说映射关系的唯一性——一个键只能对应一个值,当存储相同键时,新值将覆盖旧值,以保证值的唯一性。
我们再举一个特殊情况,由前述HashMap的API文档可知,HashMap是允许存存储空键和空值的,阅读下面代码
代码3:
import java.util.*;
class MapDemo3
{
public static void main(String[] args)
{
Map<String,String> map = new HashMap<String,String>();
//添加元素
map.put(null,"value1");//空键,非空值
map.put("key2",null);//非空键,空值
//获取元素
System.out.println("null="+map.get(null));
System.out.println("key2="+map.get("key2"));
}
}null=value1
key2=null
上述结果表明,HashMap集合是允许存储空键或空值的,并且可以通过null来获取对应的值,或者通过非空键来获取null值。当然这种情况在实际开发中是很少见的。此外,键与值均为空也是允许的,有兴趣的朋友可以自行尝试。
3.2.2 高级方法应用
在上面的内容中我们介绍了Map集合的一些基本方法,包括了增删改查,而其中通过get方法获取元素的方式是比较低效的,因为一次只能取一个元素,而Map作为集合框架的一员,我们自然就想到通过迭代器的方式获取到全部元素,keySet和entrySet两个方法便间接地实现了这一功能。
(1) keySet
Set<K>Keyset():将集合中所有元素均存储到一个Set集合中,并返回该Set集合。
通过keySet方法获取元素的思想就是首先获取到集合中的所有键,而这些键都存储在一个Set集合中,通过Set集合的迭代器取出其中所有的键,再通过Map集合get方法,获取到键所对应的值,阅读下面的代码,
代码4:
import java.util.*;
class MapDemo4
{
public static void main(String[] args)
{
Map<String,String> map = new HashMap<String,String>();
map.put("201501","Sara");
map.put("201502","Bob");
map.put("201503","Anna");
map.put("201504","Charlie");
map.put("201505","Douglas");
map.put("201506","Emma");
//获取到键的Set集合
Set<String> numbers = map.keySet();//Set集合的泛型是Map中键的类型
String number = null, name = null;
//通过迭代的方式获取到所有键的Set集合,再通过get方法获取到键对应的值
for(Iterator<String> it = numbers.iterator(); it.hasNext(); )
{
number= it.next();//获取到Set集合中的键
name= map.get(number);//通过get获取到Map中的值
System.out.println(number+"= "+name);
}
}
}201506 = Emma
201503 = Anna
201502 = Bob
201505 = Douglas
201504 = Charlie
201501 = Sara
通过上述方法就先后获取到了Map集合中的所有键与值。这里我们强调了“先后”,因为上述获取过程的确是先获取键,再获取到值,而下面我们要介绍的entrySet方法可以实现同时获取键值对。
(2) entrySet
Set<Map.Entry<K,V>>entrySet():将Map集合中的键值对(或称为映射关系)存储到一个Set集合中,并返回该Set集合。
我们看到entrySet方法的返回值Set的泛型类型为Map.Entry<K,V>,而由Map.Entry<K,V>后面的泛型类型可知其用于存储键值对,或者称为键与值的映射关系,就是说将键与值作为一个整体存储到Map.Entry后,再将Map.Entry作为元素存储到Set集合中。那么最终,我们再从Map.Entry中取出键与值。我们去查阅Map.Entry的API文档可知,它是一个接口,并定义了若干方法,其中getKey和getValue方法分别用于获取键和获取值。另外,需要提醒大家的,Map.Entry接口的实现类都是每个Map集合类的内部类,这与Iterator是相类似的。观察下面的代码,
代码5:
import java.util.*;
class MapDemo5
{
public static void main(String[] args)
{
Map<String,String> map = new HashMap<String,String>();
map.put("201501","Sara");
map.put("201502","Bob");
map.put("201503","Anna");
map.put("201504","Charlie");
map.put("201505","Douglas");
map.put("201506","Emma");
//将Map集合中的映射关系取出,存入到Set集合中
Set<Map.Entry<String,String>> entrySet= map.entrySet();
for(Iterator<Map.Entry<String,String>>it = entrySet.iterator(); it.hasNext(); )
{
Map.Entry<String,String> me = it.next();//依次取出entrySet集合中的Map.Entry
//再通过Map.Entry的getKey和getValue分别获取到键和值
String key = me.getKey();
String value = me.getValue();
System.out.println(key+"= "+value);
}
}
}201506 = Emma
201503 = Anna
201502 = Bob
201505 = Douglas
201504 = Charlie
201501 = Sara
结果表明,通过entrySet方法同样可以获取到Map集合中的所有键和值。我们通过下图来更为形象的介绍,通过entrySet方法获取键值对的过程。
首先,Map集合中存储了一对一对的键值对,如下左图所示,entrySet方法返回的就是存储着键与值映射关系的Set集合,下右图所示,Set集合中存储的是将键与值作为一个整体的Map.Entry对象。
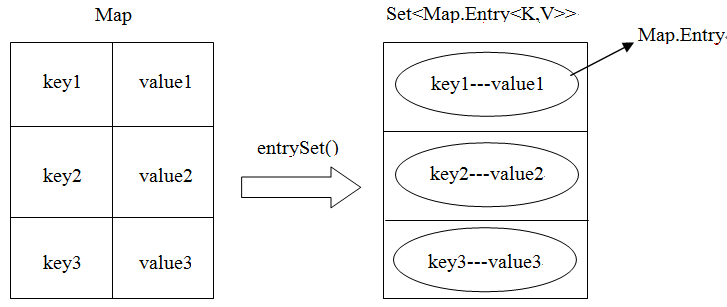
因此我们可以将Map.Entry对象理解为,键与值的关系对象,它既不能是键类型,也不能是值类型,因此单独定义了一个类型——Map.Entry——用于描述键与值的映射关系。实际上,Entry也是一个接口,而从Map.Entry这样的语法格式我们也可以推测出,Entry是Map接口的内部接口,它的源代码(部分)为:
代码6:
interface Map<K,V>
{
//Map接口的公有静态内部接口,泛型类型同为K,V
public static interface Entry<K,V>
{
//只呈现了部分方法
public abstract K getKey();//获取键的抽象方法,需由实现类复写
public abstract V getValue();//获取值的抽象方法,需由实现类复写
}
}
//以HashMap为例来说明其实现方式
class HashMap implementsMap<K,V>//实现Map接口
{
//定义一个内部类,实现Map的内部接口Entry
class HashEntry implements Map.Entry<K,V>
{
//复写Map.Entry接口的抽象方法
public K getKey(){}
public V getValue(){}
}
}可以通过Map接口的API文档来验证上述说明。嵌套类摘要中的唯一一项就是Map.Entry接口,对它的说明为:映射项(键-值对)。再打开Map.Entry的API文档,其接口名修饰符为“publicstatic”,这就表明Entry处于Map接口的成员位置上。
4. Map集合练习
4.1 练习一
需求:模拟存储学生信息的过程。规定学生有两个属性——姓名和年龄,并以学生对象为键,以学生地址为值,姓名和年龄相同的学生视为同一个学生。要求是保证学生的唯一性。
分析:
(1) 定义学生类,定义两个成员变量(属性)——姓名和地址,并定义对应的获取姓名和地址的方法。
(2) 创建一个Map集合,将学生作为键,地址作为值,存入。
(3) 获取Map集合中的元素。
代码7:
import java.util.*;
class Student implementsComparable<Student>
{
private String name;
private intage;
Student(String name, int age)
{
this.name= name;
this.age= age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
public String toString()
{
return name+" = "+age;
}
/*
为了便于后期将Student对象存储到哈希表数据结构的集合
(无论HashSet还是HashMap)中
所以需要复写hashCode和equals方法
*/
public int hashCode()
{
return name.hashCode()*37+age;
}
public booleanequals(Object obj)
{
if(!(objinstanceofStudent))
/*
当传入的参数类型不是Student时,抛出异常(运行时异常子类)
停止程序的继续运行
*/
throw new IllegalArgumentException("参数类型不符!");
Student stu = (Student)obj;
return name.equals(stu.getName())&& age == stu.getAge();
}
/*
为了便于将Student对象存储到二叉树数据结构的集合中
需要实现Comparable接口,并复写compareTo方法
*/
public int compareTo(Studentstu)
{
int value = new String(name).compareTo(stu.getName());
if(value== 0)
return new Integer(age).compareTo(new Integer(stu.getName()));
return value;
}
}
class MapTest
{
public static void main(String[] args)
{
HashMap<Student,String> hm= new HashMap<Student,String>();
hm.put(newStudent("Peter",23),"USA");
hm.put(newStudent("Robert",31),"Canada");
hm.put(newStudent("Susan",19),"France");
hm.put(newStudent("Robert",31),"Italy");//存储同名同年龄,但不同地址的键值对
//用于接收Student对象和地址字符串对象的变量
Student stu = null;
String address = null;
//通过keySet方法获取元素
Set<Student> students = hm.keySet();
for(Iterator<Student>it = students.iterator(); it.hasNext(); )
{
stu= it.next();
address= hm.get(stu);
System.out.println(stu+": "+address);
}
System.out.println("==============================================");
//通过entrySet方法获取元素
Set<Map.Entry<Student,String>> entryset= hm.entrySet();
Map.Entry<Student,String> me = null;
for(Iterator<Map.Entry<Student,String>>it = entryset.iterator(); it.hasNext(); )
{
me= it.next();
stu= me.getKey();
address= me.getValue();
System.out.println(stu+": "+address);
}
}
}Peter = 23 : USA
Robert = 31 : Italy
Susan = 19 : France
================================================
Peter = 23 : USA
Robert = 31 : Italy
Susan = 19 : France
在上述代码中我们分别使用keySet和entrySet两种方式获取了HashMap集合中的所有元素。
由于在实际操作的过程中,可能会产生大量的学生对象,通常需要一些容器对其进行存储。因此,我们为Student类复写了hashCode方法和equals方法,方便后期存储到哈希表数据结构的集合中;实现了Comparable接口,并复写了compareTo方法,便于后期存储到二叉树数据结构的集合中。这也是今后在实际开发过程中需要注意的——如果需要大量创建自定义类对象,那么尽量复写hashCode和equals方法,并实现Comparable接口,复写compreTo方法。
我们注意到,由于复写了hashCode和equals方法,HashMap集合就展现了其保证元素唯一性的特征——当存储的键相同(同名同年龄),而值(地址)不相同时,新值会覆盖旧值,因此Robert的地址被更新为了Italy。
4.2 练习二
需求:同上述练习一,但需要对学生对象按照年龄进行升序排序。
分析:主要步骤与练习一相同,因需要对元素进行排序,因此存储容器需要更改为TreeMap集合。
代码8:
import java.util.*;
public class Student implements Comparable<Student>
{
private String name;
private int age;
public Student(String name, int age)
{
this.name= name;
this.age= age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
public String toString()
{
return name+" = "+age;
}
public int hashCode()
{
return name.hashCode()*37+age;
}
public boolean equals(Object obj)
{
if(!(objinstanceofStudent))
throw new IllegalArgumentException("参数类型不符!");
Student stu = (Student)obj;
return name.equals(stu.getName())&& age == stu.getAge();
}
/*
由于需要按照年龄升序排序
因此,compareTo方法中的主要条件为年龄
次要条件为姓名
*/
public int compareTo(Studentstu)
{
intv alue = new Integer(age).compareTo(new Integer(stu.getAge()));
if(value== 0)
return name.compareTo(stu.getName());
return value;
}
}
public class MapTest2
{
public static void main(String[] args)
{
TreeMap<Student,String> tm = new TreeMap<Student,String>();
tm.put(newStudent("Peter",23),"USA");
tm.put(newStudent("Robert",31),"Canada");
tm.put(newStudent("Susan",19),"France");
tm.put(newStudent("Robert",31),"Italy");//存储同名同年龄,但不同地址的键值对
Student stu = null;
String address = null;
//通过keySet方法获取元素
Set<Student> students = tm.keySet();
for(Iterator<Student>it = students.iterator(); it.hasNext(); )
{
stu= it.next();
address= tm.get(stu);
System.out.println(stu+": "+address);
}
System.out.println("=========================================");
//通过entrySet方法获取元素
Map.Entry<Student,String> me = null;
Set<Map.Entry<Student,String>> entryset= tm.entrySet();
for(Iterator<Map.Entry<Student,String>>it = entryset.iterator(); it.hasNext(); )
{
me= it.next();
stu= me.getKey();
address= me.getValue();
System.out.println(stu+": "+address);
}
}
}Susan = 19 : France
Peter = 23 : USA
Robert = 31 : Italy
=========================================
Susan = 19 : France
Peter = 23 : USA
Robert = 31 : Italy
结果显示,无论采用哪种获取元素方式,取出顺序均是按照Student对象的年龄升序排序的,并且存储同键元素的时候,新值覆盖了旧值。如果我们还想按照姓名的升序排序的话,在不修改原有代码的前提下,定义一个比较器类时最好的办法,如下代码所示,
代码9:只呈现定义比较器类的代码
//定义按照学生姓名升序排序的比较器类
class StudentNameComparator implements Comparator<Student>
{
//姓名为主要条件,年龄为次要条件
public int compare(Student stu1,Student stu2)
{
int value = stu1.getName().compareTo(stu2.getName());
if(value== 0)
return new Integer(stu1.getAge()).compareTo(new Integer(stu2.getAge()));
return value;
}
}Peter = 23 : USA
Robert = 31 : Italy
Susan = 19 : France
=========================================
Peter = 23 : USA
Robert = 31 : Italy
Susan = 19 : France
Map集合中的元素是按照Student对象的姓名升序排序的。
4.3 练习三
需求:获取字符串“soihgrhrhfvdhguhfi”中每个字母出现的次数。要求打印结果的格式为:a(2)b(2)…。
思路:字符与个数之间存在着一一对应的关系,那么就可以使用Map集合将字符和与其对应的个数成对地存储起来。存储时,若该字符不存在于集合中,则存储字符和数字1;若已存在,就将字符个数自增再存储。
实现方式:
我们使用两种方法实现目标需求,这两种方法首先都要将字符串转换为字符数组,这样做的好处是避免了反复调用charAt方法来获取每个字符,以此提高代码执行效率。
方法一:
遍历字符数组。获取字符数组中的第一个字符,将其作为键,判断该键是否存在于集合中。此时集合为空,显然不存在任何元素,就将该字符作为键,1作为值(个数),存储到Map集合中。同理,此后遍历到的字符只要不存在于集合中,就将该字符和1成对地存储到集合中。相反,若遍历到的字符已存在于集合中,就将其对应的值(个数)取出,自增后再重新存储。我们知道,当向Map集合中存储同值不同键的元素时,新值将覆盖旧值,这样就可以起到计数的效果。最后,将键值对(字符与对应的个数)按照给定格式,打印到控制台。
方法二:
根据方法一的执行流程可以观察到,无论字符对应的个数是否自增,最终都是要存储到集合中的。因此,只需要判断是否需要将值自增即可。由此,我们在对字符数组进行遍历以前需要定义一个计数器变量。执行流程同样要遍历字符数组。通过字符,从集合中获取到该字符对应的个数,判断该个数是否为空,若为空,则令计数器从初始化值(0)自增,最后存储字符和计数器记录的个数;若不为空,则将值赋给计数器,同样令计数器自增,成对存储字符和计数器数值。
代码10:
import java.util.*;
class MapTest4
{
public static void main(String[] args)
{
String source = "soihgrhrhfvdhguhfi";
char[] chs = source.toCharArray();//将字符串转成字符数组,以提高程序执行效率
TreeMap<Character,Integer> tm = new TreeMap<Character,Integer>();
//方法一:判断键(字符)是否存在于集合中
char ch = 0;//将临时变量定义在循环体外,以避免占用过多的栈内存空间
for(int x=0; x<chs.length; x++)
{
ch= chs[x];
if(ch<'a'&&ch>'z' || ch<'A' &&ch>'Z')//过滤非字母字符
continue;
if(!tm.containsKey(ch))
//如果集合中不存在指定字符,则存储该字符和1
tm.put(ch,new Integer(1));
else
//如果集合中已存在指定字符,则存储该字符,并将个数自增再存储
tm.put(ch,tm.get(ch)+1);
ch= 0;
}
//方法二:判断值(个数)是否存在于集合中
//将一下临时变量定义在循环体外,以避免占用过多的栈内存空间
Integer value = null;//记录字符对应个数
char ch = 0;//记录字符
int count = 0;//字符个数计数器
for(int x=0; x<chs.length; x++)
{
ch= chs[x];
if(ch<'a'&&ch>'z' || ch<'A' &&ch>'Z')//过滤非字母字符
continue;
value= tm.get(ch);//获取到指定字符对应的个数
if(value!= null)//若值(个数)为空,则将值赋给计数器
count= value;
count++;//计数器自增
tm.put(ch,count);//存储字符和自增后的计数器
count= 0;//将计数器清零
}
//打印结果
printMapElements(tm);
}
//按照指定格式打印集合中的元素。
public static void printMapElements(Map<Character,Integer> map)
{
Set<Map.Entry<Character,Integer>> entrySet= map.entrySet();
Map.Entry<Character,Integer> me = null;
for(Iterator<Map.Entry<Character,Integer>>it = entrySet.iterator(); it.hasNext(); )
{
me= it.next();
System.out.print(me.getKey()+"("+me.getValue()+")");
}
}
}d(1)f(2)g(2)h(5)i(2)o(1)r(2)s(1)u(1)v(1)
对于以上代码我们做出以下几点说明:
(1) 由于Map集合中只能存储引用数据类型,因此我们真正存储到集合中的是char和int类型的包装类Character和Integer对象,分别表示表示字符和其对应的个数。
(2) 由于Character类已经实现了Comparable接口,因此存储到TreeMap中时可以自动按照字母顺序排序。
(3) 用于存储字符和记录个数的变量,应定义在for循环体外,否则每执行一次循环体,就会在栈内存创建一个新的变量,导致短时间内占用过多的栈内存空间。
通过上述例程,我们可以做出如下总结:需要存储相互之间存在映射关系的数据时,就要优先使用Map集合。
4.4 练习四
需求:假设有一个学校,学校中有两个班级——普通班和实验班,每个班各有两名学生,普通班中的学生分别是:PT01,Jack;PT02,Kate(前学号,后姓名);实验班中的学生分别是:SY01,Tom;SY02,Susan。要求使用Map集合来表示学校与班级、班级与学生之间的关系。
思路:
存储过程:从下往上思考,首先创建上述四个学生对象,然后创建两个Map集合对象代表两个班级,将四个学生对象分别存储到两个班级中,存储时学号为键,姓名为值。最后再创建一个Map集合表示学校,将上述两个班级存储到学校Map中,班级名称为键,表示班级的Map对象为值。按照上述思路,实际编写代码时,应从上往下编写。
获取元素过程:这里以keySet方法为例。首先获取到存有所有班级名称的Set集合对象,利用迭代器开启一层for循环,每获取一个班级名称,通过get方法获取对应的班级Map对象。获取到班级Map对象以后,获取存储所有学生学号的Set集合,同样利用迭代器再开启一层for循环,每获取一个学生学号,就通过get方法获取对应的学生姓名,最后按照班级、学号、姓名的顺序将信息打印至控制台。有兴趣的朋友也可以尝试使用entrySet方法来实现相同的功能。
代码11:
import java.util.*;
//为演示方便不再单独定义Student类
class MapTest5
{
public static void main(String[] args)
{
//以下Map集合表示学校,用于存储班级
HashMap<String, HashMap<String,String>> school = new HashMap<String, HashMap<String,String>>();
//以下两个Map集合表示班级,用于存储学生
HashMap<String,String> ptclass = new HashMap<String,String>();
HashMap<String,String> syclass = new HashMap<String,String>();
//向学校中存储班级
school.put("普通班",ptclass);
school.put("实验班",syclass);
//向班级中存储学生
ptclass.put("PT01","Jack");
ptclass.put("PT02","Kate");
syclass.put("SY01","Tom");
syclass.put("SY02","Susan");
}
//打印所有班级所有学生的方法
public static void printStudentInfo(HashMap<String,HashMap> school)
{
String classname =null;
HashMap<String,String> classroom = null;
//外层for循环获取到所有的班级
for(Iterator<String>classit = school.keySet().iterator(); classit.hasNext(); )
{
//班级名称
classname= classit.next();
//通过班级名称获取代表班级的Map对象
classroom= school.get(classname);
printSingleClassStudentInfo(classname,classroom);//打印指定班级
}
}
public static void printSingleClassStudentInfo(String classname,HashMap<String,String> classroom)//打印一个班级所有学生的方法
{
String stunum = null;
String stuname = null;
//内层循环获取到班级中的所有学生
for(Iterator<String>stuit = classroom.keySet().iterator(); stuit.hasNext(); )
{
stunum= stuit.next();//获取学号
stuname= classroom.get(stunum);//获取姓名
//打印班级、学号、姓名
System.out.println(classname+":"+stunum+","+stuname);
}
}
}普通班:PT01,Jack
普通班:PT02,Kate
实验班:SY01,Tom
实验班:SY02,Susan
通过上述代码就将学校中的所有学生的信息都获取到,并打印在了控制台上。需要说明的是,为便于今后需要时,单独打印某一个班级所有学生的信息,将这部分代码封装为了一个单独的方法。
上述代码是为演示双重Map集合元素的存储与获取的方式,因而将学号与姓名作为键值对存储在了内层Map集合中,而在实际开发中通常会单独定义一个学生类,并通过创建Student对象来存储学号与姓名,因此内层集合应定义为单列集合,比如List集合,或者Set集合。相应的,获取元素的方法也应相应的做出修改,现将代码直接给出,
代码12:
import java.util.*;
class Student
{
privateString num,name;
Student(String num,String name)
{
this.num= num;
this.name= name;
}
public String getNum()
{
return num;
}
public String getName()
{
return name;
}
}
//为演示方便不再单独定义Student类
class MapTest6
{
public static void main(String[] args)
{
//以下Map集合表示学校,用于存储班级
HashMap<String,List<Student>> school = new HashMap<String,List<Student>>();
//以下两个List集合表示班级,用于存储学生
List<Student> ptclass = new ArrayList<Student>();
List<Student> syclass = new ArrayList<Student>();
//向学校中存储班级
school.put("普通班",ptclass);
school.put("实验班",syclass);
//向班级中存储学生
ptclass.add(newStudent("PT01","Jack"));
ptclass.add(newStudent("PT02","Kate"));
syclass.add(newStudent("SY01","Tom"));
syclass.add(newStudent("SY02","Susan"));
printStudentInfo(school);
}
//打印所有班级所有学生的方法,这里使用了entrySet方法
public static void printStudentInfo(HashMap<String,List<Student>> school)
{
Map.Entry<String,List<Student>> me = null;
String classname = null;
List<Student> classroom = null;
//外层for循环获取到所有的班级
for(Iterator<Map.Entry<String,List<Student>>> classit = school.entrySet().iterator(); classit.hasNext(); )
{
//键值对关系对象
me= classit.next();
//班级名称
classname= me.getKey();
//通过班级名称获取代表班级的Map对象
classroom= me.getValue();
printSingleClassStudentInfo(classname,classroom);//打印指定班级
}
}
public static void printSingleClassStudentInfo(String classname,List<Student> classroom)//打印一个班级所有学生的方法,第一个参数为班级名称
{
Student stu = null;
String stunum = null;
Stringstuname = null;
//内层循环获取到班级中的所有学生
for(Iterator<Student>stuit = classroom.iterator(); stuit.hasNext(); )
{
stu= stuit.next();//获取学生对象
stunum= stu.getNum();//获取学号
stuname= stu.getName();//获取姓名
//打印班级、学号、姓名
System.out.println(classname+":"+stunum+","+stuname);
}
}
}普通班:PT01,Jack
普通班:PT02,Kate
实验班:SY01,Tom
实验班:SY02,Susan
小知识点2:
实际上,无论是HashSet还是TreeSet,它们底层所使用的容器还是Map,只不过Set集合仅使用了Map的键,而没有使用值而已。我们可以看一看HashSet集合的源代码。以下是截取的一部分HashSet源代码。
代码13:
public class HashSet<E> extendsAbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable
{
private transient HashMap<E,Object>map;
// Dummy value to associate with an Objectin the backing Map
private static final Object PRESENT = newObject();
/*
*
* Constructs a new, empty set; the backing<tt>HashMap</tt> instance has
* default initial capacity (16) and loadfactor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
}














 775
775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









