






IO流7:其他IO技术介绍-下
7 DataInputStream & DataOutputSteram——操作基本数据类型的IO流
我们在《其他IO技术介绍-上》中曾经说道,ObjectInputStream和ObjectOutputStream是提供了用于操作基本数据类型的方法,但由于java.io包中,为我们提供了专门用于读写基本数据类型变量的IO流,因此对这一方面内容我们并没有进行过多的介绍,而这个IO流就是这一节将要介绍的DataInputStream和DataOutputStream。为便于叙述,我们将这两个流统称为数据读写流。
7.1 数据读写流概述
API文档:
DataInputStream:数据输入流允许应用程序以与机器无关方式从底层输入流中读取基本Java数据类型。应用程序可以使用数据输出流写入稍后由数据输入流读取的数据。
DataOutputStream:数据输出流允许应用程序以适当的方式将基本Java数据类型写入输出流中。然后,应用程序可以使用数据输入流将数据读入。
构造方法:
DataInputStream:
publicDataInputStream(InputStream in):使用指定的底层InputStream创建一个DataInputStream。
DataOutputStream:
publicDataOutputStream(OutputStream out):创建一个新的数据输出流,将数据写入指定基础输出流。
根据以上两个构造方法可知,创建数据读取/写如流时,均需要为其初始化一个字节读取/写入流对象,换句话说,真正实现从源中读取数据,或向目的写入数据的流是通过构造方法初始化的字节流。
方法:
数据读写流除了继承了字节读写流基本的读取(read)/写入方法(write)方法以外,提供了大量的读取/写入基本数据类型的方法。由于这些方法较为简单,易于使用这里就不再做详细说明,直接在下面内容中通过演示的方式进行介绍。
除此以外,我们再单独介绍用于读取/写入字符串的方法,
public final String readUTF():从包含的输入流中读取此操作需要的字节。
public final void writeUTF():以与机器无关方式使用UTF-8修改版编码将一个字符串写入基础输出流。
这里需要注意的是,writeUTF方法,使用了UTF-8修改版编码表,将指定字符串对应的字节写入到指定文件中。这里指的UTF-8修改版与一般的UTF-8编码表是不同的,因此使用writeUTF方法写入到文件中的数据,就只能用对应的readUTF方法读取,换句话说,字节转换流是不能读取的。
7.2 数据读写流使用演示
7.2.1 读取/写入基本数据
代码1:
import java.io.*;
class DataStreamDemo
{
public static void main(String[] args) throws IOException
{
writeData();//写入数据
readData();//读取数据
}
public static void writeData() throws IOException
{
DataOutputStream dos =
new DataOutputStream(new FileOutputStream("E:\\Data.txt"));
dos.writeInt(245);//写入整型值
dos.writeBoolean(false);//写入布尔值
dos.writeDouble(95.45);//写入双精度浮点值
dos.close();
}
public static void readData() throws IOException
{
DataInputStream dis =
new DataInputStream(new FileInputStream("E:\\Data.txt"));
//按照写入数据的顺序读取数据
int in = dis.readInt();
boolean bool = dis.readBoolean();
double dou = dis.readDouble();
System.out.println("in = "+in);
System.out.println("bool ="+bool);
System.out.println("dou ="+dou);
dis.close();
}
}in = 245
bool = false
dou = 95.45
执行以上程序后,将在指定目录中创建关联文件,文件大小为13个字节,一个整型值为4个字节,布尔值为1个字节,双精度浮点值8个字节,共13个字节,说明指定数据成功写入到了文件中。但若是双击打开关联文件,则显示为乱码,原因我们曾经解释过很多次,“.txt”格式的文本文件,对其中的字节数据按照用户指定的编码表进行查找。如果恰好写入的字节是某个字符的码值,那么就会显示对应的字符;若无法查找到字节数据对应的字符,虚拟机将自动查找编码表中的“未知字符区域”,并使用近似字符进行显示,也就是显示乱码。
在读取操作中需要注意的是,在向文件中写入多种类型的数据后,读取顺序必须与写入顺序相同,否则将会读取失败。比如,像代码1中所示,首先写入一个整型值,然后是一个布尔型值,最后是一个双精度浮点值,若先读取一个双精度浮点值,将会把整型值的4个字节,布尔值的1个字节和双精度浮点值的3个字节合并为一个双精度浮点值,显然这是错误的。
7.2.2 读取/写入字符串
在以下代码中,我们分别通过数据写入流的writeUTF方法按照UTF-8修改版编码表、为字节转换流指定UTF-8和GBK编码表,向三个文件中写入相同的文本内容“你好”,
代码2:
import java.io.*;
class DataStreamDemo2
{
public static void main(String[] args)throws IOException
{
writeStrByUTFChan();
writeStrByUTF();
writeStrByGBK();
}
//UTF-8修改版
public static void writeStrByUTFChan() throws IOException
{
DataOutputStream dos =
new DataOutputStream(newFileOutputStream("E:\\UTFFile.txt"));
dos.writeUTF("你好");
dos.close();
}
//UTF-8
public static void writeStrByUTF() throwsIOException
{
OutputStreamWriter osw =
new OutputStreamWriter(newFileOutputStream("E:\\UTFFile2.txt"),"UTF-8");
osw.write("你好");
osw.close();
}
//GBK
public static void writeStrByGBK() throwsIOException
{
OutputStreamWriter osw =
new OutputStreamWriter(newFileOutputStream("E:\\UTFFile3.txt"),"GBK");
osw.write("你好");
osw.close();
}
}执行以上代码将再同一个路径下创建三个“.txt”文本文件,写入内容都是相同的,但是通过UTF-8修改版编码表写入的内容,在“你好”前还多出来一个乱码字符,说明该编码表与UTF-8确实是不同的,而且并不是用来阅读的,只能通过DataInputStream对象的readUTF方法读取出来,如下代码所示,
代码3:
public static void readStrByUTFChan() throws IOException
{
DataInputStream dis =
new DataInputStream(newFileInputStream("E:\\UTFFile.txt"));
String str = dis.readUTF();
out.println(str);
dis.close();
}你好
如果用以上方法读取UTFFile2.txt或者UTFFile3.txt将会抛出EOFException。查阅DataInputStream类的readUTF方法的API文档可知,该异常将在此输入流读取到所有字节之前到达末尾就会被抛出。结合我们的例程来说,无论是读取UTFFile2.txt还是UTFFile3.txt,他们的字节数都不符合UTF-8修改版编码表的规则,也就是说,UTF-8修改版编码表中一个两个中文对应8个字节,但是读取到6个或者4个字节就达到了文件末尾,就表示使用了错误的编码表而造成读取失败。关于UTF-8及其修改版编码表具体的编码方式将在后面的内容作详细介绍。
8 ByteArrayInputStream &ByteArrayOutputStream——字节数组读写流
顾名思义,字节数组读写流就是用来操作字节数组的IO流。但是我们在之前的内容中所介绍的字节读写流(比如FileInputStream和FileOutputStream)也提供了对字节数组的操作功能,那么字节数组读写流又具备了哪些特别的功能呢?下面我们就对这两个IO流类进行介绍。
8.1 字节数组读写流概述
API文档:
ByteArrayInputStream:ByteArrayInputStream包含一个内部缓冲区,该缓冲区包含从流中读取的字节。内部计数器跟踪read方法要提供的下一个字节。字节数组读取流的功能相当于源,也就是说,将通过构造方法初始化的字节数据(构造方法部分将会介绍)存储到封装其内部的字节缓冲区(字节数组)中,并同时封装了一个指针(所谓的内部计数器)用于指向缓冲区中下次调用read方法将要返回的字节元素。该类的特点在于创建其实例对象时,并不是把某个硬盘文件或标准输入/输出设备与其进行关联,而是初始化一个字节数组(可能是从文件中读取到的字节数据,也可能是从网络中传输的字节数据),然后对该数组内的数据进行读取操作。
ByteArrayOutputStream:此类实现了一个输出流,其中的数据被写入一个byte数组。缓冲区会随着数据的不断写入而自动增长。可使用toByteArray()和toString()获取数据。该类的作用就是通过调用其write方法,将指定的字节数据写入到封装其内部的字节缓冲中,并且随着数据的不断写入,字节缓冲的长度也将不断增大,提高了开发效率,相比于我们之前的做法——手动创建一个固定长度为1024整数倍的字节数组,并向其中写入数据——要简便许多。另一个与常规字节写入流的不同之处是,由于不需要写入到文件中,因此也就不需要调用flush方法,取而代之的是调用toByteArray和toString方法获取写入到该类对象内部的数据。
这两个类的API说明中的最后部分都提到,关闭ByteArrayInputStream/ByteArrayOutputStream无效。此类中的方法在关闭此流后仍可被调用,而不会产生任何IOException。这是因为这两个类都不需要与文件或标准输入/输出设备关联,也就是说,不需要调用系统的底层资源,因此不需要调用这两类实例对象的close方法来关闭流。
构造方法:
public ByteArrayInputStream(byte[] buf):创建一个ByteArrayInputStream,使用buf作为其缓冲区数组。字节数组buf就是上述API文档中提到的内部缓冲区。该构造方法还有一个重载形式,将指定字节数组的一部分封装到字节数组读取流对象内部。
publicByteArrayOutputStream():创建一个新的byte数组输出流。缓冲区的容量最初是32字节,如有必要可增加其大小。创建字节数组写入流对象的同时,将在其内部创建一个字节缓冲,用于存储调用write方法写入到其内的字节数据。该构造方法还有一个重载形式,可以指定字节缓冲的大小。
方法:
无论是字节数组读取流还是字节数组写入流,由于它们直接继承自InputStream和OutputStream,因此提供了常规的读取/写入单个字节或者字节数组的read方法,以及字节数组读取流也具备一般读取流中的available、skip、close等方法,因此不再做具体说明,大家可以参考API文档。我们简单介绍一些字节数组读写流的特有方法,
ByteArrayOutputStream:
public int size():返回缓冲区大小。该方法将返回封装于字节数组写入流对象内部的字节缓冲区大小。
public byte[]toByteArray():创建一个新分配的byte数组。其大小是此输出流的当前大小,并且缓冲区的有效内容已复制到该数组中。该方法的作用相当于,将封装于字节数组写入流对象中的字节数据以数组的形式返回。
public String toString():使用平台默认的字符集,通过解码字节将缓冲区内容转换为字符串。新String的长度是字符集的函数,因此可能不等于缓冲区的大小。若字节数组读取流中存储的是某个字符串通过默认字符集转换而来的字节数组,那么该方法返回的就是源字符串。
public void writeTo(OutputStream out) throws IOException:将此byte数组输出流的全部内容写入到指定的输出流参数中,这与使用out.write(buf, 0, count)调用该输出流的write方法效果一样。该方法可以将该字节数组写入流对象内封装的字节数据一次性写入到指定的字节写入流中,该字节写入流可以可以与硬盘文件、标准输出设备关联,当然也可以是另一个字节数组写入流对象。注意该方法由于可能涉及到调用系统底层IO资源的写入流,因此会抛出IOException异常。
8.2 字节数组读写流使用演示
代码4:
import java.io.*;
class ByteArrayStreamDemo
{
public static void main(String[] args) throws IOException
{
//创建数据源,为其初始化一个字符串对应的字节数组
ByteArrayInputStream bis =
new ByteArrayInputStream("Hello World!".getBytes());
//创建数据目的
ByteArrayOutputStream bos =
new ByteArrayOutputStream();
//写入数据以前,字节数组写入流内部缓冲的长度
System.out.println(bos.size());
int data = 0;
while((data= bis.read()) != -1)
{
bos.write(data);
}
//写入数据之后,字节数组写入流内部缓冲的长度
System.out.println(bos.size());
//将存储于字节数组写入流内的数据转换为字符串
System.out.println(bos.toString());
//获取存储于字节数组写入流对象内的字节数组
byte[] bytes = bos.toByteArray();
System.out.println(newString(bytes));
//将存储于字节数组写入流对象内的字节数组,写入到指定文件中
bos.writeTo(newFileOutputStream("D:\\Demo.txt"));
}
}0
12
Hello World!
Hello World!
并且,Demo.txt文件中写入的内容同为“HelloWorld!”。
代码说明:
(1) 以上代码中,数据的读写方式与一般字节流的读写方式是一样的:通过循环调用读取流的read方法,返回一个个的字节,循环体中调用写入流的write方法将字节写入到其内部的字节缓冲中,直到达到读取流内数组末尾时返回-1,循环结束。
(2) 向字节数组写入流对象内写入数据前后,其内部的字节缓冲大小发生了变化,说明其缓冲大小确实是随着数据的写入而自动变长的。
(3) 由于字节数组读写流并未调用系统底层资源,因此不必像使用其他读写流那样,需要对IOException进行声明抛出或者try-catch处理。
根据我们在《IO流4:IO流操作规律》中的描述,操作IO流首先要明确数据源和数据目的,那么数据源的种类包括:硬盘,比如FileInputStream;标准输入设备——键盘,比如System.in;那么这里讲到的ByteArrayInputStream就是以内存为数据源的读取流。相对应的,数据目的也分为三种:硬盘,比如FileOutputStream;标准输出设备——控制台;ByteArrayOutputStream就是以内存为数据目的的写入流。之所以说操作数组的读写流是以内存为数据源和数据目的,是因为数组本身就像对象一样是存在于堆内存中的,而不存在于硬盘等其他介质中。
当我们需要把从一个文件中读取到字节数据临时存储到一个数组中对其进行操作,并且这些数据的量是不确定的情况下,将这些数据封装到字节数组读取流对象中,并结合字节数组写入流对这些数据进行操作,这就是字节数组读写流的用途。我们当然也可以手动创建一个字节数组存储数据,并通过if条件语句判断使来扩展这个数组的长度,但是使用java标准类库提供的现成工具类总是最高效的。此外,我们对于数组的操作,要么是设置某个角标位上的值,要么获取某个角标位上的值,那么设置与获取的操作对应到IO流就是写入和读取操作,因此我们说字节数组读写流就是在用IO流的思想操作字节数组。
以上就是关于字节数组读写流的简单介绍。实际上,Java标准类库java.io包中,除了提供了用于操作字节数组的IO流,还提供了用于操作字符数组的IO流——CharArrayReader和CharArrayWriter,和操作字符串的IO流——StringReader和StringWriter,以便于对纯文本文件中的数据进行操作。由于这一对读写流的用途与字节数组读写流基本相同,因此对外提供的方法也是类似的,只不过操作的数组是字符数组而非字节数组,有兴趣的朋友可以自行尝试。
9 字符编码
我们在前面的博客中曾经多次讲到与字符流相关的编码问题,那么之所以字符流能够用于操作字符,是因为在其内部封装了编码表,通过编码表可以实现字节与对应字符之间的相互转换。从更为基本的层面来说,真正在使用编码表进行字节与字符转换工作的其实是封装在字符流内部的转换流——InputStreamReader和OutputStreamWriter。除此以外,打印流——PrintStream和PrintWriter也可以指定编码表,并通过编码表对文本内容进行“打印”操作,但也仅限于打印,因此若要实现对字符数据的读写操作,还是要依靠转换流。那么关于编码首先要说的是编码表。
9.1 编码表的由来
计算机在底层操作的其实都是二进制数据,那么为了方便用户对文本数据(不同语言文字)进行操作,就将不同语言中的单个字符(比如英文中的字母,或中文中的汉字)与由若干二进制数字(通常由其十进制形式进行表示)的特殊组合一一对应起来,这些二进制数是由1和0通过不同的排列组合而得的。这种一一对应关系就形成了一张表格,这个表格就是编码表,计算机通过识别二进制数字之间的特殊组合,根据编码表反推出对应的字符。我们通过两个例子更为直观的了解编码表,比如在ASCII(后面的内容将说明)编码表中,字母“a”对应的编码值为97,其二进制形式为00110001,就像下表所示
| 字符 | 编码值(十进制) | 二进制码 |
| a | 97 | 00110001 |
再比如,在UTF-8编码表中汉字“你”,对应三个十进制数:-28、-67、-96,也就是说,这三个十进制数对应一个字符,如下表所示,
| 字符 | 编码值(十进制) | 二进制码 |
|
你 | -28 -67 -96 | 11100100 11011101 11010000 |
有了编码表以后,对文本的写入与读取操作就涉及到编码与解码。就像上文所说,既然计算机底层操作的都是二进制数字,将文本内容通过转换写入流(OutputStreamWriter)写入到文件时,最关键的步骤就是将字符串转换为字节数组(当然,真正存储在硬盘中的是对应的二进制数),而这一过程我们称为编码,可以理解为将我们人类的语言转换为计算机可以操作的数据,若想显示的进行这一操作,可以调用字符串的getBytes()方法,甚至可以通过传递指定的编码表,将字符串转换为对应的字节数组。此后,通过转换读取流(InputStreamReader)读取文件中的字节数据,并将其转换为原来的文本,这一过程我们称之为解码,而可以显示执行这一操作的方法就是创建一个新的字符串对象,向构造方法中传递表示字符对应编码值的字节数组,就像“new String(byte[])”,该构造方法还可以接收编码表,将字节数组通过指定的编码表转换为文本。
9.2 常见的编码表
(1) ASCII
ASCII,是英语AmericanStandard Code for Information Interchange的缩写,中文意思是美国标准信息交换代码。这一编码表使用一个字节8个二进制位中的后7位来表示一个字符。比如,字母a对应的编码值为97(字节值),将其转换为二进制数为01100001,下图表示的就是该二进制数值及其对应的二进制位,
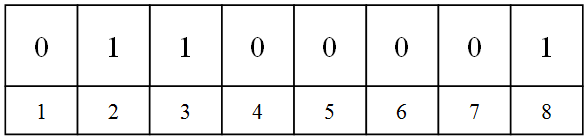
上图中最高位,也就是第一位上的二进制数值为0,这也是ASCII编码表中所有字符对应的二进制数的特点。除第一个二进制位以外,后七位二进制位上都会有对应的0或1的数值,那么将这7位转换为用十进制表示的字节值就是ASCII编码表中一个字符对应的编码值。
(2) ISO8859-1
世界上除了英语以外还有很多语言文字。比如,欧洲国家还有各国不同的语言,如法语、德语、意大利语等等,那么为了能够在计算机中操作欧洲国家的各种语言文字,就按照与ASCII编码表同样的方法将这些语言文字的字符与一个字节中的8位二进制数进行一一对应。之所以需要用到8位二进制数,是因为7位二进制数的组合已经被ASCII所占用,为避免重复将上图中第一位恒置为1,这样无论后7位二进制数如何进行排列组合都不会与ASCII重复,那么既然高位均为1,则其对应的字节数值均为负数。
(3) GBK
将汉字与二进制数的排列组合进行一一对应就形成了GBK编码表。而最早出现的汉字编码表称为GB2312,后期将包含其中的字符内容进行扩充就形成了GBK。GBK与前述两种编码表最大的区别在于,GBK是两个字节对应一个汉字字符,这是因为,一方面汉字字符的数量远大于英文和欧洲其他语言文字的字符,另一方面,GBK兼容ASCII(原因是为了表示汉语拼音),为了避免重复就将其中的字符统一使用两个字节数值进行对应。GBK中一个字符对应的两个字节其最高位均是1,也就是说,对应的字节值均为负数。后期将GBK中包含的字符进一步扩展以后又推出了GB18030。
(4) Unicode & UTF-8
Unicode编码表的特点是收录了世界上各个国家的语言文字(包括英文、中文等等),这样做的目的就是为了避免用户在不同编码表之间转换的麻烦。Java语言中char类型变量,就是使用的Unicode编码表来表示各种字符。与GBK相同,Unicode编码表中的每个字符均对应了两个字节值。这样一来,有些字符只需要一个字节就可以表示,却也浪费地占用了两个字节的空间(比如英文字母),为了对这一情况进行优化,人们进而研发出了UTF-8编码表——它是UnicodeTransform Format的缩写,意思是Unicode编码表的转换格式,而数字8的意思是,一个字符最少占用8个二进制位(一个字节),最多占用24个二进制位(三个字节)。此外,UTF-8编码表中每个字符对应的若干二进制数的高位都会加入一个标识头,而这个标识头的作用就是用于与其他编码表的编码值进行区分。
9.3 编码表之间的冲突
(1) 写入字符
容易想到,既然UTF-8和GBK都支持中文,那么同一个汉字在两个编码表中对应的码值是不一样的,如果某一篇中文文章使用GBK编码写入到文件中,而读取的时候却使用了UTF-8,就会出现乱码的问题,反之亦然,那么这里就涉及到了编码的转换问题。我们先通过以下例程来了解一下,不同编码表对同一个字符的不同表现形式,
代码5:
import java.io.*;
class EncodeStream
{
public static void main(String[] args) throws IOException
{
writeTextByGBK();//使用GBK编码表,写入“你好”两个字
writeTextByUTF();//使用UTF-8编码表,写入“你好”两个字
}
public static void writeTextByGBK() throws IOException
{
OutputStreamWriter osw =
new OutputStreamWriter(newFileOutputStream("E:\\GBK.TXT"),"GBK");
osw.write("你好");
osw.close();
}
public static void writeTextByUTF() throws IOException
{
OutputStreamWriter osw =
new OutputStreamWriter(newFileOutputStream("E:\\UTF.TXT"),"UTF-8");
osw.write("你好");
osw.close();
}
}我们就以“你好”为例,对以UTF-8的编码方式向文件中写入文本的过程进行说明。大家可以通过下面这个小小的代码来了解,汉字“你”和“好”在UTF-8编码表中分别对应了哪些字节数值,
代码6:
class Demo
{
public static void main(String[] args)
{
String str = "你好";
//指定按照"UTF-8"编码表,将字符串转换为字节数组
byte[] data = str.getBytes("UTF-8");
StringBuilder sb = new StringBuilder();
for(int x=0; x<str.length(); x++)
{
byte[] temp = Arrays.copyOfRange(data,x*3,x*3+3);
for(byteby : temp)
{
sb.append(by+"");
}
System.out.println(str.charAt(x)+":"+sb.toString());
sb.delete(0,sb.length());
}
}
}你:-28 -67 -96
好:-27 -91 -67
如果将编码表更改为“GBK”,然后将代码中的数字3改为2,就可以得到相同汉字在“GBK”编码表中对应的字节值,
你:-60 -29
好:-70 -61
那么实际上,当我们像代码5中那样,通过指定了编码表为“UTF-8”的转换写入流向文件中写入“你好”两字时,实际上真正存储在文件中的是这两个字对应的编码值“-28 -67 -96”以及“-27-91 -67”。那么为什么我们通过记事本软件打开“UTF.txt”文件时能够直接显示汉字,而不是编码值呢?这是因为记事本作为操作文本的软件,内部本身包含了多种编码表(比如GBK、UTF-8等等),当用户通过记事本打开某个文本文件时,软件就会读取该文件中的字节数据,并通过查找UTF-8编码表,将字节数据对应的字符显示在文本框中。大家可以通过记事本软件打开“UTF.txt”文件后,依次点击“打开”—“另存为”,最下面的“编码”一栏中显示的就是“UTF-8”,向“GBK.txt”写入“你好”也是同样的道理,不再赘述。
(2) 读取字符
通常,向流中写入字符一般不需要过多的注意什么,而问题常常出现在读取字符的阶段。下面的例程是正确的读取字符代码,这里我们将代码5创建的“GBK.txt”文件作为被读取文件,
代码7:
import java.io.*;
import java.util.*;
class EncodeStream2
{
public static void main(String[] args) throws IOException
{
readTextByGBK();
}
public static void readTextByGBK() throws IOException
{
//指定读取流通过"GBK"编码表,读取指定文件中的字符
InputStreamReader isr =
new InputStreamReader(newFileInputStream("E:\\GBK.txt"),"GBK");
char[] buf = new char[10];//仅为演示,定位缓冲长度为10
int len = isr.read(buf);
String str = new String(buf,0,len);
System.out.println(str);
}
}你好
以上代码的执行过程,我们曾经进行过详细的说明,这里再简单回顾一下:当调用转换读取流对象的read方法时,实际真正从文件中获取到是一系列字节数据(或者称为字节数组),因为需要对这些字节数据进行查表因此还要将这些字节数据存储到一个字节缓冲中。当字节缓冲被填满以后,就通过封装在内部的编码表,以两个字节数值为一组(针对GBK)进行查表动作,并将查的字符变量存储到用户指定的字符数组中。
以上是常规的字符读取过程,那么问题就出现在创建转换读取流时,指定错误的编码表,比如关联文件是通过GBK编码表将文本写入到文件中的,但是却指定按照“UTF-8”编码表来读取。大家可以尝试将传入到InputStreamReader构造方法中的编码表“GBK”更改为“UTF-8”,则执行结果为:“??”,表明未能成功读取文件中的字符。这是因为,一方面“你好”二字在“UTF-8”编码表中分别对应3个字节,共6个字节,但仅读取到4个字节;另一方面,“UTF-8”和“GBK”编码表中“你好”二字对应的字节值是不同的,因此可能无法查找到对应的字符,就使用两个未知字符“?”代替。当然,若指定的编码表为“UTF-8”,而关联文件是“UTF.txt”,就能够正常读取字符。
反过来,关联文件是“UTF.txt”,但却指定了“GBK”为编码表,同样会出现问题,指定结果为:“浣犲ソ”,虽然读取到了字符但是,却并不是“你好”,这也是错误的。那么为什么会读取到这三个奇怪的字符呢?道理也是一样的,“UTF-8”中“你好”对应的字节是“-28 -67 -96”和“-27 -91 -67”,而“GBK”中一个字符对应两个字节,那么读取时,首先将-28和-67作为一组进行查表,对应的字符就是“浣”,-96和-27对应的字符“犲”,-91和-67对应的字符就是“ソ”。
(3) 问题的重现与解决方法
以上内容我们是通过字符写入流向文件中写入文本的方式来说明编码转换中可能会产生的问题,但是这种方式不利于演示,因此以下例程中我们通过调用getBytes方法来模拟编码,通过String构造方法创建新字符串来模拟解码,重现编码转换中产生的问题,并为大家提供解决方法。
代码8:
import java.io.*;
import java.util.*;
class EncodeDemo
{
public static void main(String[] args) throws Exception
{
String source = "你好";
//使用默认编码表进行编码
byte[] data1 = source.getBytes();
System.out.println(Arrays.toString(data1));
//使用指定编码表GBK,进行编码
byte[] data2 = source.getBytes("GBK");
System.out.println(Arrays.toString(data2));
//使用默认编码表进行解码
String result1 = new String(data1);
System.out.println(result1);
//使用指定编码表GBK进行解码
String result2 = new String(data2,"GBK");
System.out.println(result2);
}
}[-60, -29, -70, -61]
[-60, -29, -70, -61]
你好
你好
以上代码是常规的编码解码过程,因此显示的结果是显然的,这里不再进行说明。而我们真正想要说明的问题是对于指定的文本进行了错误的编码,或者是进行了正确的编码却使用了错误的编码表解码,那么以下代码分别表示了这两种编码错误,
代码9:
import java.io.*;
import java.util.*;
class EncodeDemo2
{
public static void main(String[] args) throws Exception
{
String source = "你好";
//使用错误的编码表ISO8859-1进行编码
byte[] data = source.getBytes("ISO8859-1");
System.out.println(Arrays.toString(data));
String result = new String(data,"ISO8859-1");
System.out.println(result);
//使用了正确的编码表GBK编码,但解码时使用了错误的编码表ISO8859-1
byte[] data2 = source.getBytes("GBK");
System.out.println(Arrays.toString(data2));
String result2 = new String(data2,"ISO8859-1");
System.out.println(result2);
}
}[63, 63]
??
[-60, -29, -70, -61]
????
首先前两行结果表示,由于对中文字符错误地使用了ISO8859-1进行编码,但是该编码表中并没有收录中文汉字,因此虚拟机默认地使用该编码表中表示未知字符的码值(63)进行替换,后续再进行解码时打印的字符串就是两个问号。由于这一类错误是在编码时期发生的,因此后续的解码必然也无法正确进行,换句话说,是没有解决办法的,只能竭力避免此类错误的发生。
我们再来看后两行打印结果。在编码时期,使用了正确的汉字编码表“GBK”进行编码,这可以从打印的字节数组——4个负十进制数——看出。然而解码时使用了错误的编码表,由于“ISO8859-1”中虽然包含这四个负十进制数码值对应的字符,但却并不能正确的显示,因此解码得到的字符串就是4个问号。这一错误的发生虽然最终还是未能得到正确的源文本,但是我们通过第一步正确地编码得到了源文本对应的码值,因此还是有解决的办法的——对最终得到的错误字符再次使用“ISO8859-1”进行编码,获取原码值,然后再使用正确的编码表“GBK”进行解码即可,这一流程可用下图表示,
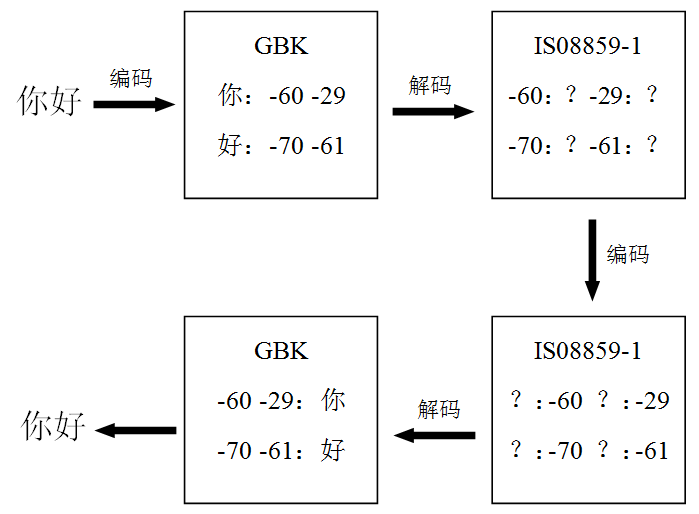
按照这一流程对代码9中第二种错误情况代码进行修改,如下所示,
代码10:
import java.io.*;
import java.util.*;
class EncodeDemo3
{
public static void main(String[] args) throws IOException
{
String str = "你好";
//对源文本进行正确的编码
byte[] data = str.getBytes();
System.out.println(Arrays.toString(data));
//对码值进行错误的解码
String wrongDecode = new String(data,"ISO8859-1");
System.out.println(wrongDecode);
//对解码后的未知字符使用“ISO8859-1”再次进行编码,获得原码值
data = wrongDecode.getBytes("ISO8859-1");
System.out.println(Arrays.toString(data));
//对再次编码得到的码值进行使用正确的编码表GBK进行解码
String correctDecode = new String(data,"GBK");
System.out.println(correctDecode);
}
}[-60, -29, -70, -61]
????
[-60, -29, -70, -61]
你好
通过以上的方法,分别增加一次编码和解码步骤,就可以将乱码转换为原字符串。可以看到先后两次编码得到的码值是一样的,这就是在这种错误情形下,能够将乱码恢复为正确文本的关键,如果第一次编码时就得到错误的码值,就无法再挽回了。
以上这种情况在实际开发过程中是真实存在的,比如当客户端向Tomcat服务端程序发送数据(包含一些文本数据)时,服务端程序真正接收到的是这些文本对应的GBK编码表字节数据,由于该服务端程序中仅包含“ISO8859-1”编码表,因此通过默认的方式解码客户端发送的文本数据就会出现乱码。此时,若要在服务端程序中获得正确的文本数据,就只能按照前述方法,对默认解码得到的乱码通过“ISO8859-1”进行编码,然后通过“GBK”再解码。
(4) 编码转换错误的特殊情形
通过增加一次编码和解码的步骤,虽然用于解决“GBK”和“ISO8859-1”编码表转换错误,但并不适用于所有编码表,比如使用“GBK”编码,却错误的使用“UTF-8”解码的情况,如下代码所示,
代码11:
import java.io.*;
import java.util.*;
class EncodeDemo4
{
public static void main(String[] args) throws IOException
{
String str = "你好";
//对源文本进行正确的编码
byte[] data = str.getBytes();
System.out.println(Arrays.toString(data));
//对码值进行错误的解码
String wrongDecode = new String(data,"UTF-8");
System.out.println(wrongDecode);
//对解码后的未知字符使用“ISO8859-1”再次进行编码,获得原码值
data = wrongDecode.getBytes("UTF-8");
System.out.println(Arrays.toString(data));
//对再次编码得到的码值进行使用正确的编码表GBK进行解码
String correctDecode = new String(data,"GBK");
System.out.println(correctDecode);
}
}[-60, -29, -70, -61]
???
[-17, -65, -67, -17, -65, -67, -17, -65, -67]
锟斤拷锟?
从结果来看,使用相同的方法却未能将乱码恢复为原文本。这是因为,UTF-8编码表中,一个字符可以对应1到3个十进制数字,那么使用由GBK编码表编码得来的4个负数去到UTF-8编码表中查找对应字符时,未能找到有效字符,就使用UTF-8编码表中的未知字符来替代,而这些未知字符对应的码值却并不是原来的4个负数,最关键的错误就发生在了这一处。而未知字符就是上面第二行结果显示的乱码,接着对这一行乱码使用UTF-8进行编码时得到了第三行结果所显示的9个负数,这已经与最初的码值完全不同了,因此最后再使用GBK对其进行解码得到的还是乱码。
那么前后两个例子使用相同的方法,却得到两种截然不同结果的原因就是,使用ISO8859-1编码表解码再编码不会修改原文本对应的码值,而UTF-8却改动了原编码值,导致最终无法恢复原文本。
最后给大作一个简单的总结:对于因为解码时使用了错误的编码表,而得到乱码的编码转换错误,仅有以下几种情形可以使用编码再解码的方式解决(这里仅讨论GBK、UTF-8和ISO8859-1):
(1) 对于使用UTF-8编码的字符,错误使用ISO8859-1或GBK解码得到乱码时,均可以对乱码进行编码再解码得到原文本;
(2) 对于使用GBK编码的字符,只能在错误使用ISO8859-1解码得到乱码时,可通过进行编码再解码得到正确原文本。
对于以上两种方法,大家可以自行尝试,这里不再过多赘述。
9.4 详解UTF-8编码表编码规则
在对UTF-8编码表的编码规则进行说明以前,我们首先举一个简单的例子。首先,在计算机任意路径下新建一个文本文档(“.txt”格式),然后打开该文档,写入“联通”两个字,然后保存并关闭记事本软件。再次打开该文件就会发现,原来写入的“联通”变成了两个乱码,就像这样“��ͨ”。此时,依次点击“文件”—“另存为”,在最下面“编码”对应的是UTF-8。那么这一问题依然出现在了解码阶段,因为当我们向记事本中写入文本内容时,通常会使用系统默认的编码表——GBK——对文本进行编码,然后将对应的码值写入到文件中,然而在我们打开文件阅读内容时,软件却使用UTF-8解码,这就是造成这一问题的原因。那么在对这一问题进行解释以前,首先需要了解UTF-8的编码规则。
在前面的内容中,我们曾简单介绍过UTF-8编码表,该编码表中的字符可以对应1至3个十进制数,但是在使用UTF-8编码表对现有码值进行识别时,是如何判断一次读一个码值,还是读两个或三个呢?这就涉及到UTF-8的编码规则。查阅API文档java.io包中的DataInputStream类readUTF(DataInputin)方法的说明文档,其中提到了UTF-8修改版,打开UTF-8修改版链接,向我们解释了UTF-8的编码规则(修改版相比原版,进行了一点改动,但不妨碍理解)。内容如下,
‘\u0001’到’\u007F’范围内的所有字符都是用单个字节表示的:

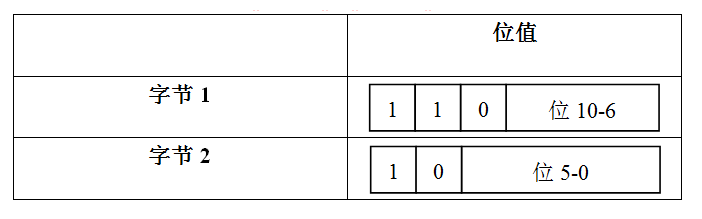
null字符‘\u0000’以及从’\u0080’到’\u07FF’的范围内的字符用两个字节表示:
‘\u0800’到’\uFFFF’范围内的char值用三个字节表示:
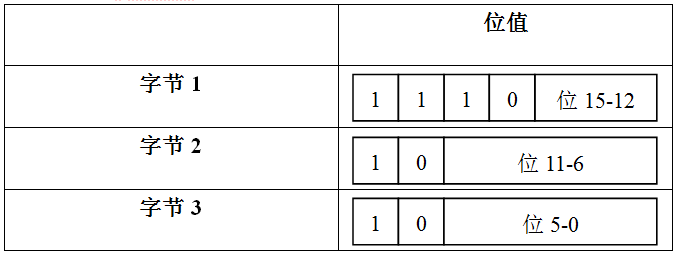
从上表可知,当一个字节对应一个字符时,该字节值的二进制形式高位为0;当两个字节对应一个字符时,第一个字节值的二进制形式高位为100,而第二个字节值高位为10;当三个字节对应一个字符时,第一个字节值的二进制形式高位为1000,第二和第三个字节二进制高位均为10。
这样在对UTF-8码值进行解码时,只需要判断码值对应的二进制数的高位,即可知道从该字节开始需要将几个字节组合起来去查找对应的字符。举一个例子,比如以下的二进制数组合,
“1100101010010101 01010100 11100100 10101010 10101010”
字符读取流首先读取到第一个字节对应二进制高位为110,则继续向后读取一个字节,并将这两个字节作为一个整体到UTF-8编码表中查找对应字符;读到第三个字节时发现,其高位为0,就拿这一个字节到编码表中查找字符(可认为这是一个ASCII字符);读取第四个字节时发现,其二进制高位为1110,就会继续向后连续读两个字节,并将这三个字节作为一个整体到UTF-8编码表中查找对应字符。以上就是UTF-8编码表的编码规则,其中的所有字符都是以这样的方式进行编码的。
介绍完了UTF-8的编码规则,我们再来说说上述“联通”的问题,阅读以下代码,
代码12:
import java.io.*;
class EncodeDemo5
{
public static void main(String[] args) throws IOException
{
String source = "联通";
byte[] data = source.getBytes("GBK");
for(byte by : data)
{
//将字节值转换为二进制字符串形式,并只保留低8位(有效位)
System.out.println(Integer.toBinaryString(by&255));
}
}
}11000001
10101010
11001101
10101000
细心的朋友可能已经观察出一些问题了:第一个字节的二进制数高位为110,第二个字节二进制数高位恰好为10;第三和第四个字节二进制数高位也分别是110和10,也就是说,在代码12中,“联通”两个汉字字符虽然是通过GBK进行编码的,但其码值二进制数在形式上恰好符合了UTF-8的编码规则,因此当记事本软件在读取“联通”的时候,就错误地使用了UTF-8解码,而出现了上述的乱码。以上就是关于发生“联通”错误的原因。那么如何才能解决向记事本软件写入“联通”时出现乱码的问题呢?只需要在“联通”两字前加入其它中文字符即可,只要保证该中文字符的在GBK中的码值二进制形式不符合UTF-8编码规则即可,那么软件在读取字符数据时就不会判断它是通过UTF-8编码的了。
10 改变标准输入输出设备
我们都知道System类的两个字段in和out分别表示标准输入设备——键盘和标准输出设备——控制台。那么我们能否将这两个字段的指向修改为指定设备呢?System类为我们提供了两个静态方法setIn和setOut,分别用于指定标准输入输出设备。
public static voidsetIn(InputStream in):重新分配“标准”输入流。将“标准”输入流设置为指定的字节读取流对象。
public static void setOut(PrintStreamout):重新分配“标准”输出流。将“标准”输出流设置为指定的打印流对象。
阅读以下代码,
代码13:
import java.io.*;
class StandardStreamDemo
{
public static void main(String[] args) throws IOException
{
//将“标准”输入流设置为与一个文件关联的字节读取流对象
//System.setIn(newFileInputStream("D:\\java_samples\\19th_day\\files\\source.txt"));
//将“标准”输出流设置为与一个文件关联的字节写入流对象
//System.setOut(newPrintStream("D:\\java_samples\\19th_day\\files\\dest.txt"));
BufferedReader bufr =
new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bufw =
new BufferedWriter(new OutputStreamWriter(System.out));
String line = null;
while((line= bufr.readLine()) != null)
{
if("over".equals(line))
break;
bufw.write(line);
bufw.newLine();
bufw.flush();
}
bufr.close();
bufw.close();
}
}如果打开第一行注释代码,将“标准”输入设备设置为与一个文本文件关联的字节读取流对象,那么执行效果就是将文件中的文本内容打印到控制台;
若我们继续注释第一行代码,而打开第二行代码,将“标准”输出设备设置为一个与文本文件关联的打印流(PrintStream)对象,那么执行效果就是将键盘录入的内容写入到文件中。这里我们稍微提一下PrintStream类。该类继承自FileOutputStream,换句话说,继承了所有的write方法及其重载方法,并且提供了以字符串的形式为其初始化一个文件的构造方法,因此使用方式与FileOutputStream基本相同,而在此基础上,PrintStream还提供了其他的特色方法,有兴趣的朋友可以自行查阅该类的API文档。
当然,如果将两行注释代码全部打开,最终的执行效果就是对文件的复制。
11 异常的日志信息
在这一小节中,我们将简单介绍,如何将IO流和异常处理代码结合起来。
11.1 异常处理回顾
首先我们回顾一下,在前面的内容中曾经提到的ArrayIndexOutOfBoundsException——数组角标越界异常,阅读以下代码,
代码14:
class ExceptionInfo
{
public static void main(String[] args)
{
try
{
int[] arr = new int[2];
int x = arr[3];
}
catch(ArrayIndexOutOfBoundsException e)
{
//将异常信息打印到控制台
e.printStackTrace();
}
}
}java.lang.ArrayIndexOutOfBoundsException: 3
at ExceptionInfo.main(ExceptionInfo.java:8)
以上代码中,由于访问到了不存在的数组角标位上的值,因此抛出了数组角标越界异常,并在catch代码块中捕捉到该异常以后,调用异常对象的printStackTrace方法,将异常信息打印到了控制台。
11.2 异常日志
以上例程,就是我们曾经使用过的异常处理方法。但是,这样简单的处理方式在实际开发过程中是不应该使用的。因为,用户通常使用的程序是没有控制台的,即使有控制台,用户在接收到这样的异常信息以后也是无法处理的。
因此,有一种常用的异常处理方式就是,将用户在使用过程中发生的异常,通过网络发送到服务器,服务器接收到这些异常信息以后,将其写入到异常日志文件中,那么维护人员定期去查阅这些文件,就可以知道发生了哪些异常,并针对性的对代码进行修改。下面我们就通过代码来模拟这个过程,但要省去网络环节,直接将异常信息写入到同意计算机中的日志文件中。
在进行代码编写以前,我们首先来查阅Exception的父类——Throwable的API文档。该类中定义了printStackTrace以及重载方法printStackTrace(PrintStream)。重载方法的参数类型PrintStream,同样也是System.out所指向的“标准”输出流的类型——打印流,因此如果将代码2中调用printStackTrace方法的代码修改为“e.printStackTrace(System.out)”,结果是相同的——将异常信息打印到控制台。那么实际上,空参数printStackTrace方法在底层就是调用的其重载形式,然后通过System.out传递了一个PrintStream对象。那么由此我们就可以想到,在调用printStackTrace方法的时候,传递与异常日志文件关联起来的打印流对象,就可以实现异常信息的记录。代码如下所示,
代码15:
import java.io.*;
class ExceptionInfo2
{
public static void main(String[] args)
{
try
{
int[] arr = new int[2];
int x = arr[3];
}
catch(ArrayIndexOutOfBoundsException e)
{
PrintStream ps = null;
//按照指定格式获取异常发生时间
SimpleDateFormat sdf = new SimpleDateFormat("yyyy.MM.dd-HH:mm:ss");
String currentTime = sdf.format(new Date());
try
{
ps= new PrintStream("ExceptionInfo.log");
}
catch(FileNotFoundExceptione2)
{
throw new RuntimeException("异常日志文件创建失败!");
}
//将异常发生时间一同写入到异常日志中
ps.print(currentTime+": ");
//关闭打印流
ps.close();
//将异常信息写入到异常日志文件中
e.printStackTrace(ps);
//第二种方式
//将标准输出设备从控制台修改为打印流对象
//System.setOut(newPrintStream("ExceptionInfo.log"));
//e.printStackTrace();
}
}
}这里需要说明两点:
(1) 由于PrintStream类的构造方法抛出FileNotFoundException异常,因此需要对创建PrintStream对象的代码进行try-catch处理,如代码3所示。
(2) 注释部分代码是记录异常日志的第二种实现方式,通过System的setOut方法将“标准”输出设备更改为与异常日志文件关联起来的打印流对象,最终效果是相同的。
(3) 通常日志文件的文件格式为“.log”。
(4) 除了异常信息以外,我们还希望获取到异常发生的具体时间。因此在catch代码块内,通过SimpleDateFormat对象,按照指定格式获取到当前时间,再通过PrintStream类的print方法将该时间写入到异常日志中。
实际开发中,日志信息可以使用工具包“log4j”中的各种工具类来实现,而不必手动编写日志记录代码,并且使用该工具包获得日志文件格式更为美观易读。















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









