







LkT的查询步骤
上文中提到了IR树构建。那么构建好IR树以后是如何处理一个查询的呢?,用到了一个优先队列来记录访问的节点和对象。
由MINDst(Q,N)来决定访问那个节点。当K个对象找出来后,算法将停止。伪代码如下:

首先拿上一篇提到的数据进行计算。输入的k=1
得到如下的值:

可以根据表格解释一下相关数据:
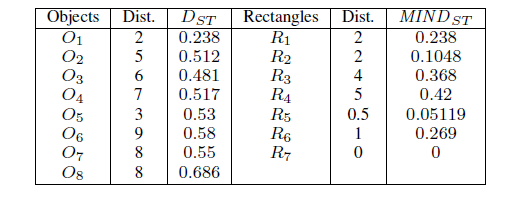
(1) Dequeue R7, enqueue R5 and R6.
Queue:f(R5,0.05119),(R6,0.269)
Queue:f(R5,0.05119),(R6,0.269)
对比发现R5<R6,因此访问R5
(2) Dequeue R5, enqueue R1 and R2.
Queue:f(R2,0.1048),(R1,0.238),(R6,0.269)
Queue:f(R2,0.1048),(R1,0.238),(R6,0.269)
R2小于R1,访问R2
(此时0.238是阈值)
(3) Dequeue R2, enqueue O3, O4 and O8.
Queue:f(R1,0.238),(R6,0.269),(O3,0.481),(O4,0.517),
(O8,0.686)。发现没有小于0.238的值,因此访问R1
Queue:f(R1,0.238),(R6,0.269),(O3,0.481),(O4,0.517),
(O8,0.686)。发现没有小于0.238的值,因此访问R1
(4) Dequeue R1, enqueue O1 and O2.
Queue:f(O1,0.238),(R6,0.269),(O3,0.481),(O2,0.512),
(O4,0.517),(O8,0.686)
Queue:f(O1,0.238),(R6,0.269),(O3,0.481),(O2,0.512),
(O4,0.517),(O8,0.686)
发现O1是最近且满足查询的目标。将O1输出。
可以由上述数据看到O1,节点R7、R5,R2,和R1被访问了。本应该只访问R1而不访问R2,但是访问R2的原因是R2的MINDst比R1的要低。这是为什么呢?
可以看到O3的Chinese出现值高,O4restaurant的出现值高,因此综合起来在R2才会被访问。但单单O3和O4并不是我们要找的对象。















 1420
1420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









