










鸿蒙NEXT开发实战往期必看文章:
一分钟了解”纯血版!鸿蒙HarmonyOS Next应用开发!
HarmonyOS NEXT应用开发案例实践总结合(持续更新......)
HarmonyOS NEXT应用开发性能优化实践总结(持续更新......)
简介
ArkTS是HarmonyOS APP的开发语言,它在保持TypeScript(简称TS)基本语法风格的基础上,一方面规范强化静态检查提升开发者代码的规范性;另一方面基于TypeScript增强了一些特性提升开发体验和执行效率,尤其是在并发能力上的提升。
本文档主要面向HarmonyOS APP的设计人员或开发人员,介绍应用在并行任务方案设计过程中,可能会遇到的典型场景以及对应的推荐设计方案,同时给出了方案的关键点及参考案例。
典型业务场景
根据当前HarmonyOS APP开发过程中遇到的实际并发业务场景,总结提炼出如下典型场景,可供更多APP参考,设计其并发业务方案。
| 场景编号 | 场景分类 | 场景名称 | 简述 |
| 1 | 并发能力选择 | 耗时任务并发执行 | 相对独立的耗时任务需要放到单独的子线程中执行,推荐TaskPool |
| 2 | 常驻任务并发执行 | 常驻的耗时任务需要放到单独的子线程中执行,推荐Worker | |
| 3 | 共享内存并发业务 | 开发常见的共享内存并发业务,推荐使用TaskPool和Worker的API进行开发 | |
| 4 | 长时任务并发执行 | 长时间运行的任务,不独占线程执行,推荐TaskPool长时任务 | |
| 5 | 并发任务管理 | 多任务关联执行(串行顺序依赖) | 有严格执行顺序的任务,不希望并发执行 |
| 6 | 多任务关联执行(树状依赖) | 待执行的任务存在依赖关系,等待被依赖执行完再调度 | |
| 7 | 多任务同步等待结果(任务组) | 多个关联的任务需要等待全部结果返回后再进行后续操作 | |
| 8 | 多任务优先级调度 | 不同任务设置不同的优先级 | |
| 9 | 任务延时调度 | 任务不希望立即执行,希望延时一定时间后调度 | |
| 10 | 线程间通信 | 同语言线程间通信(ArkTS内) | 介绍ArkTS线程间的通信机制 |
| 11 | 跨语言多线程通信(C++与ArkTS) | 介绍C++与ArkTS线程间的通信机制 | |
| 12 | 线程间模块共享(单例模式) | 介绍进程内单例场景的实现方式 | |
| 13 | 线程间不可变数据共享 | 介绍不可变数据共享场景的实现方式 | |
| 14 | 生产者与消费者模式 | 介绍生产者与消费者模式场景的实现方式 |
并发能力整体架构
并发能力概述
并发能力框架如下:
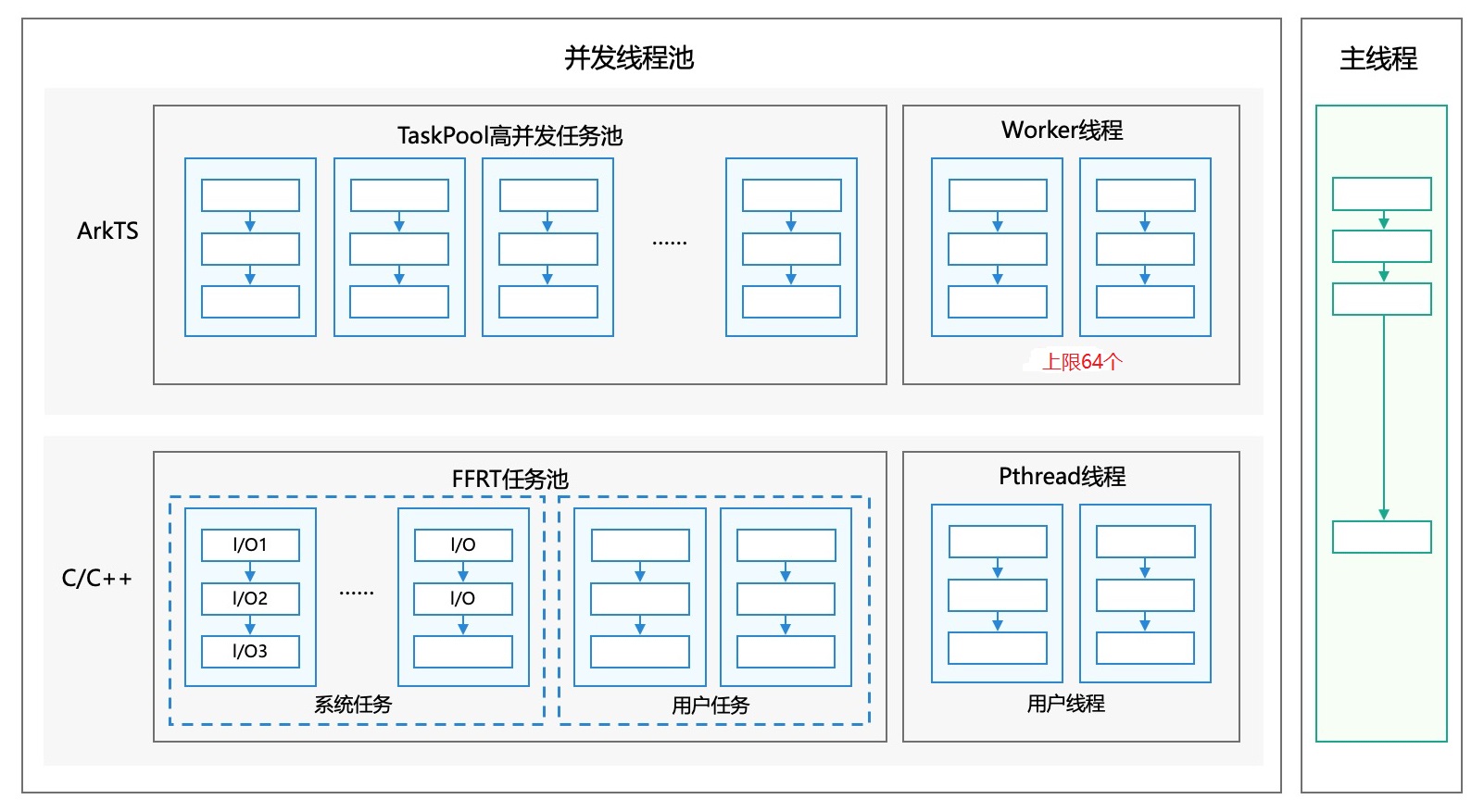
- 主线程:执行UI业务、不耗时操作、单次I/O任务,与其他ArkTS线程共享系统I/O线程池,不阻塞当前ArkTS线程。
- TaskPool高并发任务池:执行耗时任务,基于TaskPool封装任务执行的入口,可统计模块负载,开发者无需管理线程实例的生命周期。
- Worker线程:执行常驻任务,CPU密集型、耗时任务,当前限制线程个数为64。
- FFRT任务池:
- 系统任务:系统分发到FFRT线程的业务,例如异步I/O任务等,开发者无需关注;
- 用户任务:开发者创建的C/C++耗时任务,支持负载均衡及线程生命周期管理等能力。
- Pthread线程:采用C/C++开发的模块,需要后台运行或者耗时的ArkTS无关业务,不限制线程个数。
并发模型与业界模型的差异
共享内存并发模型
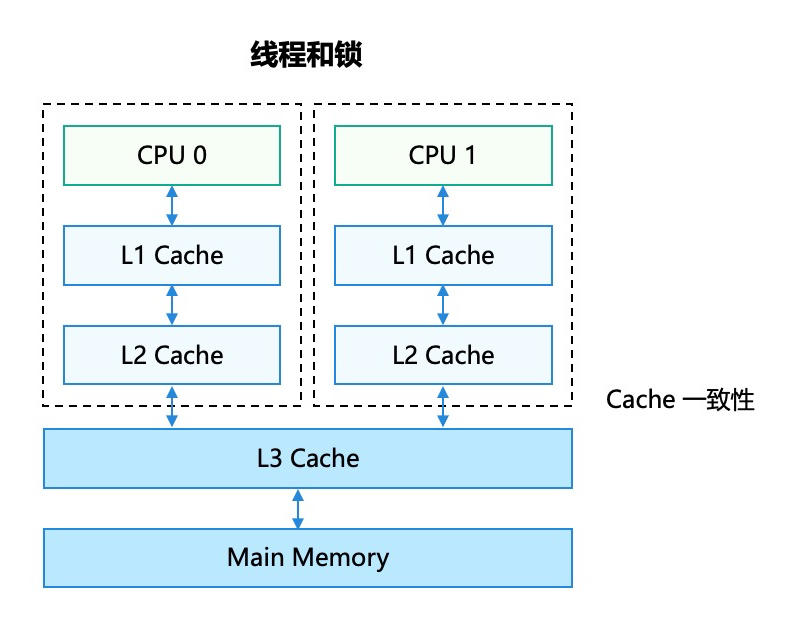
共享内存模型指的是采用线程和锁的并发模型,不同线程之间共享内存,通过锁来进行临界区保护。对于不同业务,如果包含I/O操作或者锁,为了业务不被阻塞,需要开启多个线程来执行不同的业务,线程情况如下图所示:
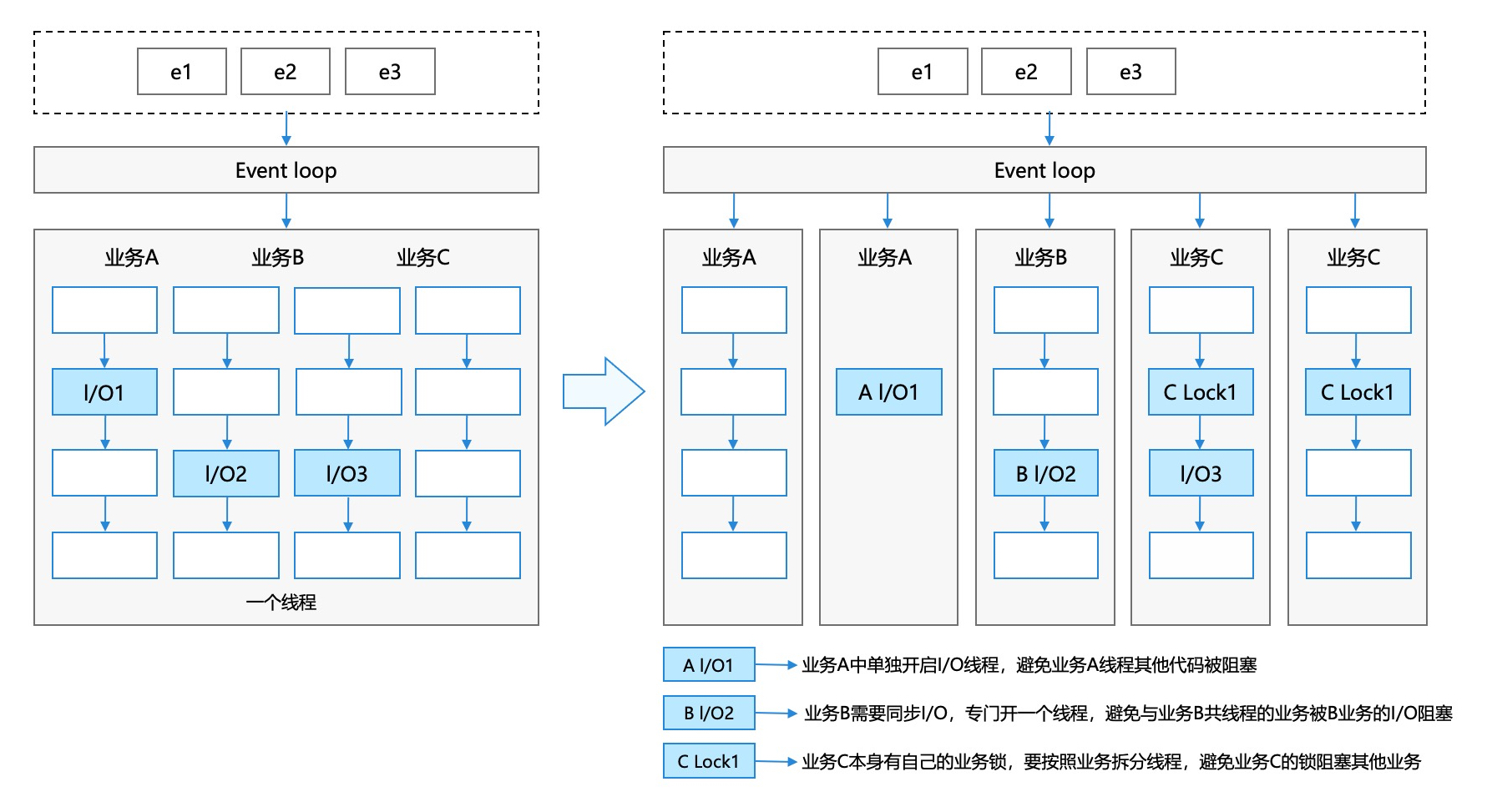
因此,应用上经常存在几百个线程,增加了调度开销和内存占用。
ArkTS并发模型
ArkTS采用了内存隔离的线程模型,不同线程之间通过消息通信,线程内无锁化运行。对于不同业务,其内部的I/O操作会由系统分发到后台的I/O任务池,不阻塞ArkTS上层逻辑,线程情况如下图所示:
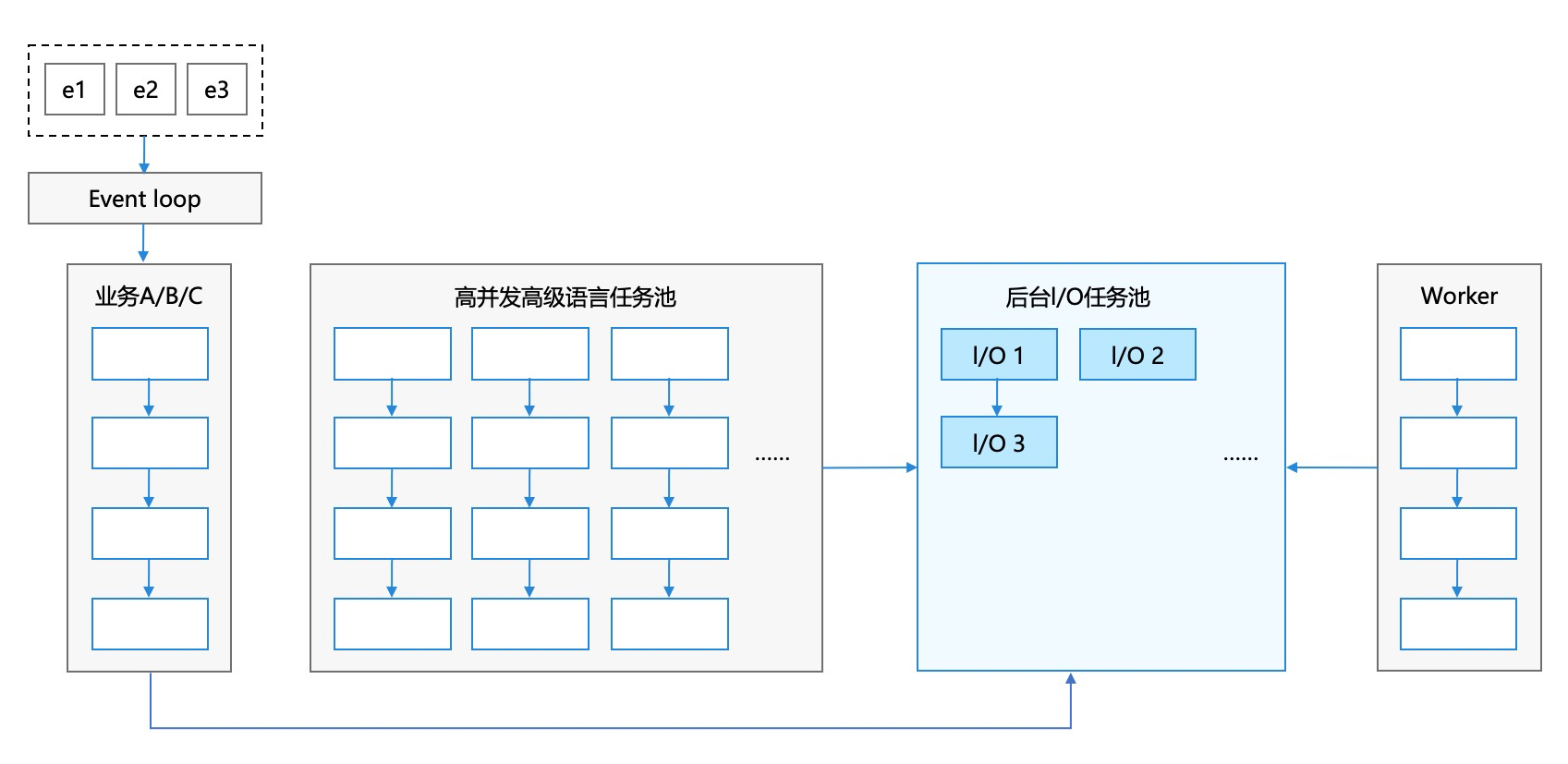
异步I/O不阻塞ArkTS线程,同时TaskPool及I/O线程池由系统管理,提升能效。
ArkTS语言支持了TaskPool和Worker的并发能力,接下来简单介绍TaskPool和Worker的功能。
TaskPool的运作机制可参考TaskPool简介,TaskPool提供了任务分发的入口,支持将任务分发到不同优先级的队列,TaskPool底层自动管理了一定数量的工作线程,会从队列获取任务执行。同时,工作线程会根据任务数量进行自动扩缩容,保证任务执行效率。TaskPool内部会根据任务量及当前线程数量,决定是否扩容或缩容,当任务较多时会扩容。线程的上限跟硬件核数相关,例如8核设备,线程数上限大概为7-15左右。
Worker的运作机制可参考Worker简介,空任务的Worker线程的内存占用大约2MB左右,因此需要控制线程的数量,避免内存过大。
ArkTS与传统共享内存并行化的差异
通过上述并发模型的对比,可以看出在ArkTS中的异步I/O操作,会分发到I/O任务池中,不阻塞ArkTS语言的执行。而Java需要大量线程进行阻塞I/O操作,导致线程数较多。
其次,ArkTS采用内存隔离的并发模型,不能跨线程共享对象,需要进行线程间数据通信。而Java可以直接访问不同线程的对象,但是需要使用锁进行数据的线程安全保护。
并发能力选择
概述
不同的业务场景用到的并发能力各不相同,此章节对常见的业务场景进行分类,并分别介绍各类业务场景的HarmonyOS APP开发方案设计。
耗时任务并发执行场景
- 场景描述
在应用业务实现过程中,对于相对独立的耗时任务,如果放在主线程中执行会阻塞主线程的UI业务,出现卡顿丢帧等影响用户体验的问题。通常需要将这个独立的耗时任务放到单独的子线程中执行。典型的耗时任务有CPU密集型任务、I/O密集型任务以及同步任务。
常见的业务场景如下所示:常见业务场景
具体业务描述
场景类型
CPU密集型
I/O密集型
同步任务
图片/视频编解码
将图片或视频进行编解码再展示
√
√
×
压缩/解压缩
对本地压缩包进行解压操作,或者本地文件的压缩操作
√
√
×
JSON解析
对JSON字符串的序列化和反序列化操作
√
×
×
模型运算
对数据进行模型运算分析等
√
×
×
网络下载
密集网络请求下载资源、图片、文件等
×
√
×
数据库操作
将聊天记录、页面布局信息、音乐列表信息等保存到数据库,或者应用二次启动时,读取数据库展示相关信息
×
√
×
上述业务场景均为独立的耗时任务,任务执行周期短,跟外部交互较少,只包含有限的输入和输出,分发到后台线程执行后再获取结果。这些类型的任务使用TaskPool可以简化开发工作量,避免管理复杂的生命周期,避免线程泛滥,开发者只需要将上述独立的任务放入TaskPool队列,再等待结果即可。
- 实现方案介绍
ArkTS提供了任务池(TaskPool)的并发能力,可以将独立的耗时任务分发到子线程中执行,满足上述业务场景并行化执行的诉求,开发者只需要如下三个步骤即可完成任务并发编程。实现方案介绍:
步骤一:将需要在子线程执行的任务封装成一个@Concurrent修饰的函数;
步骤二:通过TaskPool的任务执行接口将任务分发到子线程;
步骤三:异步执行结束后在宿主线程接收结果,进行后续处理。
- 业务实现中的关键点
- TaskPool中执行的任务需要考虑通信开销
由于TaskPool底层采用内存隔离的并发模型,对象的跨线程传输存在性能开销,需要控制线程间传递对象的大小及交互频率(200KB的典型耗时约1ms)。
- TaskPool中执行的任务不能因阻塞,导致执行时间过长(非异步耗时不超过3分钟)
由于执行时间较长的任务会占据任务池中的线程,导致其他任务没有空闲线程调度,因此对于一直占据任务线程执行超过3分钟的任务,系统会进行回收。
网络下载、文件访问等异步I/O操作系统会分发到I/O线程池,不受上面规则约束。
- TaskPool中执行的任务不能有上下文依赖
由于TaskPool任务会在子线程中执行,与宿主线程上下文环境存在差异,因此需要保证任务的独立性,内部实现只能依赖模块化导入或者参数传入。
- TaskPool中执行的任务需要考虑通信开销
- 案例参考
import { taskpool } from '@kit.ArkTS'; @Concurrent async function foo(a: number, b: number) { return a + b; } taskpool.execute(foo, 1, 2).then((ret: Object) => { // 结果处理 console.log('Return:' + ret); }) - 与业界方案特殊差异说明
业界均采用线程池方案,与TaskPool无特殊差异。
- 不推荐应用实现方式
对于独立的耗时任务,不建议采用Worker来实现。
常驻任务并发执行场景
- 场景描述
在应用业务实现过程中,对于一些长耗时(大于3min)且并发量不大的常驻任务场景,使用Worker在后台线程中运行这些耗时逻辑,避免阻塞主线程而导致出现丢帧卡顿等影响用户体验性的问题 。
常驻不是指可以在后台保活运行的任务,而是相比于短时任务,时间更长的任务,可能与主线程生命周期一致。
常见的业务场景如下所示:
常见业务场景
具体业务描述
场景类型
游戏中台场景
启动子线程作为游戏业务的主逻辑线程,UI线程只负责渲染
常驻任务
产线硬件压测
需要阻塞调用硬件能力,做老化测试,阻塞式
阻塞任务
- 实现方案介绍
ArkTS提供了Worker的并发能力,支持Worker线程与宿主线程之间进行通信,开发者需要主动创建或关闭Worker线程。实现方案介绍:
步骤一:创建Worker对象;
步骤二:在Worker线程中绑定Worker对象,并处理需要在子线程执行的逻辑;
步骤三:宿主线程可以与子线程双向通信,处理数据。
- 业务实现中的关键点
- Worker的生命周期需要开发者自行维护
由于Worker一旦被创建不会主动被销毁,若不处于任务状态一直运行,在一定程度上会造成资源的浪费,需要及时关闭空闲的Worker。
- 同时运行的Worker子线程数量有限(64个)
- Worker的一些监听事件的回调
onmessage:表示宿主线程接收到来自其创建的Worker通过子线程postMessage接口发送的消息时被调用的事件处理程序,处理程序在宿主线程中执行。
onerror:表示Worker在执行过程中发生异常被调用的事件处理程序,处理程序在宿主线程中执行。
onmessageerror:表示当Worker对象接收到一条无法被序列化的消息时被调用的事件处理程序,处理程序在宿主线程中执行。
onexit:表示Worker销毁时被调用的事件处理程序,处理程序在宿主线程中执行。
- Worker的生命周期需要开发者自行维护
- 参考链接
- 与业界方案特殊差异说明
与业界方案一致,均采用独立线程执行常驻任务。
- 不推荐应用实现方式
常驻任务不推荐作为任务分发给TaskPool。
传统共享内存并发业务
- 场景描述
当前HarmonyOS APP开发过程中,绝大多数应用都是通过共享内存模型语言(接下来以Java对比)开发的原型应用迁移过来的。其中,并发多线程是差异较大的部分,开发者在应用初期调研阶段需要考虑并发的差异性,再设计应用的架构。
- 实现方案介绍
ArkTS语言的并发多线程开发,推荐使用TaskPool和Worker的API进行开发。
TaskPool偏向独立任务维度,该任务在线程中执行,无需关注线程的生命周期,为了线程池的调度效率,不建议执行常驻的任务。
Worker偏向线程的维度,支持长时间占据线程执行,需要主动管理线程生命周期。
- 业务实现中的关键点
对于Java上的I/O操作,需要在单独的线程中执行,HarmonyOS APP开发时不需要开启一个独占的线程进行。
对于Java上的并发,存在很多基于内存共享的跨线程对象访问及调用,HarmonyOS APP开发时需要注意内存隔离线程模型的差异,子线程任务需要相对独立,与外部的数据交互少,减少性能开销。
如果需要使用内存共享,当前可以通过Node-API到C++层进行共享,或者定义Sendable对象进行线程间线程间数据共享。
- 与业界方案特殊差异说明
对于Java上的I/O操作,需要在单独的线程中执行,HarmonyOS APP开发时不需要开启一个独占的线程进行。
对于Java上的并发,存在很多基于内存共享的跨线程对象访问及调用,HarmonyOS APP开发时需要注意内存隔离线程模型的差异,子线程任务需要相对独立,与外部的数据交互少,减少性能开销。
- 不推荐应用实现方式
控制并发任务的粒度,不推荐频繁跨线程交互。
长时任务并发执行场景
- 场景描述
在应用业务实现过程中,对于需要长时间运行的独立耗时任务,如果放在主线程中执行会阻塞主线程的UI业务,出现卡顿丢帧等影响用户体验的问题。通常需要将这个独立的长时任务放到单独的子线程中执行。
典型的长时任务场景如下所示:
常见业务场景
具体业务描述
定期传感器数据采集
周期性采集一些传感器信息(例如位置信息、速度传感器等),应用运行阶段常驻运行。
Socket端口信息监听
长时间监听Socket数据,不定时需要响应处理。
上诉业务场景均为独立的长时任务,任务执行周期长,跟外部交互简单,分发到后台线程后,需要不定期响应,以获取结果。这些类型的任务使用TaskPool可以简化开发工作量,避免管理复杂的生命周期,避免线程泛滥,开发者只需要将上诉独立的长时任务放入TaskPool队列,再等待结果即可。
- 实现方案介绍
ArkTS提供了任务池(TaskPool)的并发能力,可以将长时任务分发到子线程中执行,满足上诉业务场景并行化执行的诉求,开发者只需要如下三个步骤即可完成任务并发编程。实现方案介绍:
步骤一:将需要在子线程执行的任务封装成一个@Concurrent修饰的函数;
步骤二:通过TaskPool的长时任务执行接口将任务分发到子线程;
步骤三:任务执行过程中,不定期接收数据,返回给宿主线程处理。
- 业务实现中的关键点
长时任务不同于阻塞任务,长周期运行,但是每次执行不会阻塞线程很久。因此不推荐将需要独占线程的任务封装成长时任务。
- 案例参考
import { taskpool } from '@kit.ArkTS'; @Concurrent async function foo() { // 长监听等任务 taskpool.Task.sendData(); } function executeTaskPool() { let longTask: taskpool.LongTask = new taskpool.LongTask(foo); longTask.onReceiveData((msg: Object) => { // 监听回调 console.info(`onReceiveData, ${JSON.stringify(msg)}`); }); taskpool.execute(longTask).then(() => { console.info('execute'); }); } executeTaskPool(); - 与业界方案特殊差异说明
业界一般采用单独的线程池,HarmonyOS是可调度的任务。
- 不推荐应用实现方式
对于非常驻的长时任务,不建议采用Worker来实现。
说明
长时任务指的是长时间不间断运行的独立任务,例如监听某个事件,发起执行后不会再接收发起方的输入,虽然也可以使用worker(推荐常驻后台任务才使用worker),但是更推荐使用TaskPool,TaskPool更方便,资源消耗更低。TaskPool和Worker的实现特点对比。
并发任务管理
概述
目前已提供任务的不同执行方式,可以管理任务的执行顺序、优先级等,此章节对需要控制任务执行方式的场景进行分类,并分别介绍各类任务执行场景的HarmonyOS APP开发方案设计。
多任务关联执行(串行顺序依赖)
- 场景描述
在应用业务实现过程中,可以使用串行队列机制,使多个任务按照一定的顺序依次执行,而不会出现并发或乱序的情况。一般情况下,串行队列可用于保证任务执行顺序与数据的一致性,避免多线程竞争和死锁问题,也可以简化多线程编程,适用于后置任务对前置任务存在依赖等场景。
常见的业务场景如下所示:
常见业务场景
具体业务描述
API执行队列
调用模块接口,存在执行顺序要求
渲染指令队列
操作DOM树、渲染等,有时序要求
启动时遍历程序包
启动遍历小程序包、清理包、资源加载等串行操作
- 实现方案介绍
ArkTS提供串行队列(SequenceRunner)能力,可以将多个任务加入到串行队列中,使加入队列的任务按顺序执行,也可以创建多组串行队列分组管理,以满足上述场景对串行执行的要求,开发者可通过以下步骤完成串行任务队列的创建与执行。实施方案介绍:
步骤一:创建需要串行执行的任务task_1 ~ task_n;
步骤二:创建串行队列runner;
步骤三:按照需要执行的顺序,依次将任务添加至runner内。
- 业务实现中的关键点
- 添加到串行队列的任务,不支持添加依赖addDependency;
额外添加的任务依赖可能导致串行队列冲突,即使添加的依赖本身遵循串行队列顺序也会被拦截。
- 添加到串行队列的任务,同样也受TaskPool执行任务的约束与限制;
当串行队列任务中任务执行失败、或被cancel,后续任务依旧会被执行。
- 添加到串行队列的任务,不支持添加依赖addDependency;
- 案例参考
import { taskpool } from '@kit.ArkTS'; @Concurrent function additionDelay(delay: number): void { let start: number = new Date().getTime(); while (new Date().getTime() - start < delay) { continue; } } @Concurrent function waitForRunner(resString: string): string { return resString; } async function seqRunner() { let result: string = ""; let task1: taskpool.Task = new taskpool.Task(additionDelay, 300); let task2: taskpool.Task = new taskpool.Task(additionDelay, 200); let task3: taskpool.Task = new taskpool.Task(additionDelay, 100); let task4: taskpool.Task = new taskpool.Task(waitForRunner, 50); let runner: taskpool.SequenceRunner = new taskpool.SequenceRunner(); runner.execute(task1).then(() => { result += 'a'; }); runner.execute(task2).then(() => { result += 'b'; }); runner.execute(task3).then(() => { result += 'c'; }); await runner.execute(task4); console.info("seqrunner: result is " + result); } - 与业界方案特殊差异说明
对于串行队列中某个任务执行失败后处理,业界尚无统一规范。
当前HarmonyOS APP开发中实现方式为继续后续任务的执行,若后续任务依赖上一个任务的结果输出,开发者需考虑任务失败场景的异常处理。
多任务关联执行(树状依赖)
- 场景描述
任务依赖是一种用于管理并发任务执行顺序的管理机制。通过任务依赖,可以指定一个任务在另一个任务完成后才能执行,从而构建出复杂的任务执行流程。任务依赖可以帮助开发者控制任务之间的依赖关系,确保任务按照预期的顺序执行。在TaskPool中,任务依赖是通过使用addDependency和removeDependency实现的。
常见的业务场景如下所示:
常见业务场景
具体业务描述
场景类型
CPU密集型
I/O密集型
同步任务
图片解码
解析一张大图,将大图数据拆成n份并放到n个任务中执行,执行完后通过这n个任务都依赖的一个任务对结果进行处理并返回
√
√
×
数据库操作
A任务执行需要B任务执行结果。B任务执行完将结果更新到数据库,再执行依赖B的A任务,A任务从数据库中获取B任务结果
×
√
×
网络下载
A任务下载数据,B任务对数据进行处理。B任务执行依赖A任务结果
×
√
×
- 实现方案介绍
TaskPool目前提供addDependency(增加对其他任务的依赖)和removeDependency(移除对其他任务的依赖)两个接口,开发者可以通过调用这两个接口对任务设置依赖关系。任务默认不存在依赖关系,即不依赖其他任务和其他任务不依赖当前任务。
TaskPool内部维护一个任务依赖关系列表,调用addDependency/removeDependency对该列表进行数据更新。任务执行时前查询该列表,若该任务依赖其他任务,则该任务等待这些任务全部执行结束再执行;若该任务被其他任务依赖,则该任务执行结束会将依赖它的这些任务加入到Taskpool等待执行的队列中。
- 业务实现中的关键点
- 合理设置任务依赖关系。两个任务之间的执行不依赖对方的结果,则这两个任务无需设置依赖关系。
- 设置依赖关系需要考虑任务的优先级分配。避免高优先级任务依赖低优先级任务,造成高优先级设置失效。
- 任务依赖与任务组、串行队列的交互表现。已经执行过的任务不能设置依赖关系,任务组任务不能设置依赖关系,串行队列任务不能设置依赖关系,有依赖关系的任务执行结束后不能再次执行,有依赖关系的任务不能放入任务组,有依赖关系的任务不能放入串行队列。
- 案例参考
import { taskpool } from '@kit.ArkTS'; @Concurrent function updateSAB(args: Uint32Array) { if (args[0] == 0) { args[0] = 100; return 100; } else if (args[0] == 100) { args[0] = 200; return 200; } else if (args[0] == 200) { args[0] = 300; return 300; } return 0; } let sab = new SharedArrayBuffer(20); let typedArray = new Uint32Array(sab); let task1 = new taskpool.Task(updateSAB, typedArray); let task2 = new taskpool.Task(updateSAB, typedArray); let task3 = new taskpool.Task(updateSAB, typedArray); task1.addDependency(task2); task2.addDependency(task3); taskpool.execute(task1).then((res: object) => { console.info("taskpool:: execute task1 res: " + res); }) taskpool.execute(task2).then((res: object) => { console.info("taskpool:: execute task2 res: " + res); }) taskpool.execute(task3).then((res: object) => { console.info("taskpool:: execute task3 res: " + res); }) - 与业界方案特殊差异说明
业界实现的多数任务依赖机制,与TaskPool提供的任务依赖机制表现无明显差异。
多任务同步等待结果(任务组)
- 场景描述
复数个任务并发执行,等所有任务执行完毕后统一返回一个完整结果,其中任意一个任务失败或取消会导致整个任务的结果失败。
常见业务场景
具体业务描述
场景类型
图片解析生成直方图
一张图片,为了并发加速,拆分成多个ArrayBuffer进行解析,在所有任务解析完成后统一返回结果将解析结果拼成一个完整的直方图进行渲染
CPU密集型
- 实现方案介绍
任务组能力目前通过TaskPool模块提供,以图片生成直方图为例进行介绍。
步骤一:定义并发函数(@Concurrent function),将承载图片数据的ArrayBuffer的解析逻辑封装在一个并发函数中;
步骤二:遍历ArrayBuffer,每个ArrayBuffer对应构造一个并发解析任务,将这些任务都添加到任务组中;
步骤三:通过TaskPool执行任务组,并在回调函数中执行直方图的拼接逻辑或异常处理逻辑。
- 业务实现中的关键点
- 任务组中的任务应是为了达成统一的目的,所有关联任务会输出一个统一的结果。
- 任务组的结果会等待所有任务执行结束后统一返回,所以如果需要一组任务中先执行完的任务优先处理的场景不要使用任务组。
- 案例参考
import { taskpool } from '@kit.ArkTS'; // 定义异步任务 @Concurrent function imageProcessing(arrayBuffer: ArrayBuffer): ArrayBuffer { // 此处添加业务逻辑,输入为ArrayBuffer,输出为存储了解析结果的ArrayBuffer let message: ArrayBuffer = arrayBuffer; return message; } let taskGroup: taskpool.TaskGroup = new taskpool.TaskGroup(); let TASK_POOL_CAPACITY: number = 10; function histogramStatistic(pixelBuffer: ArrayBuffer): void { // 往任务组中添加任务 let byteLengthOfTask: number = pixelBuffer.byteLength; for (let i = 0; i < TASK_POOL_CAPACITY; i++) { let dataSlice: Object = (i === TASK_POOL_CAPACITY - 1) ? pixelBuffer.slice(i * byteLengthOfTask) : pixelBuffer.slice(i * byteLengthOfTask, (i + 1) * byteLengthOfTask); let task: taskpool.Task = new taskpool.Task(imageProcessing, dataSlice); taskGroup.addTask(task); } taskpool.execute(taskGroup, taskpool.Priority.HIGH).then((res: Object[]): void | Promise<void> => { // 结果数据处理 }).catch((error: Error) => { console.error(`taskpool excute error: ${error}`); }) }
多任务优先级调度
- 场景描述
优先级体现了任务对于应用当前业务场景的重要性。在并发场景下,系统和线程池的资源是有限的。在资源既定的情况下,系统会分配更多资源优先处理高优先级的任务,尽量保证此类任务的即时性,而低优先级的任务的调度则会相对滞后。TaskPool提供了多任务优先级调度机制,供开发者根据业务场景,合理设置优先级。
常见的业务场景如下所示:
常见业务场景
具体业务描述
场景类型
CPU密集型
I/O密集型
即时性
处理耗时的图片数据
拍摄输入或美化图片时会将图片数据放在TaskPool中处理,且需要在一定毫秒内将数据返回主线程渲染,为保证任务的即时性,影响用户体验,可以设置高优先级使任务被优先调度
√
×
√
日志落盘
将业务日志信息写到文件或数据库中,优先级较低
×
√
×
- 实现方案介绍
TaskPool提供了4种优先级属性: HIGH、MEDIUM、LOW、以及IDLE(高、中、低、后台)。
目前,仅有taskpool.Task支持优先级属性的设置(function类型不支持),默认优先级为MEDIUM。开发者可以通过taskpool.execute()接口在抛任务时显式指定优先级。
TaskPool底层对HIGH、MEDIUM、LOW任务的调度按照M:N:1进行,即每调用M个高优先级任务后会去调用1个中优先级任务。每调用N个中优先级任务后会去调用1个低优先级任务。通过配置比例关系,在保证高优先级任务优先执行的情况下,中优先级任务得到合理调度,低优先级任务不会饿死(目前M:N:1为5:5:1)。
优先级机制底层对接了QoS(quality-of-service),因此3种属性也对应着不同的线程优先级。高优先级的任务除了在TaskPool队列中会得到优先调度外,在CPU调度上也会获得更多的系统资源。
Priority的IDLE优先级是用来标记需要在后台运行的耗时任务(例如数据同步、备份。),它的优先级别是最低的。这种优先级标记的任务只会在所有线程都空闲的情况下触发执行,并且只会占用一个线程来执行。
- 业务实现中的关键点
- 合理设置高优先级的数量。某些场景下若有大量的高优先级任务,任务池将无法区分优先级差异,因此优先级调度可能退化成按入队顺序依次执行。此外,高优先级任务将会抢占系统资源,影响其他线程和应用的执行。
- 依赖多个任务的执行时需要考虑优先级的分配。避免高优先级任务依赖低优先级任务的执行,造成优先级倒置。
- 案例参考
import { taskpool } from '@kit.ArkTS'; function exec(bufferArray: ArrayBuffer): void { let task = execColorInfo(bufferArray); taskpool.execute(execColorInfo, taskpool.Priority.HIGH); } @Concurrent async function execColorInfo(bufferArray: ArrayBuffer): Promise<ArrayBuffer> { if (!bufferArray) { return new ArrayBuffer(0); } const newBufferArr = bufferArray; let colorInfo = new Uint8Array(newBufferArr); let PIXEL_STEP = 2; for (let i = 0; i < colorInfo?.length; i += PIXEL_STEP) { // 数据处理 } return newBufferArr; } - 与业界方案特殊差异说明
业界大多提供了优先级机制,与TaskPool中的优先级无明显差异。
- 不推荐应用实现方式
不推荐应用过多设置高优先级或者不合理的优先级。
任务延时调度
- 场景描述
在应用业务实现过程中,不是所有任务都需立刻执行,有些任务需延时一段时间后才需执行。
常见的业务场景如下所示:
常见业务场景
具体业务描述
缓存业务延时执行,不影响冷启动耗时
应用启动时,存在大量低优先级任务,例如二级界面的资源下载等,需要设置在3秒后执行,防止影响冷启动耗时
- 实现方案介绍
TaskPool提供了延时执行的能力,目前,只有taskpool.Task支持延时执行,开发者只需要如下三个步骤即可完成延时实现。实现方案介绍:
步骤一:创建Task对象;
步骤二:调用taskpool.executeDelayed实现延时执行,并在参数中依次填写延时时间:delayTime,执行任务:task,任务优先级(不填默认MEDIUM):priority;
步骤三:接收延时任务返回的数据并作处理。
- 业务实现中的关键点
- 非必需不建议使用任务延时调度。某些业务复杂的场景下使用任务延时调度可能会存在结果处理时序问题,从而导致应用业务出现问题。
- 不建议将多个任务延时到同一时间执行。这样会存在任务排队情况,从而导致有些任务不能在到达延时时间后立刻执行。
- 案例参考
import { taskpool } from '@kit.ArkTS'; @Concurrent function concurrentTask(num: number): number { console.log('这里添加需延时执行的任务'); return num; } // 创建任务 let task: taskpool.Task = new taskpool.Task(concurrentTask, 100); // 延时执行task taskpool.executeDelayed(3000, task, taskpool.Priority.HIGH).then((value: Object) => { // 处理延时任务返回的结果 console.log("taskpool result: " + value); }); - 与业界方案特殊差异说明
业界大多提供了任务延时调度功能,与TaskPool中的任务延时调度无明显差异。
- 不推荐应用实现方式
非必须场景不建议使用任务延时调度,防止延时结果处理时机不当。
线程间通信
概述
线程间通信指的是并发多线程间存在的数据交换行为,目前已支持ArkTS、C++等开发语言,因此存在不同语言、不同线程的通信场景,接下来详细展开介绍。
同语言线程间通信(ArkTS内)
- 场景描述
ArkTS线程指的是包含ArkTS运行环境的线程,包括主线程、TaskPool线程、Worker线程。它们之间可以通过不同的接口进行通信。
常见业务场景如下所示:
常见业务场景
具体业务描述
宿主JS线程<->TaskPool线程
通过使用TaskPool,分发任务到子线程。TaskPool子任务与其宿主线程之间需要通信的场景
宿主JS线程<->Worker线程
通过使用Worker,启动子线程,执行任务。Worker子线程与其宿主线程之间需要通信的场景
任意JS线程<->任意JS线程
除了上述两种线程外,其他任意两个JS线程需要通信的场景
- 实现方案介绍
跨线程交互场景
通信方式
通信优先级
宿主JS线程->TaskPool线程
参数传递后分发任务;过程中不支持正向通信
支持
TaskPool线程->宿主JS线程
结果返回;sendData触发宿主线程异步回调,底层为uv_async_send实现
不支持
宿主JS线程->Worker线程
采用postMessage&onmessage异步通信
不支持
Worker线程->宿主JS线程
异步方式:采用postMessage & onmessage异步通信
同步方式:支持Worker线程同步调用宿主线程注册的方法,并返回结果
不支持
任意JS线程<->任意JS线程
使用@ohos.emitter实现双向异步通信
支持
- 业务实现中的关键点
ArkTS线程推荐使用TaskPool及Worker的原生接口通信。
- 参考链接
- 与业界方案特殊差异说明
线程通信采用消息循环的机制,与业界一致。
跨语言多线程通信(C++与ArkTS)
- 场景描述
ArkTS线程指的是包含ArkTS运行环境的线程,包括主线程、TaskPool线程和Worker线程。由于HarmonyOS支持通过Node-API开发C++业务,用户可以在C++层创建线程,因此C++线程存在与ArkTS线程通信的场景。
常见业务场景如下所示:
常见业务场景
具体业务描述
ArkTS线程(ArkTS)<->pthread线程
ArkTS线程的ArkTS部分与pthread线程的通信场景
ArkTS线程(C++)<->pthread线程
ArkTS线程的C++部分与pthread线程的通信场景
pthread线程<->pthread线程
C++线程间的通信场景
- 实现方案介绍
跨线程交互场景
通信方式
通信优先级
ArkTS线程(ArkTS)->pthread线程
不支持,需要转到C++
不涉及
pthread线程->ArkTS线程(ArkTS)
采用napi_threadsafe_function通信
支持
pthread线程->ArkTS线程(C++)
ArkTS线程(C++)-> pthread线程
开发者自定义行为
开发者自定义行为
pthread线程<->pthread线程
- 案例参考
// napi_init.cpp struct CallbackData { napi_env env; uv_thread_t threadId; napi_async_work asyncWork = nullptr; napi_threadsafe_function tsfn = nullptr; int32_t data = -1; }; static void CallJs(napi_env env, napi_value jsCb, void* context, void* data) { CallbackData* callbackData = reinterpret_cast<CallbackData*>(data); napi_value global; assert(napi_get_global(env, &global) == napi_ok); napi_value number; assert(napi_create_int32(env, callbackData->data, &number) == napi_ok); assert(napi_call_function(env, global, jsCb, 1, &number, nullptr) == napi_ok); } static void NativeThread(void* data) { CallbackData* callbackData = reinterpret_cast<CallbackData*>(data); /* 跨线程调用*/ { assert(napi_acquire_threadsafe_function(callbackData->tsfn) == napi_ok); callbackData->data = 123456; napi_status status = napi_call_threadsafe_function(callbackData->tsfn, callbackData, napi_tsfn_blocking); assert(status == napi_ok); } } static void ThreadFinished(napi_env env, void* data, [[maybe_unused]] void* context) { CallbackData* callbackData = reinterpret_cast<CallbackData*>(data); assert(uv_thread_join(&(callbackData->threadId)) == 0); assert(napi_release_threadsafe_function(callbackData->tsfn, napi_tsfn_release) == napi_ok);; callbackData->asyncWork = nullptr; callbackData->tsfn = nullptr; delete callbackData; } static napi_value NativeCall(napi_env env, napi_callback_info info) { napi_value resourceName = nullptr; CallbackData* callbackData = new CallbackData; callbackData->env = env; napi_value jsCb = nullptr; size_t argc = 1; assert(napi_get_cb_info(env, info, &argc, &jsCb, nullptr, nullptr) == napi_ok); assert(argc == 1); assert(napi_create_string_utf8(env, "Call thread-safe function from c++ thread", NAPI_AUTO_LENGTH, &resourceName) == napi_ok); napi_status status; status = napi_create_threadsafe_function(env, jsCb, nullptr, resourceName, 0, 1, callbackData, ThreadFinished, callbackData, CallJs, &(callbackData->tsfn)); assert(status == napi_ok); assert(uv_thread_create(&(callbackData->threadId), NativeThread, callbackData) == 0); return nullptr; } // Index.ets Button('click me') .onClick(() => { nativeModule.nativeCall((a: number) => { console.log('Received data from thread-function: %{public}d', a); }) }) - 与业界方案特殊差异说明
- Java与C++通信时,业界通过JNI调用,与Node-API机制比较类似。
- Java与C++通信时,业界支持C++线程通过attach方式直接反射调用Java方法,而HarmonyOS APP开发时需要通过napi_threadsafe_function异步通信。
- 不推荐应用实现方式
不建议为了同步调用,在C++层增加wait等机制,会导致卡死、掉帧等问题。
线程间模块共享(单例模式)
- 场景描述
某些进程唯一的ArkTS实例初始化流程复杂,整体耗时长,放在主线程中对其进行初始化会造成应用启动耗时久和阻塞主线程的执行。将这些实例的初始化流程放在ArkTS子线程中进行初始化,初始化完成后主线程可以直接使用该实例。
常见的业务场景如下所示:
常见业务场景
具体业务描述
SDK初始化
在ArkTS子线程中调用API的Init初始化得到一个单例对象,完成后传给其他ArkTS线程使用
- 实现方案介绍(方案一)
步骤一:采用C++单例模式封装,上层封装JS壳,子线程进行初始化;
步骤二:初始化完成通知主线程,主线程导入使用该单例对象。
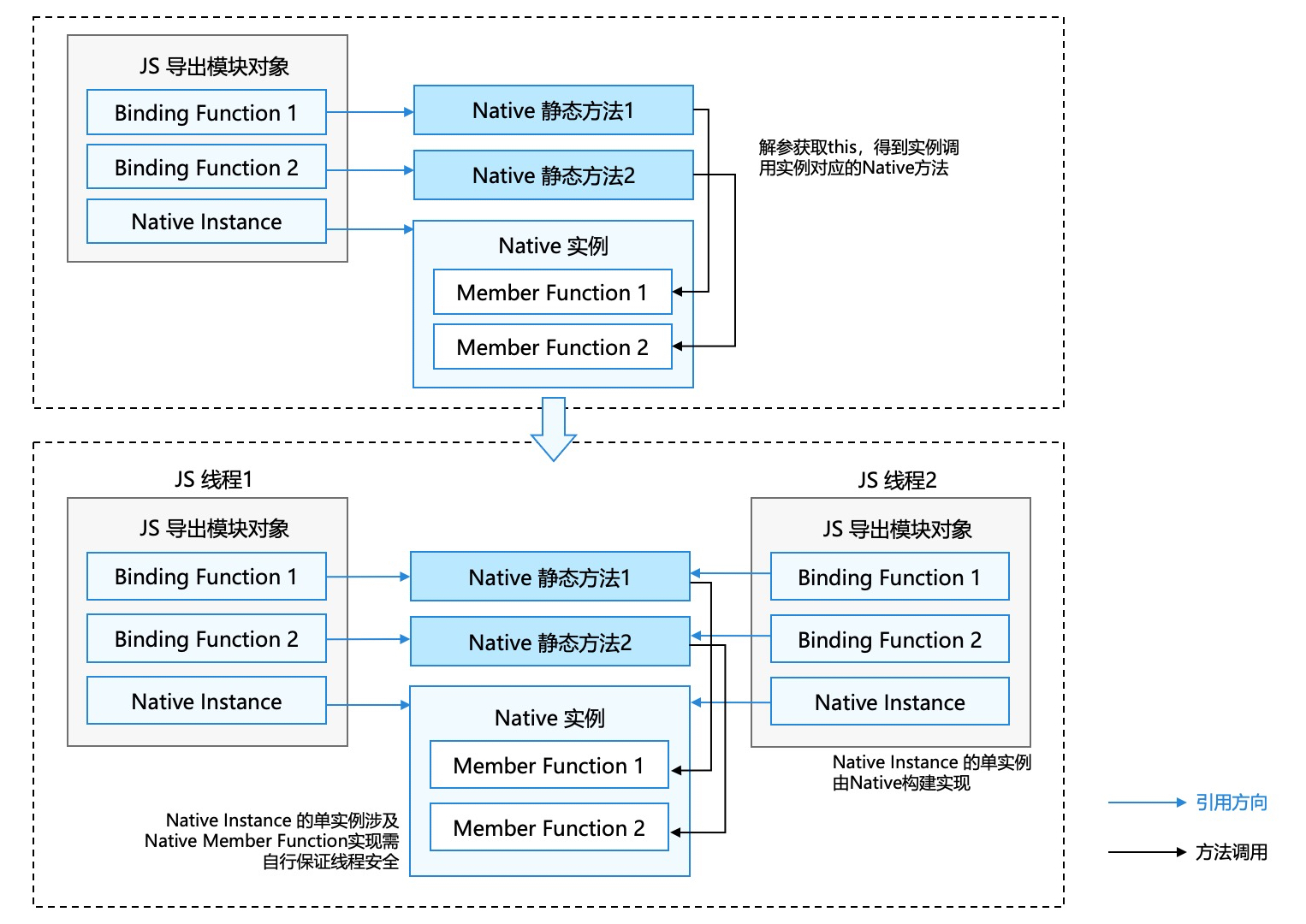
- 业务实现中的关键点
- JS模块对象
模块定义好的导出对象,也就是使用者Import时获得的模块对象。
JS模块对象中的JS Function通过Node-API方法绑定至该模块的Native静态方法,调用时将调用Native静态方法来提供实际功能。
- Native Instance
模块对象的成员对象(ExternalReference),由Native Class的GetCurrentInstance(标准单例实现)获得,进程内同模块都指向同一个Native单例。本设计对原有Native实现中已经提供线程安全的C++类的功能时使用,即该实例的Native成员方法也需进行同步保护。
该模块对象即使有其它JS成员,也类似于”局部变量”,即线程间并不共享。
- Native静态方法
Native静态方法提供对应模块的Native功能实现,通过napi_get_cb_info获取JS Binding Function的this对象,从而通过this获取绑定在JS模块对象上的Native Instance,再调用Native Instance对应的Native成员方法,即可完成对应功能实现。
说明
同上,方法实现不可以进行全局变量的非线程安全操作。
- 生命周期问题
一般模块对象在主线程退出时进行析构。
若精细化控制,可绑定finalizeCallback进行管理,线程对象回收时会在该线程调用析构方法。
- JS模块对象
- 案例参考
// napi_init.cpp class Singleton { public: static Singleton &GetInstance() { static Singleton instance; return instance; } static napi_value GetAddress(napi_env env, napi_callback_info info) { uint64_t addressVal = reinterpret_cast<uint64_t>(&GetInstance()); napi_value napiAddress = nullptr; napi_create_bigint_uint64(env, addressVal, &napiAddress); return napiAddress; } static napi_value GetSetSize(napi_env env, napi_callback_info info) { std::lock_guard<std::mutex> lock(Singleton::GetInstance().numberSetMutex_); uint32_t setSize = Singleton::GetInstance().numberSet_.size(); napi_value napiSize = nullptr; napi_create_uint32(env, setSize, &napiSize); return napiSize; } static napi_value Store(napi_env env, napi_callback_info info) { size_t argc = 1; napi_value args[1] = {nullptr}; napi_get_cb_info(env, info, &argc, args, nullptr, nullptr); if (argc != 1) { napi_throw_error(env, "ERROR: ", "store args number must be one"); return nullptr; } napi_valuetype type = napi_undefined; napi_typeof(env, args[0], &type); if (type != napi_number) { napi_throw_error(env, "ERROR: ", "store args is not number"); return nullptr; } std::lock_guard<std::mutex> lock(Singleton::GetInstance().numberSetMutex_); uint32_t value = 0; napi_get_value_uint32(env, args[0], &value); Singleton::GetInstance().numberSet_.insert(value); return nullptr; } private: Singleton() {} // 私有构造函数,防止外部实例化对象 Singleton(const Singleton &) = delete; // 禁止拷贝构造函数 Singleton &operator=(const Singleton &) = delete; // 禁止赋值运算符 public: std::unordered_set<uint32_t> numberSet_{}; std::mutex numberSetMutex_{}; }; // Index.ets import singleton from 'libentry.so'; import { taskpool } from '@kit.ArkTS'; @Concurrent function getAddress() { let address = singleton.getAddress(); console.info("taskpool:: address is " + address); } @Concurrent function store(a: number, b: number, c: number) { let size = singleton.getSetSize(); console.info("set size is " + size + " before store"); singleton.store(a); singleton.store(b); singleton.store(c); size = singleton.getSetSize(); console.info("set size is " + size + " after store"); } @Entry @Component struct Index { build() { Row() { Column() { Button("TestSingleton").onClick(() => { let address = singleton.getAddress(); console.info("host thread address is " + address); let task1 = new taskpool.Task(getAddress); taskpool.execute(task1); let task2 = new taskpool.Task(store, 1, 2, 3); taskpool.execute(task2); let task3 = new taskpool.Task(store, 4, 5, 6); taskpool.execute(task3); }) } .width('100%') } .height('100%') } } - 实现方案介绍(方案二)
步骤一:采用ArkTS原生对象,定义Sendable类的单例,封装成共享模块(进程内共享),子线程进行初始化;
步骤二:初始化完成通知主线程,主线程导入使用该单例对象。
- 业务实现中的关键点
Sendable类需要满足一定的约束,可参考@Sendable类装饰器说明。
- 案例参考
// Demo.ets @Sendable export class Demo { private static instance: Demo; private constructor() { } public static getInstance(): Demo { if (!Demo.instance) { Demo.instance = new Demo(); } return Demo.instance; } public init(): void { // 初始化逻辑 } }// xxx.ets import { Demo } from './demo'; import { taskpool } from '@kit.ArkTS'; @Concurrent function initSingleton(): void { let demo = Demo.getInstance(); demo.init(); // 通知主线程初始化完成 } async function executeTaskPool(): Promise<void> { let task = new taskpool.Task(initSingleton); await taskpool.execute(task); } executeTaskPool(); - 与业界方案特殊差异说明
Java存在ClassLoader机制,所有类型是静态且唯一的,因此可以很方便的导入类,支持单例模式。而HarmonyOS APP开发时需要借助共享模块,保证类只加载一次,保证唯一性。
线程间不可变数据共享
- 场景描述
定义为Sendable类型的对象在发送到其他TS线程后可被多线程读写,开发者需要通过异步锁机制进行管理。需要一种能力保障对象的数据被多线程访问时准确,要么通过锁机制要么使对象变成只读对象。
常见的业务场景如下所示:
常见业务场景
具体业务描述
全局环境变量共享
应用启动时生成一些资源加载入口、配置参数、全局变量等不需要更新的变量,可通过冻结能力冻结后共享到多个ArkTS子线程
一次性产物不可变共享
业务阶段性产生的页面布局数据,这个数据是在工作线程生成的,传输并缓存在UI线程后不会修改,可能会多次作为UI渲染的输入使用
- 实现方案介绍
通过冻结API,使共享对象变成只读对象。实现方案介绍:
步骤一:业务逻辑定义、生成需要的Sendable对象;
步骤二:发送到其他ArkTS线程前通过Object.Freeze API冻结该对象;
步骤三:通过taskpool或worker的消息通信机制将该对象共享到其他ArkTS线程。
- 业务实现中的关键
冻结后对象不可修改,如果修改会抛出ArkTS异常。
- 案例参考
以全局环境变量共享为例:
// xxx.ets import { worker } from '@kit.ArkTS'; import { freezeObj } from './freezeObj'; @Sendable export class GlobalConfig { // 一些配置属性与方法 init() { // 初始化相关逻辑 freezeObj(this) // 初始化完成后冻结当前对象 } } let globalConfig = new GlobalConfig(); globalConfig.init(); const workerInstance = new worker.ThreadWorker('entry/ets/workers/Worker.ets`', { name: 'Worker1' }); workerInstance.postMessage(globalConfig);// worker文件路径为:entry/ets/workers/Worker.ets // Worker.ets import { MessageEvents, ThreadWorkerGlobalScope, worker } from '@kit.ArkTS'; import { GlobalConfig } from '../pages/InterthreadCommunication4'; const workerPort: ThreadWorkerGlobalScope = worker.workerPort; workerPort.onmessage = (e: MessageEvents) => { let globalConfig: GlobalConfig = e.data; // 使用globalConfig对象 }// freezeObj.ts export function freezeObj(obj: any) { Object.freeze(obj); } - 与业界方案特殊差异说明
内存共享模型如JAVA/C++对象在不同线程间都是可见的,sendable对象(共享)需要将对象引用发送到其他线程才可使用。
生产者与消费者模式
- 场景描述
生产者与消费者模式表现为以下几个特征:
1. 有复数或单数个生产者并发地生产数据;
2. 有复数或单数个消费者并发地消费数据;
3. 存在一个数据缓存区,生产者生产出的数据存储在缓存区,消费者从缓存区中取数据,当缓存区满的时候要通知生产者停止生产,当缓存区为空时通知消费者休眠直到生产者添加数据。
常见的业务场景如下所示:
常见业务场景
具体业务描述
场景类型
阅读应用页面预加载
用户每次翻页或跳转后需要预加载复数张前后页,将前后页的加载请求缓存到一个加载队列中,将队列中的页面布局解析任务并发地执行
CPU密集型 + IO密集型
本地文件上传
用户在主线程一次上传单个或复数个文件,上传文件的请求被储存在一个上传队列中,并发地将队列中的文件上传到云端
CPU密集型+ IO密集型
- 实现方案介绍
以阅读应用场景为例:
步骤一:用户一次翻页产生复数个前后页预加载的请求;
步骤二:通过网络接口从云端下载复数页面的原始数据;
步骤三:通过taskpool并发地解析每一页的页面原始数据生成page对象,page对象描述了页面的布局信息和每个组成部分;
步骤四:taskpool执行的结果返回到UI线程的缓存队列中;
步骤五:缓存队列中的页面数据中临近用户当前页的page对象执行渲染任务。
- 业务实现中的关键
- 如果Page对象回到主线程只需要使用其中的数据可以考虑通过序列化在线程间传递,如果Page对象引用了复数个自定义类型的对象,为了将其完整地返回UI线程需要将其定义为Sendable类型的对象。
- 如果页面原始数据是TS线程间共享的,可以在UI线程执行下载任务(异步并发不阻塞UI线程),如果不是需要在taskpool工作线程中执行下载,避免线程间传递的耗时。
- 如果是对时延敏感的场景不建议使用并发模块处理相关逻辑,并发功能可以将负载从UI线程转移到工作线程但是会增加时延(并发不排队时大约500us)。
- 与业界方案特殊差异说明
1. 内存共享模型如JAVA/C++对象在不同线程间都是可见的,ArkTS是线程间内存隔离的内存模型对象在不同线程间使用需要序列化(拷贝),sendable对象(共享)需要将对象引用发送到其他线程才可使用。
2. sendable对象存在较多约束,尽量只将必须共享的对象定义为sendable对象,由普通的ArkTS对象持有sendable对象并将整个流程串起来。















 1954
1954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









