







阿里妹导读:IFTTT是一个被称为 “网络自动化神器” 的创新型互联网服务理念,它既实用,概念又简单,可以通过标准化协议满足用户的强需求,让各种互联网产品为用户服务,2010年刚推出,就拥有了极高的热度。闲鱼 IFTTT 是基于闲鱼的业务场景与 IFTTT 理念结合后产生的,上线以来,它提供了买卖双方实时双向互动能力,平均每天处理关系数据数亿条,点击率翻倍,给团队注入了新能量。今天就由闲鱼技术的工程师剑辛,为大家揭晓这个系统。
面临问题
在闲鱼生态里,用户之间会有很多种关系。其中大部分关系是由买家触发,联系到卖家,比如买家通过搜索、收藏、聊天等动作与卖家产生联系;另外一部分是平台与用户之间的关系。对这些关系分析之后我们发现这些关系中存在两个问题:
用户产生关系的层次不够丰富;现有系统只维护了一部分用户关系,包括收藏、点赞等,用户关系的层次还不够丰富。
用户之间关系是单向且不够实时;在现有的玩法中,买家可以通过多种行为与卖家产生联系,但卖家不能主动与买家发生关系和互动;而且平台计算的关系都是离线的,对用户的吸引力不足。
上面提到的场景经过抽象归纳之后都是同一个范式:当某个条件被满足之后,就会触发相对应的动作。这个范式是 IFTTT 的基本理念,而闲鱼 IFTTT 就是对这些问题的解决方案。
IFTTT概念
IFTTT是一个被称为 “网络自动化神器” 的创新型互联网服务理念,它很实用而且概念很简单。IFTTT全称是 *If this then that *,意思是如果满足“this”条件,则触发执行“that”动作。IFTTT由三部分构成,分别为Trigger、Action和Recipe。

可以看出 IFTTT 本身概念并不复杂,它的真正魔力在于“由简单组成的复杂”,也就是由众多简单的 IFTTT 流程相互衔接成跨越整个互联网、跨越多平台、跨越多设备的状态机。
闲鱼 IFTTT 是基于闲鱼的业务场景与 IFTTT 理念结合后产生的,提供 IFTTT 标准协议封装,对业务无侵入可扩展的服务编排系统。
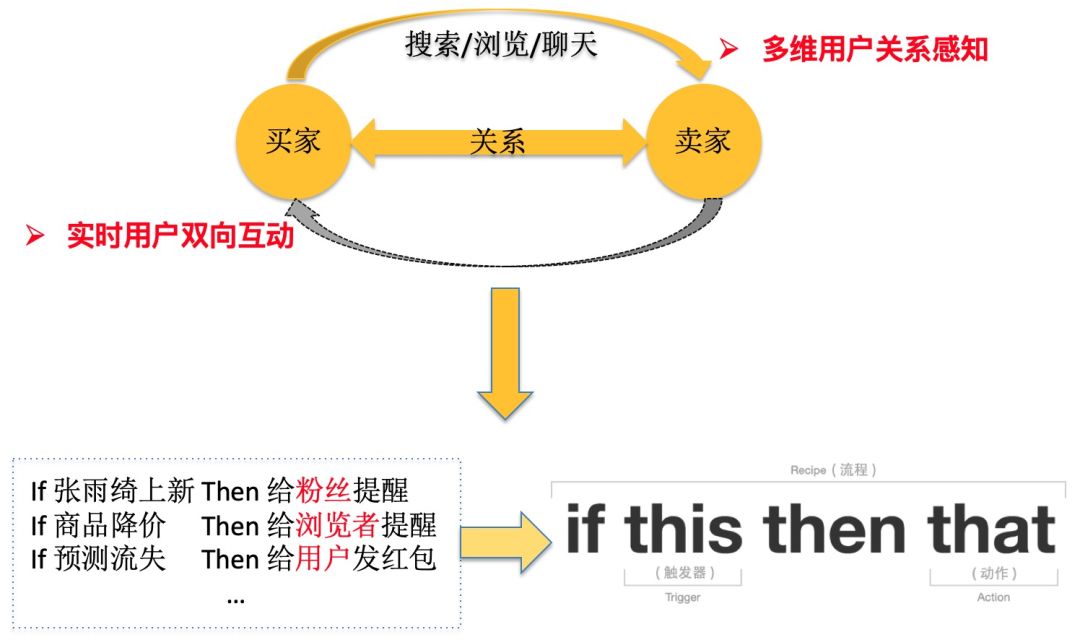
闲鱼 IFTTT 的两个特性对应上述两个问题,分别是:
多维用户关系感知
多维指的是覆盖面,闲鱼 IFTTT 通过更多维度的挖掘,抽象并维护了更丰富的用户关系。基于用户关系数据,我们可以产出用户画像,并通过更有效的方式触达用户。
实时用户双向互动
闲鱼 IFTTT 底层具有对用户关系大数据的高效存储和处理能力,以支持上层业务中用户关系实时处理;闲鱼 IFTTT 不仅支持买家到卖家关系,而且通过设计天生支持卖家到买家关系。
闲鱼 IFTTT 把之前平台与用户的互动、买家到卖家的联系,切换称闲鱼用户之间天然的关系互动,对用户骚扰更少且激活拉回的效果更好,我们基于这个场景设计闲鱼 IFTTT 的技术方案。
技术方案
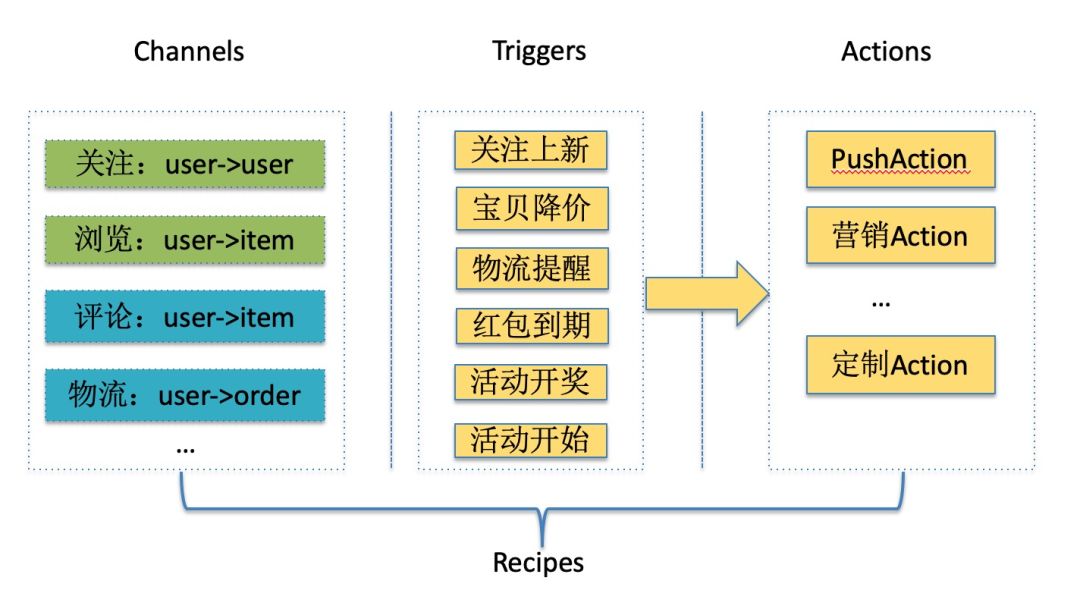
先按照 IFTTT 规范对业务进行建模,分为Channel、Trigger和Action层,其中 Channel 层是数据底层,将 Trigger 和 Action 关联后组成标准Recipe。
Channel Channel层在闲鱼 IFTTT 的作用是保存和管理用户关系数据,Channel层定义了用户关系的元数据结构,包括关系类型、源账户和目标账户。Channel层是闲鱼 IFTTT 的基石,Trigger和Action均基于用户关系数据进一步抽象业务逻辑。
Trigger Trigger是业务上自定义的触发事件,与业务息息相关,可能是关注的人上新、浏览宝贝降价或者是参加的百币夺宝活动开奖等。当 Trigger 触发后,闲鱼 IFTTT 会根据 Trigger 类型和配置的关系类型计算用户名单,并调用Action层进行处理。
Action Action层处理对象是Trigger触发后计算的用户名单,可以给名单里的用户发Push,发权益或者其他定制逻辑。Action本身是标准化、可插拔的组件,业务上可以利用 Action 组件对用户名单做AB测试,快速实验不同 Action 策略。
接下来我们说一下闲鱼 IFTTT 详细技术方案,方案如下:
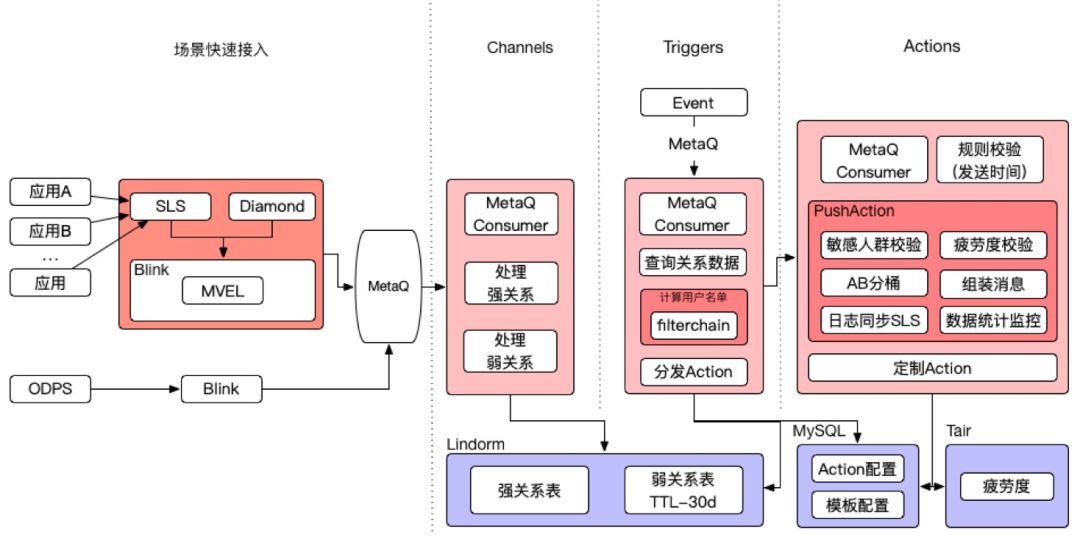
整体技术方案按照业务建模的结构图细化,补充依赖的技术组件。整体流程不再细述,针对流程中重点模块详细说明。
场景快速接入
设计场景快速接入的目的是让业务对接入闲鱼 IFTTT 无感知,因为在最开始的设计中,场景接入是准备通过在业务逻辑里增加AOP切面,将业务数据和场景上报。但因为这种方式对业务本身有一定侵入,增加业务执行的RT而且不够灵活,最终被否决。
而现在的场景快速接入方案解决了这些问题,通过SLS接入所有应用的海量网络请求日志,记录请求的URL、参数和响应;将 SLS 作为 Blink 流计算任务的数据源;根据 diamond 动态下发的规则实时筛选网络请求URL和参数,把数据按照指定格式组装后上报给 Channel 层。
场景快速接入方案将业务逻辑与场景接入解耦,支持快速接入,灵活变更且延迟低,是针对大数据场景接入的高性能解决方案。
计算用户名单
计算用户名单模块采用责任链模式设计,因为在不同 Trigger 场景中,业务对用户名单的计算和筛选逻辑都是不同的。通过责任链模式,将主流程与业务筛选逻辑解耦,并支持各业务灵活定制筛选逻辑,互不干扰。
PushAction
Action层是闲鱼 IFTTT 中最重要的一环,会直接触达到用户,Action的逻辑会直接影响用户对平台的直观感受和活跃率。消息 Push 是 Action 中最常见的逻辑,更要防止用户被骚扰,PushAction逻辑如下:
敏感人群过滤;
疲劳度校验;
对发送人群进行AB实验;
组装消息;
将Action各节点日志同步到SLS,方便检索和排查问题;
统计消息发送数据及点击数据,为业务后续决策提供依据;
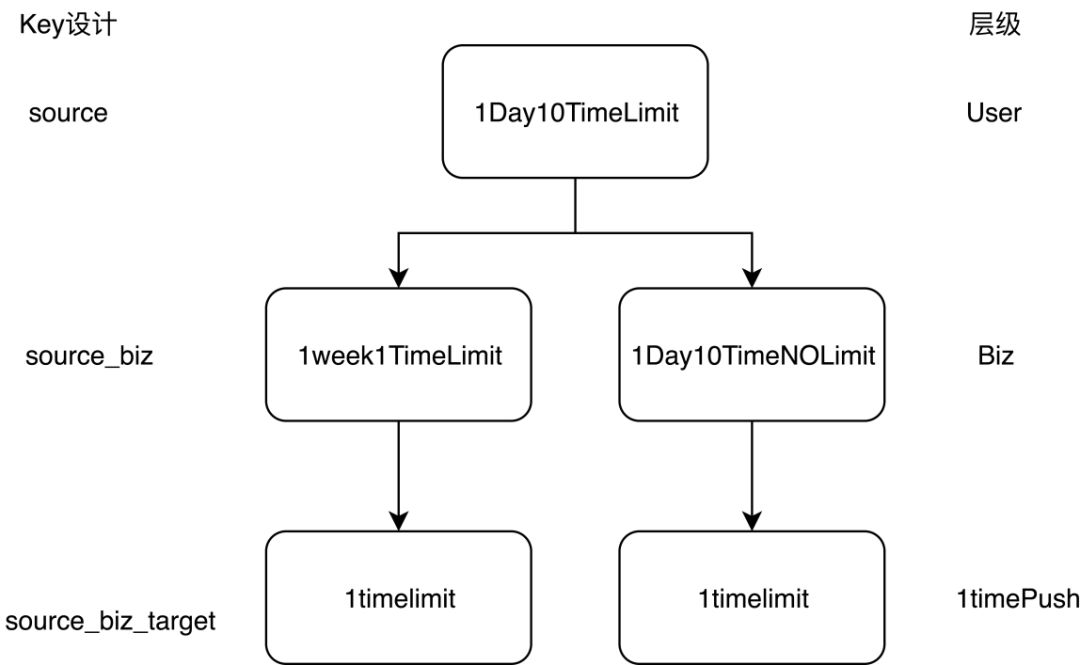
其中,疲劳度是防止用户被骚扰的关键,我们针对疲劳度进行了分层设计,分为三层,第一层为用户级别疲劳度,控制一个用户在一个周期内收到消息数量;第二层是业务维度,控制用户在一个周期内收到某个业务的消息数量;第三层是目标级别,控制用户在一个周期内收到同一个发送者消息数量。
在业务维度层面,支持灵活控制多个业务联合疲劳度,保证用户不会被消息过度骚扰。
用户关系存储
用户关系数据是闲鱼 IFTTT 的基石,它的特点是存储量级大,达到TB级别;而且对存储和查询的性能要求高,TPS和QPS的峰值都在一万以上。经过调研,我们发现集团内部开发的 Lindorm 可以满足需求。
Lindorm是阿里内部基于 Hbase 自研的高性能KV存储数据库,对Hbase的性能和稳定性均有一定优化。闲鱼 IFTTT 采用 Lindorm 作为用户关系数据存储,经性能测试验证数据读取 QPS 达到7万,数据存储TPS在10万以上。Lindorm本身性能优异,为闲鱼IFTTT高性能奠定基础。
效果
闲鱼IFTTT自上线以来,已支持关注上新、浏览宝贝降价和租房小区上新等多个业务场景,提供买卖双方实时双向互动能力,平均每天处理关系数据数亿条,处理Trigger量达到上千万,处理 Action 量达到亿级别,消息点击率较离线push提高1倍以上。
闲鱼 IFTTT 目前支持的是用户互动场景,后续我们将结合闲鱼自身业务特点,对 IFTTT 进行更高维度抽象,封装标准 Recipe 接口,将闲鱼IFTTT打造成提供流程编排、管理能力的服务平台。
在我看来,IFTTT从2010年推出以来,在国外有很大的热度,在互联网和物联网领域都有专门的公司和团队在研发,IFTTT的概念虽然简单,却通过标准化协议满足用户的强需求——让各种互联网产品为用户服务。这其实也给我们互联网从业者一些思考:在新机遇面前,究竟是快速投入比较重要还是抽象标准协议解决一类问题更加有效?
名词注解
SLS:https://cn.aliyun.com/product/sls
Diamond:阿里内部研发的持久配置管理中间件;
Blink:https://data.aliyun.com/product/sc?spm=5176.10695662.1131226.1.bf495006EWuVAB
MetaQ:阿里内部研发的分布式、队列模型的消息中间件;
Lindorm:阿里内部基于HBase研发的新一代分布式NoSQL数据库,阿里云类似产品:https://www.aliyun.com/product/ots?spm=a2c4g.11174283.cwnn_jpze.59.2f5a15c3NH30me;
Tair:阿里内部研发的高性能、分布式、可扩展、高可靠的Key-Value结构存储系统;
阿里云开发者峰会分享了开源大数据、IT 基础设施云化、数据库、云原生、物联网等领域的技术干货。点击↓↓下方按钮,下载演讲 PPT。


你可能还喜欢
点击下方图片即可阅读

平头哥广发英雄帖,公开首款CPU“玄铁”仿真代码

阿里云亮出四张“王牌”,平头哥首次交货!

将 IPv6 照进现实,我们需要做些什么?

关注「阿里技术」
把握前沿技术脉搏


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









