






1. DPDK中的环形数据结构
DPDK中的环形结构经常用于队列管理,因此又称为环形队列。它不同于大小可灵活变化的链表,它的空间大小是固定的。
DPDK中的rte_ring拥有如下特性:
它是一种FIFO(First In First Out)类型的数据结构;
无锁;
多消费者、单消费者出队;
多生产者、单生产者入队;
批量出队;
批量入队;
全部出队;
全部入队;
rte_ring环形队列与基于链表的队列相比,拥有如下优点:
速度更快,效率更高;
rte_ring只需要一个CAS指令,而普通的链表队列则需要多个双重CAS指令
相对于普通无锁队列,实现更加简洁高效
支持批量入队和出队;
批量出队并不会像链氏队列一样,产生很多的Cache Miss
此外批量出队和单独出队在花费上相差无几
rte_ring环形队列与基于链表的队列相比,缺点如下:
rte_ring环形队列大小固定;
rte_ring需要提前开辟空间,在未使用的情况下更容易造成内存的浪费;
rte_ring的应用场景主要包括两类:
DPDK应用之间进行通讯
内存池分配
rte_ring环形队列描述:
环形队列可以简单的用下图来描述:
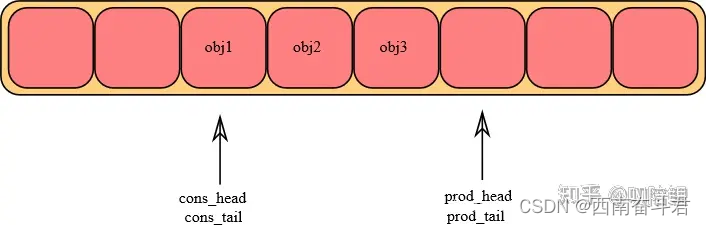
DKDP源码中的环形队列数据结构如下:
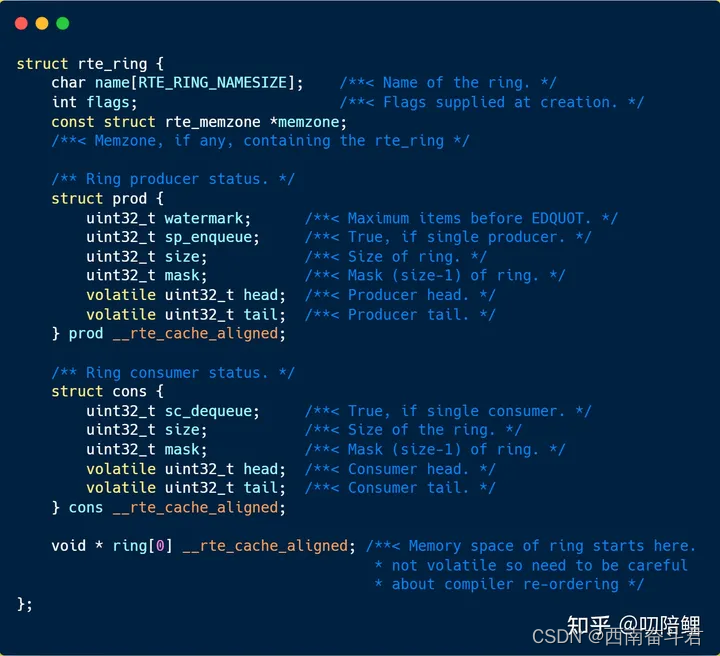
每一个环形数据结构都包含两对(head,tail)指针:一对用于生产者(prod),另一队用于消费者(cons)。文章后面通过prod_head, prod_tail, cons_head, cons_tail来分别表示这四个指针。
head,tail的范围都是0~2^32;,它恰恰是利用了unsigned int 溢出的性质。
在DPDK实现中,rte_ring是通过**“name”**字段来唯一标识的,我们可以通过rte_ring_create()来创建环形队列,他可以保证创建的队列name的唯一性。
2. 环形队列:单生产者/单消费者模式
本节内容主要为单生产者下的入队操作以及单消费者下的出队操作。
为了方便后续表达和理解,这里有必要统一一下描述:
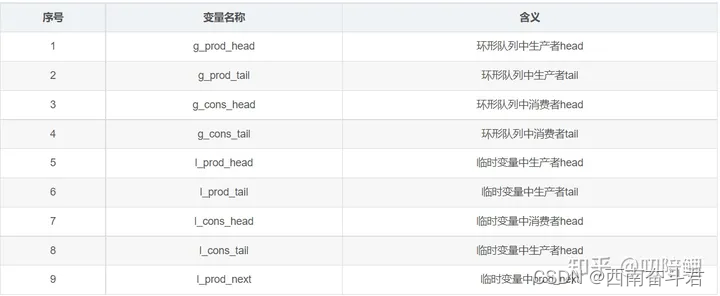
关于临时变量可以这样理解:每一个CPU都有独占cache, 这些临时变量l_xxx_xxx则是相应CPU存储在本地cache中尚未更新到全局环形队列上的值。而g_xxx_xxx则表示存储中的共享的环形队列值。
2.1 生产者–入队
入队操作只会修改生产者的head和tail指针(即prod_head, prod_tail)。在初始状态时,prod_head和prod_tail指向相同的内存空间。
下面举一个例子:只有一个生产者的入队操作。
入队操作第①步
将环形队列的g_prod_head、g_cons_tail存储在临时变量l_prod_head、l_cons_tail中记录位置;临时变量l_prod_next则根据插入对象的个数移动了相应的位置。如果没有足够的空间来执行入队操作,则返回错误。
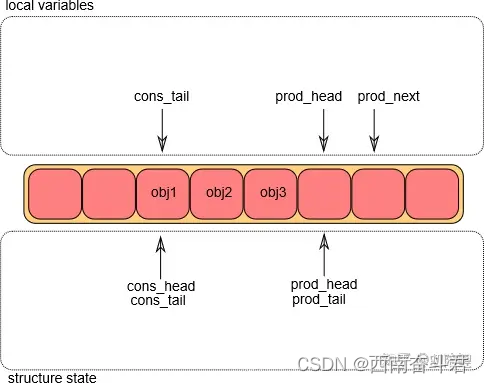
入队操作第②步
将环形队列的g_prod_head移动到l_prod_next的位置;然后将对象添加到环形缓冲区中。
注: l_prod_next:用来提前预定位置,g_prod_head则是真正改变环形队列指针,占用位置生效。
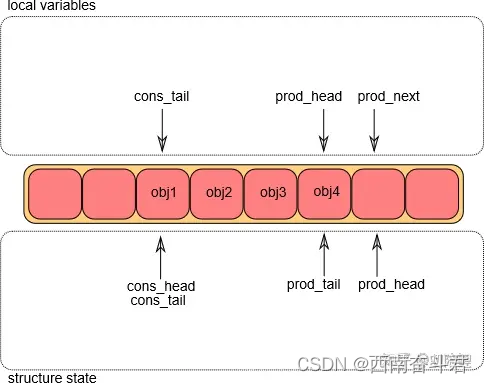
入队操作第③步
一旦对象被添加到环形队列中,g_prod_tail将会被修改,指向g_prod_head的位置。
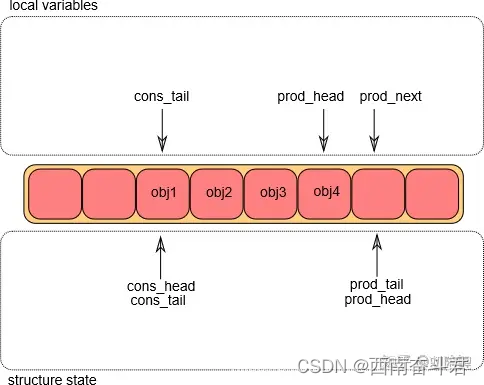
至此,入队操作完成。
说实话,只看到这段描述,是在看不出所以然,以及它的特点。下面我们通过查看源码来加深对入队操作的理解。(文字言简意赅,读不懂;代码深奥,看不懂。O(∩_∩)O哈哈~)
我们依然按照刚才的三步走来说明代码:
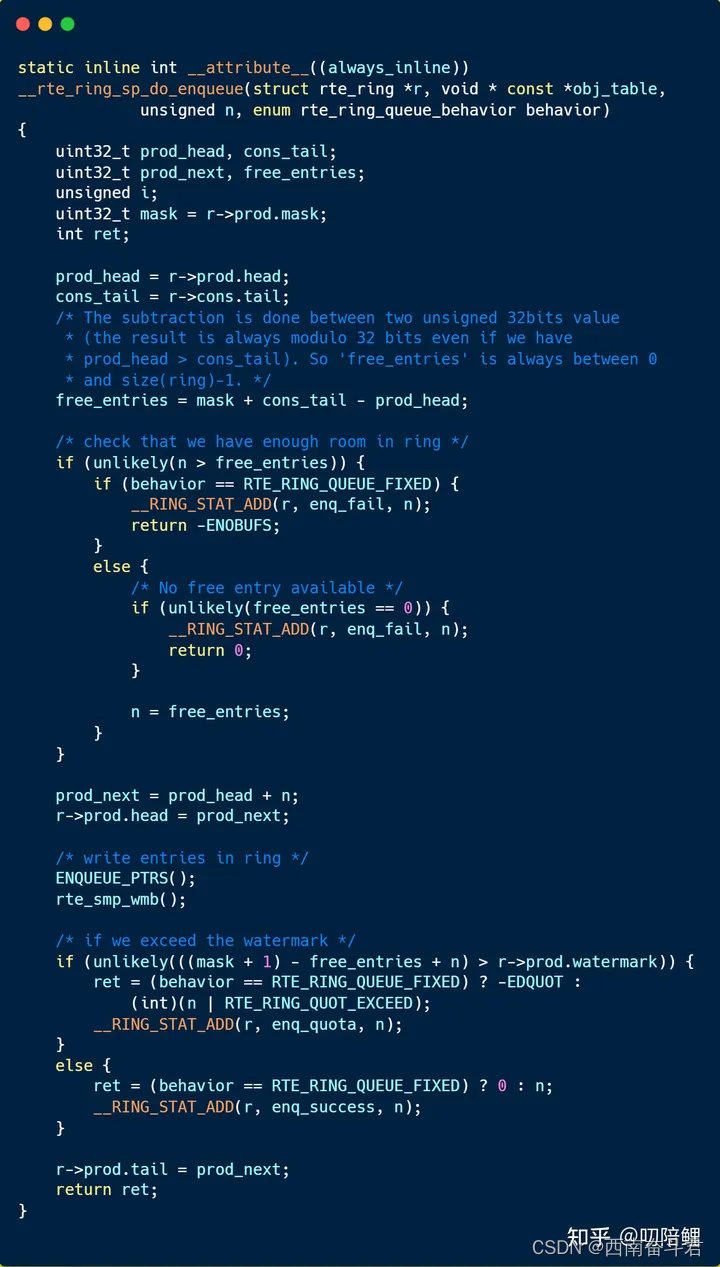
入队操作第①步
第9、10行:用来保存prod_head, cons_tail变量。它的目的嘛,准备开房。
第13~34行,确定丽晶大酒店是否还有剩余房间可供咱们开!(确保环形队列剩余空间足够入队操作,如果空间不足,则提示相应信息并返回错误码)。
第36行:打电话(使用临时变量l_prod_next)预定丽晶大酒店房间的位置。
入队操作第②步
第37行:房间已经预定成功,可以直接开车去订好的房间(l_prod_next)。
第40行:将对象(object)拉进房间中办事
第41行:等事情办完(内存屏障)再走
入队操作第③步
第54行:事情已经办完,对象仍在房间回味呢,我收拾干净移步到下一个房间,继续等待另一个对象(object)的到来。
到此为止,单生产者入队完毕。我特么怀疑我自己讲了一个特别有内涵的段子,我太有才了O(∩_∩)O。
2.2 消费者–出队
本节介绍一个消费者出队操作在环形队列中如何实现的。在这个例子中,只有消费者的head、tail(即cons_head、cons_tail)会被修改。在初始状态时,cons_head和cons_tail指向相同的内存空间。
下面举一个例子:只有一个消费者的出队操作。
出队操作第①步
将环形队列的g_prod_head、g_cons_tail存储在临时变量l_prod_head、l_cons_tail中记录位置;临时变量l_cons_next则根据出队对象的个数移动了相应的位置。如果没有足够的对象来执行出队操作,则返回错误。
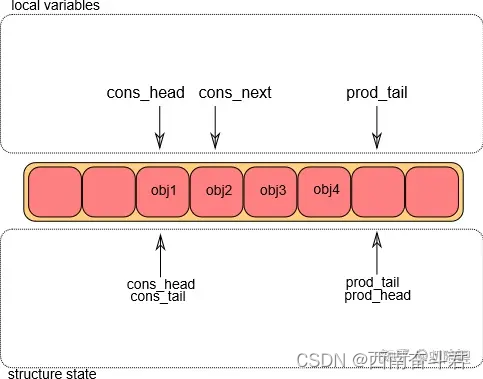
出队操作第②步
将环形队列的g_cons_head移动到l_cons_next的位置;然后将对象添加到环形缓冲区中。
注: l_cons_next:用来提前预定位置,g_cons_head则是真正改变环形队列指针,占用位置生效。
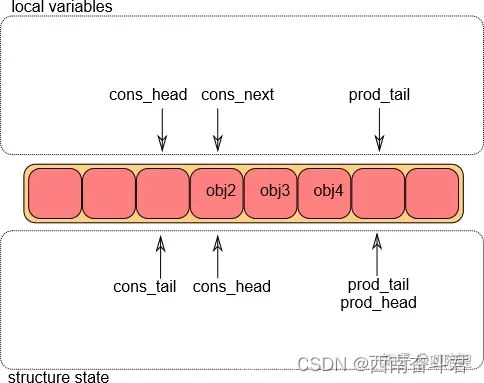
出队操作第③步
出队完成后,g_cons_tail将会被修改,指向g_prod_head的位置。
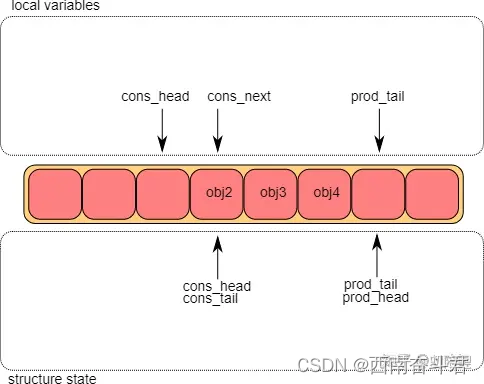
至此,但消费者的出队操作便完成了。
那接下来我们继续讲解我的小段子:

出队操作第①步
第9、10行:用来保存prod_head, cons_tail变量。它的目的嘛,事都办完了,准备退房。
第16~31行,确定丽晶大酒店开了几间房,不能多退(出队个数检查,不得超过缓冲缓冲区中存储的个数)。
第33行:打电话通知前台,准备要退的房间(使用临时变量l_cons_next记录)
出队操作第②步
第34行:上一个房间已退,还好我叫了好几个对象,我可以准备去下一个对象的房间(l_prod_next)。
第37行:上一个房间里的对象收拾好行李,神清气爽、精神饱满、幸福感十足的走出房间。
第38行:等这个对象真的走远,真的走远了才能行动(内存屏蔽)。
出队操作第③步
第41行:确认完毕方才对象真的走了,我开心的进入了下一个对象房间。
到此为止,小故事已经讲完,单消费者出队操作完毕。
3. 环形队列:多生产者/多消费者模式
关于变量命名规则可以参见第2章节。
3.1 多生产者–入队
本节将介绍两个生产者同时执行入队在环形缓冲区是如何操作的。 在这个例子中,只有一个生产者的head、tail(即cons_head、cons_tail)会被修改。在初始状态时,cons_head和cons_tail指向相同的内存空间。
入队操作第①步
在两个CPU上,环形队列的g_prod_head、 g_cons_tail同时被两个核存储在本地临时变量中。并同时将l_prod_next根据入队个数预定位置,并指向预留好的位置后面。
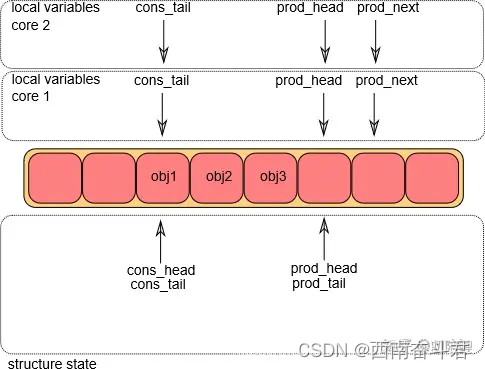
入队操作第②步
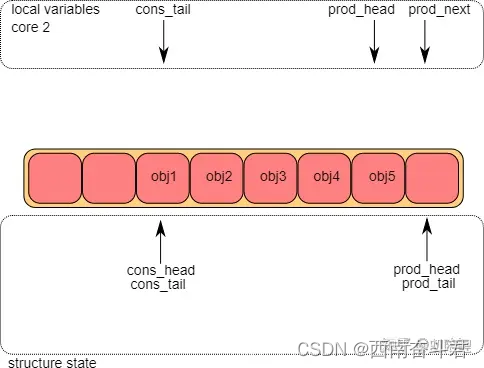
修改g_prod_head指向l_prod_next位置,这部分操作完成后则说明环形队列允许入队操作。该操作是通过CAS指令来完成,它和内存屏蔽是无锁环形队列的核心和关键。这个操作一次只能在其中一个core上完成(假设CPU1上成功执行了CAS操作)。而CPU2跳转到第①步从头开始执行。等CPU2执行完毕第二步时,结果如下图所示
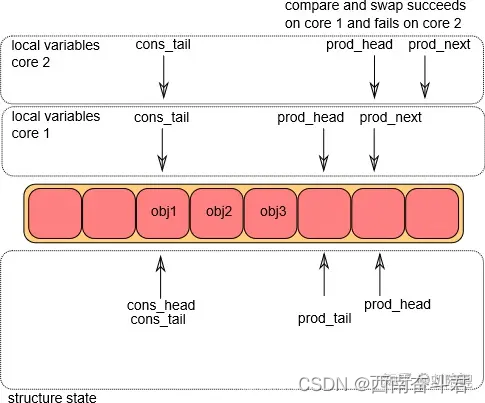
入队操作第③步
CPU2上CAS执行成功,CPU1和CPU2开始进行真正的入队操作,分别将对象添加到队列中。
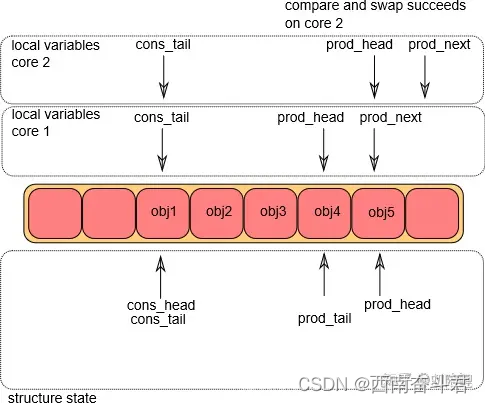
入队操作第④步
两个CPU同时更新prod_head指针,如果g_prod_tail == l_prod_head, 则更新g_prod_tail指针。从上图中我们可以看出,这个操作最初只能在CPU1上执行成功。结果如下:
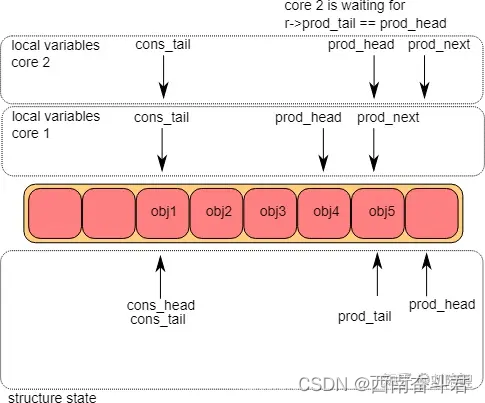
CPU1将g_prod_tail指针进行了更新,此时CPU2上已经满足了g_prod_tail == l_prod_head。
入队操作第⑤步
CPU执行第④步操作,操作成功后,入队操作便执行完毕。
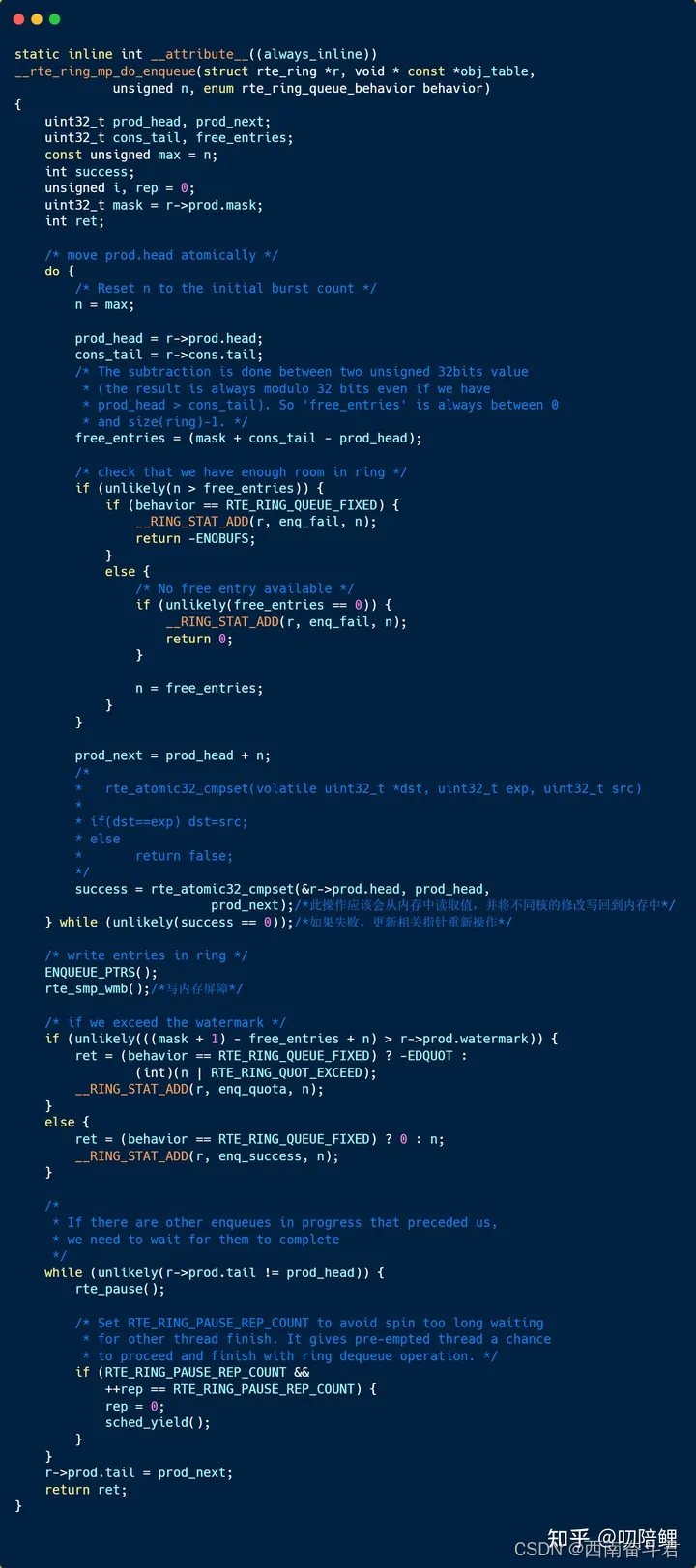
DPDK中的源码实现如下:
3.2 多消费者–出队
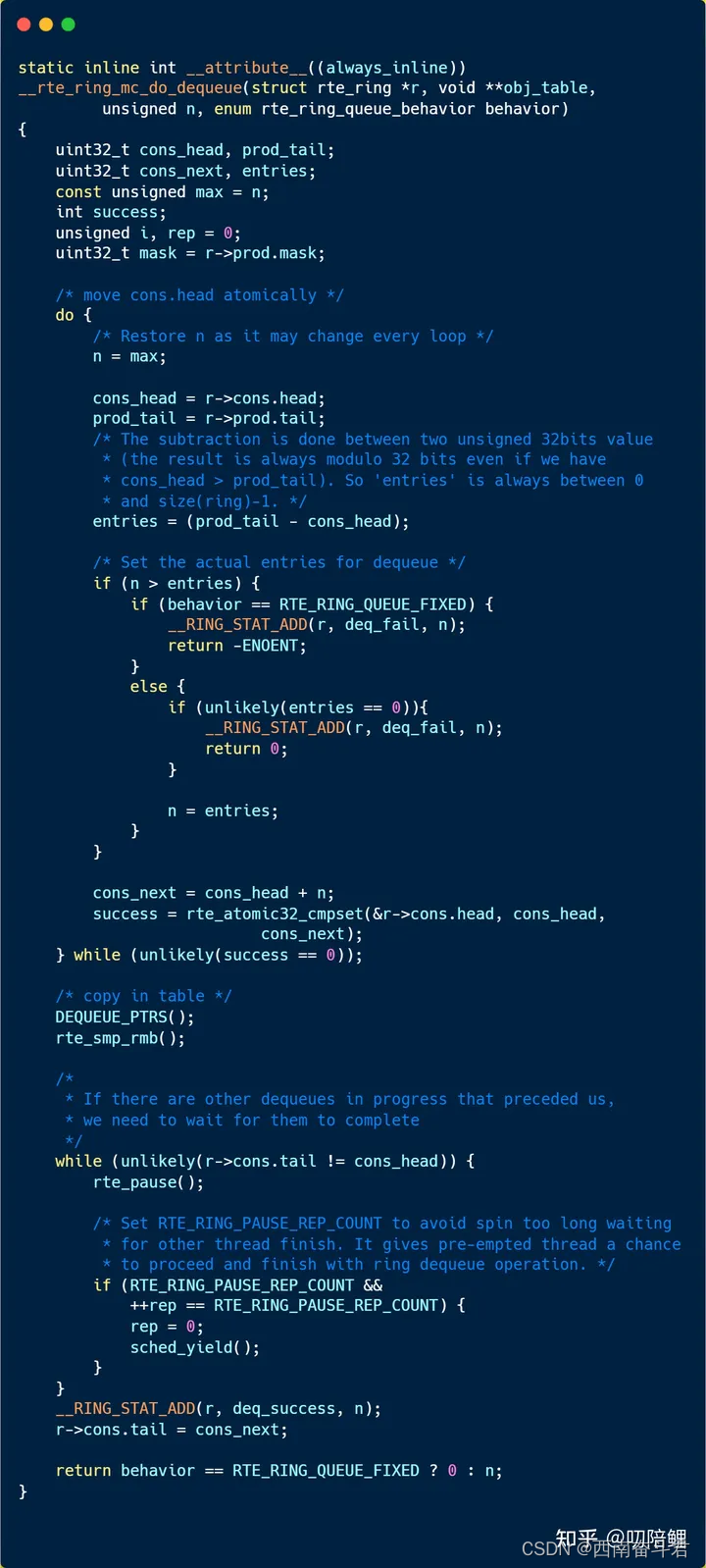
注意
关键要理解 proc 和cons 的head tail 的原理, 假如有3个线程 ,head 是第一个线程执行入队, tail是最后一个线程执行入队, 所以消费者队列 是 proc ->tail - cons->head,是生产者走后一个处理线程 所在位置 减去 消费者第一个线程出队的位置,同理生产者队列也是 cons->tail - proc->head, 保证处于减数并发的最后一个位置 减去 被减数的第一个线程的位置,是没有歧义的队列区间 ,所以 生产者区间 和消费者区间 加和<=队列长度,














 895
895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









