







也可以到我个人博客阅读(点击下面阅读原文即可) https://www.iteblog.com/archives/2556.html
让分布式系统的操作变得简单,在某种程度上是一种艺术,通常这种实现都是从大量的实践中总结得到的。Apache Kafka 的受欢迎程度在很大程度上归功于其设计和操作简单性。随着社区添加更多功能,开发者们会回过头来重新思考简化复杂行为的方法。
Apache Kafka 中一个更细微的功能是它的复制协议(replication protocol)。对于单个集群上不同大小的工作负载,调整 Kafka replication 以让它适用不同情况在今天来看是有点棘手的。使这点特别困难的挑战之一是如何防止副本从同步副本列表(也称为ISR)加入和退出。从用户的角度来看,这意味着如果生产者(producer )发送一批“足够大”的消息,那么这可能会导致 Kafka brokers 发出多个警报。这些警报表明某些主题“未被复制”(under replicated),这意味着数据未被复制到足够多的 brokers 上,从而增加数据丢失的可能性。因此,Kafka cluster 密切监控“未复制的”分区总数非常重要。在这篇文章中,我将讨论导致这种行为的根本原因以及我们如何解决这个问题。
一分钟了解 Kafka 复制机制
Kafka 主题中的每个分区都有一个预写日志(write-ahead log),我们写入 Kafka 的消息就存储在这里面。这里面的每条消息都有一个唯一的偏移量,用于标识它在当前分区日志中的位置。如下图所示:
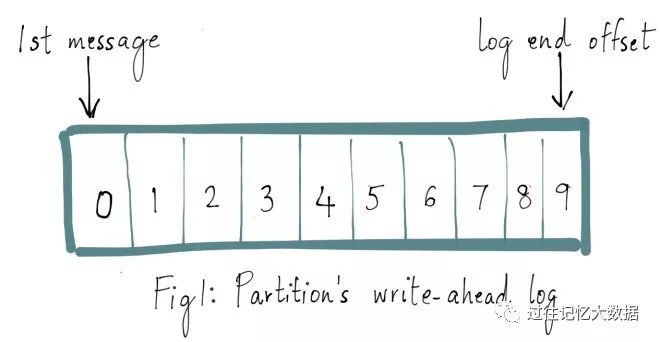
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
Kafka 中的每个主题分区都被复制了 n 次,其中的 n 是主题的复制因子(replication factor)。这允许 Kafka 在集群服务器发生故障时自动切换到这些副本,以便在出现故障时消息仍然可用。Kafka 的复制是以分区为粒度的,分区的预写日志被复制到 n 个服务器。 在 n 个副本中,一个副本作为 leader,其他副本成为 followers。顾名思义,producer 只能往 leader 分区上写数据(读也只能从 leader 分区上进行),followers 只按顺序从 leader 上复制日志。
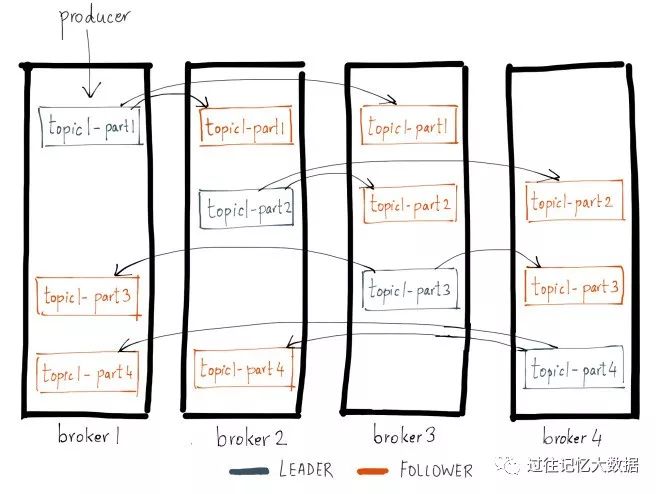
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoop
日志复制算法(log replication algorithm)必须提供的基本保证是,如果它告诉客户端消息已被提交,而当前 leader 出现故障,新选出的 leader 也必须具有该消息。在出现故障时,Kafka 会从挂掉 leader 的 ISR 里面选择一个 follower 作为这个分区新的 leader ;换句话说,是因为这个 follower 是跟上 leader 写进度的。
每个分区的 leader 会维护一个 in-sync replica(同步副本列表,又称 ISR)。当 producer 往 broker 发送消息,消息先写入到对应 leader 分区上,然后复制到这个分区的所有副本中。只有将
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1221
1221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









