






-
js混淆了解
-eval混淆
1.小工具eval还原 (不能调试)
2.找到js调用eval之前的js栈(请求中initiator),再进一步找到eval还原后的js(VM0000) -
字体反爬了解
-
布隆过滤器(hash函数)
-
http请求和响应
-
HTTP八种请求方式,URL组成
-
HTTP和HTTPS的区别
-
tcp/ip四层模型
-
增量爬取,三个位置
-
函数装饰器
-
单例模式
-
类装饰器
-
如果我们在一个类中定义了__call__方法,那么这个类对象将变得可调用。
-
线程和进程
-
全局解释器锁
-
协程-链接
-
HTTPS的请求过程-链接
-
数据库MySQL,mongo,Redis简单了解
-
gunicorn和nginx部署项目
-
快排
-
二分查找
-
selenium检测问题
1.检测网站全绿
2.开发者模式
3.网站js找到检测字段
4.文章链接 -
Twisted框架简单了解
-
Twisted是一个事件驱动型的网络引擎。这里程序的执行流由外部事件来决定。它的特点是包含一个事件循环,当外部事件发生时使用回调机制来触发相应的处理。
-
flask框架简单了解
-
Flask是一个轻量级的web框架,比其它框架(django)更轻便,更具有扩展性(扩展组件)和定制性。Flask主要包括Werkzeug和Jinja2两个核心。Werkzeug负责路由分发和wsig协议转化。Jinja2负责模板渲染。
-
迭代器和生成器–不重要
-
filter 和 map --不重要
类装饰器
- 如果我们在一个类中定义了__call__方法,那么这个类对象将变得可调用。
http请求和响应
请求包括以下格式:请求行、请求头部、空行、请求数据
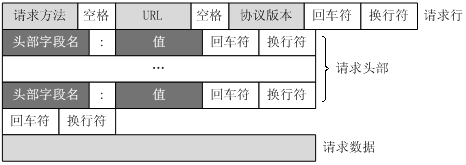
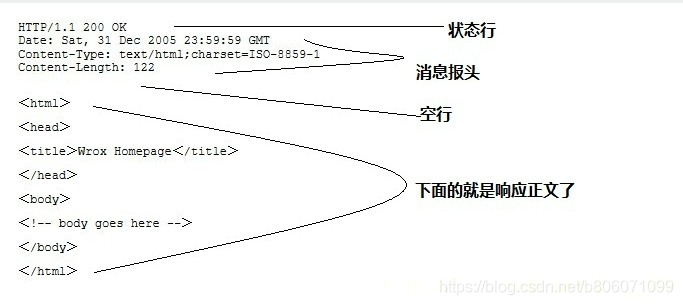
HTTP响应也由四个部分组成,分别是: 状态行、消息报头、空行、响应正文
数据库默认端口
MySQL:3306
MongoDB:27017
Redis:6379
HTTP和HTTPS
- HTTPS需要申请ca证书
- 端口号不同80,443
- HTTP是超文本传输协议,明文传输,HTTPS是ssl加密传输
- HTTPS多了一层SSL协议层,更安全
TCP/IP四层模型协议
链路层(以太网),网络层(IP),传输层(TCP),应用层(HTTP)
应用层:应用层是在用户空间实现的,负责处理众多业务逻辑,如文件传输、网络管理。
传输层:为应用程序隐藏了数据包跳转的细节,负责数据包的收发、链路超时重连等。
网络层:能够使得不同应用类型的数据在Internet上通畅地传输。
数据链路层:实现网卡接口的网络驱动,以处理数据在以太网等物理媒介上的传输。
进程和线程区别与联系
- 进程是系统资源分配的基本单位,线程是CPU调度的基本单位。
- 进程之间变量不共享,线程之间变量共享。
- 进程资源耗费大,线程资源耗费小。
- 进程稳定,一个进程崩溃不会影响其它进程。而线程有影响。
- 进程处理计算密集型任务,线程处理IO密集任务。
迭代器和生成器
- 迭代器可以被看作是特殊的对象,必须实现__iter__()方法和__next__()方法。iter() 方法返回一个特殊的迭代器对象, next() 方法会返回下一个迭代器对象。
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
x = self.a
self.a += 1
return x
myclass = MyNumbers()
myiter = iter(myclass)
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
# 执行输出结果为:
1
2
3
4
5
- 在 Python 中,使用了 yield 的函数被称为生成器,生成器是特殊的迭代器,也可以for循环和next()取值。
生成器---------------------------
- 列表生成式转换(i for i in range(5)),
- 带有yield的函数,代码执行到yield会暂停,然后把结果返回出去,下次启动生成器next()会在暂停的位置继续往下执行
什么是Redis持久化?Redis有哪几种持久化方式?优缺点是什么?
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
Redis 提供了两种持久化方式:RDB(默认) 和AOF
RDB:数据存储
rdb是Redis DataBase缩写
功能核心函数rdbSave(生成RDB文件)和rdbLoad(从文件加载内存)两个函数
AOF:操作指令存储
Aof是Append-only file缩写
每当执行服务器(定时)任务或者函数时flushAppendOnlyFile 函数都会被调用, 这个函数执行以下两个工作
aof写入保存:
WRITE:根据条件,将 aof_buf 中的缓存写入到 AOF 文件
SAVE:根据条件,调用 fsync 或 fdatasync 函数,将 AOF 文件保存到磁盘中。
存储结构:
内容是redis通讯协议(RESP )格式的命令文本存储。
比较:
1、aof文件比rdb更新频率高,优先使用aof还原数据。
布隆过滤器(推荐)
就是引入了k(k>1)个相互独立的哈希函数,保证在给定的空间、误判率下,完成元素判重的过程。
它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
Bloom-Filter算法的核心思想就是利用多个不同的Hash函数来解决“冲突”。
Hash存在一个冲突(碰撞)的问题,用同一个Hash得到的两个URL的值有可能相同。为了减少冲突,我们可以多引入几个Hash,如果通过其中的一个Hash值我们得出某元素不在集合中,那么该元素肯定不在集合中。只有在所有的Hash函数告诉我们该元素在集合中时,才能确定该元素存在于集合中。这便是Bloom-Filter的基本思想。
Bloom-Filter一般用于在大数据量的集合中判定某元素是否存在。
filter和map
- filter根据func函数返回的True或False,对数组进行过滤。
- map根据func函数计算,得到返回值。
a = [1,2,3,4]
def func(x):
if x % 2 == 0:
return True
else:
return False
c = filter(func, a)
for i in c:
print(i)
# 结果:
2
4
a = [1,2,3,4]
def func(x):
if x % 2 == 0:
return x*x
else:
return x
c = map(func, a)
for i in c:
print(i)
# 结果:
1
4
3
16
scrapy增量爬取 链接
线程和进程
- 进程是 系统资源分配的基本单位, 线程是CPU调度的基本单位。
- 一个进程内至少有一个线程,可以有多个线程。
- 进程处理计算密集型,线程处理I/O密集型。
- 多线程的优点:线程遇到I/O耗时操作,CPU不会等待,会继续执行其他线程的任务,提高了效率。
gunicorn和nginx部署项目
- gunicorn是实现了WSGI协议(协议转换)的web服务器,Gunicorn的优势在于,它使用了pre-fork worker模式,gunicorn在启动时,会在主进程中预先fork出指定数量的worker进程来处理请求,提高服务的性能。
- nginx也是一种web服务器,nginx没有实现WSGI协议。作用是请求缓存和负载均衡。
快排
def quick_sort(li, start, end):
# 分治 一分为二
# start=end ,证明要处理的数据只有一个
# start>end ,证明右边没有数据
if start >= end:
return
# 定义两个游标,分别指向0和末尾位置
left = start
right = end
# 把0位置的数据,认为是中间值
mid = li[left]
while left < right:
# 让右边游标往左移动,目的是找到小于mid的值,放到left游标位置
while left < right and li[right] >= mid:
right -= 1
li[left] = li[right]
# 让左边游标往右移动,目的是找到大于mid的值,放到right游标位置
while left < right and li[left] < mid:
left += 1
li[right] = li[left]
# while结束后,把mid放到中间位置,left=right
li[left] = mid
# 递归处理左边的数据
quick_sort(li, start, left-1)
# 递归处理右边的数据
quick_sort(li, left+1, end)
if __name__ == '__main__':
l = [6,5,4,3,2,1]
# l = 3 [2,1,5,6,5,4]
# [2, 1, 5, 6, 5, 4]
quick_sort(l,0,len(l)-1)
print(l)
# 稳定性:不稳定
# 最优时间复杂度:O(nlogn)
# 最坏时间复杂度:O(n^2)
二分查找
def erfen(alist, start, end, value):
if end >= start:
num = int(start+(end-start)/2)
if alist[num] == value:
return num
elif alist[num] > value:
return erfen(alist, start, num-1, value)
else:
return erfen(alist, num+1, end, value)
else:
return 'not found'
if __name__ == '__main__':
alist = [1,2,3,4,5,6]
a = erfen(alist, 0, len(alist)-1, 50)
print(a)
















 9825
9825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









